最短路径:一文学会Bellman-Ford算法与Yen的改进算法
Bellman-Ford算法是一个经典的最短路径算法。
这个算法的思想很简单,我们先来简单回顾一下。以w(u,v)表示顶点u出发到顶点v的边的权值,以 d[v] 表示当前从起点 s 到顶点 v 的路径权值,我们不断优化d[v],最终使d[v]存放着从起点s到顶点v的最短路径。
那么,如何优化d[v]呢?我们引入松弛函数,并作如下定义:
若存在边 w(u,v),使得:
d[v] > d[u]+w(u,v)
则更新 d[v] 值:
d[v] = d[u] + w(u,v)
所以松弛函数的作用,就是判断是否经过某个顶点,或者说经过某条边,可以缩短起点到终点的路径权值。
有了松弛函数的定义之后,我们通过对路径的不断松弛,来逐渐获取最短路径。Bellman-Ford 算法的执行过程很简单,就是对边集合进行 |V|-1 次迭代松弛。伪代码表示如下:
Relax(V, E, s)for v in V:d[v] = ∞d[s] = 0for i from 1 to |V|-1:for edge (u,v) in E:if d[v] > d[u] + w(u,v):d[v] = d[u] + w(u,v)for edge (u,v) in E:if d[v] > d[u] + w(u,v):report negative weight cycle其中,d[v]代表从起点s到顶点v的当前计算的最短路径,V为顶点集合,E为边集合,w(u,v)为边(u,v)的长度。
Bellman-Ford 算法中共存在 |V| 次对边集合的迭代松弛,边集合的大小为 |E|,所以Bellman-Ford 算法的时间复杂度为 O(|V||E|)。对于稠密图,该复杂度可以表示为O(|V|^3)。
在图中不存在负环路的前提下,Bellman-Ford 算法一定可以得到正确的最短路径。下面我们来分析一下Bellman-Ford 算法的正确性。
从起点s出发,到任一节点v的最短路径,在图中不存在负环的前提下,经过的边数一定不超过|V|-1。我们不妨假设从s到v的最短路径为:s->v1->v2->… ->v。最为极端的情况就是,从s到v的最短路径经过了图中的所有结点。由于我们每次内循环都遍历了图中的每一条边,也就是说,第一次循环一定可以找到正确的d[v1],第二次循环一定可以找到正确的d[v2],以此类推。因为在不存在负环路的前提下,v到s的最短路径至多经过|V|-1条边,所以在至多|V|-1次循环之后,一定能够找到这条路径。
概况地说,若图中存在未确认顶点,则每一次迭代后都会新增加至少一个已确认顶点,即图中某条最短路径长度会至少加一。则要找到从起点出发到各顶点的最短路径权值,极端情况下,图中 |V| 个顶点都在一条最短路径上,且松弛边按照最坏情况下进行,即一次只增加一个已确认顶点,则需要执行的迭代次数为 |V|-1 次;另一种极端情况,松弛边按照最好情况下进行,则需要执行的迭代次数为 1 次。
特殊地,如果在|V|-1次循环之后点v还能继续松弛,那么从s到v的最短路径比|V|-1还要长,那么其中必须有个负环路。
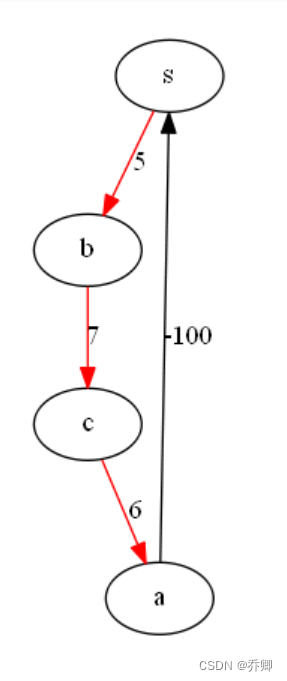
我们使用上图中的例子,具体看一下算法流程。算法流程如下:
如果我们选择边的顺序为:(a,s), (c,a), (b,c), (s,b)
初始化:d[s]=0, d[b]=∞, d[c]= ∞, d[a]= ∞
第一次循环:d[s]=0, d[b]=5, d[c]= ∞, d[a]= ∞
第二次循环:d[s]=0, d[b]=5, d[c]=12, d[a]= ∞
第三次循环:d[s]=0, d[b]=5, d[c]=12, d[a]=18
如果我们选择边的顺序为:(s,b), (b,c), (c,a). (a,s)
初始化:d[s]=0, d[b]=∞, d[c]= ∞, d[a]= ∞
第一次循环:d[s]=0, d[b]=5, d[c]=12, d[a]=18
我们可以发现三个规律:
- 得到正确的最短路径的轮次与选择边的顺序有关。在Bellman-Ford算法中,我们其实是按照任意的某一个顺序选择的。
- 无论怎样选择边,长度为l的最短路径一定可以在第l轮循环或其之前找到。
- 每进行一次松弛操作,最短路径树上就会有一层顶点达到其最短距离。
如果要我们改进这一算法,那么有哪些方面可以入手呢?一个很明显的点就是,Bellman-Ford算法按照任意的某一顺序选择边,但边的选择顺序又会影响到找到最短路径的轮次,因此有没有办法找到一个固定的、好的边的循环顺序呢?
基于这一思路,我们来学习一下Yen的改进工作。
假定对Bellman-Ford算法中对边的每一遍松弛的次序做出如下规定:
在第一遍松弛前,我们给所有结点赋予一个随机的线性次序V1,V2,…,V|v|。
然后我们将边集合E划分为Ef U Eb(假设图G不包括自旋边),
其中Ef={(Vi,Vj)∈E,i
也就是说,Ef中的是升序边(也就是从小标号顶点到大标号顶点的边),Eb中的是降序边(也就是从大标号顶点到小标号顶点的边)。
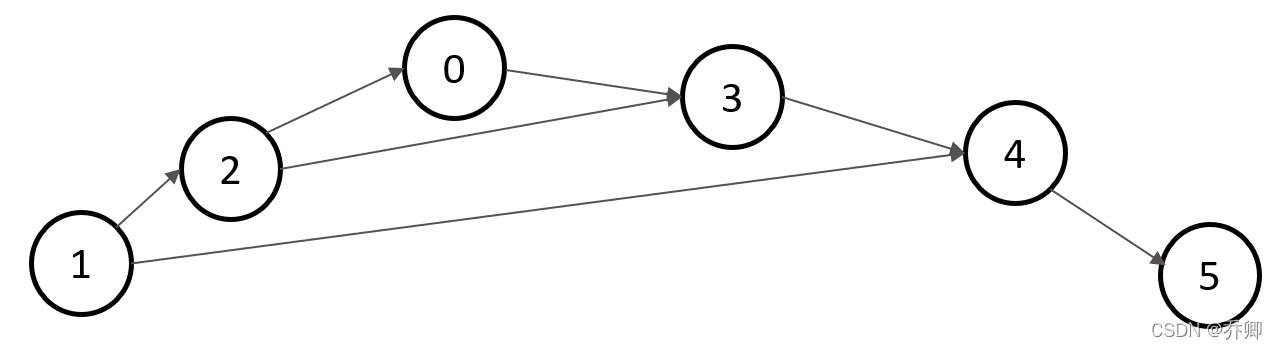
例如,对于上图,我们对边集合的划分为:
Ef={(0,3), (1,2), (1,4), (2,3), (3,4), (4,5)}
Eb={(2,0)}
假定我们以下面的方式来实现Bellman-Ford算法中的每一遍松弛操作:
以V1,V2,…,V|v|的次序访问每个结点,并对从每个节点发出的Ef边进行松弛。
再以V|v|,V|v-1|,…,V1的次序访问每个结点,并对每个结点发出的Eb边进行松弛。
这就是Yen的改进算法。现在听起来可能一头雾水,但不要着急,我们一点一点分析。首先,基于我们对松弛次序的规定,我们可以得到如下几条结论:
- Gf是无环的,且其拓扑排序为
Gb是无环的,且其拓扑排序为
理由如下:
我们首先回顾一下拓扑排序的定义。
若边(u,v)∈E(G),则u在线性序列中出现在v之前。满足该条件的线性序列成为图的拓扑排序。
我们对Gf与Gb的规定决定了结论a一定是正确的。
无论是在Gf还是Gb中,边只会全部从小顶点到大顶点,或全部从大顶点到小顶点,因此,只要从某一个节点出发,就必然会到达编号更大的结点,永远无法再回到最初编号的结点,因此无法成环。
因此,Gf的拓扑排序为
b. 在上述操作方式下,如果图G不包含从源结点s可以到达的权重为负值的环路,
则在⌈∣V∣/2⌉遍松弛操作后,V中所有节点的最短路径都能被找到。
分析如下:
假设我们要找出从s到v的最短路径。只要最短路径存在,那么:
任何递增的顶点序列都将在访问Ef的过程中被捕获,而任何递减的顶点序列都将在访问Eb的过程中被捕获。每一次松弛操作都可以捕获(在先前松弛操作基础上的)下一次(连续的)递增序列与下一次(连续的)递减序列,而对于|V|个顶点,这样一组递增序列与递减序列的数目至多只有⌈∣V∣/2⌉个。因此,相较于Bellman-Ford算法一次松弛操作向后得到最短路径上的一个顶点,Yen的改进算法一次松弛操作能够向后得到一组连续的递增序列与递减序列。
我们举个例子:
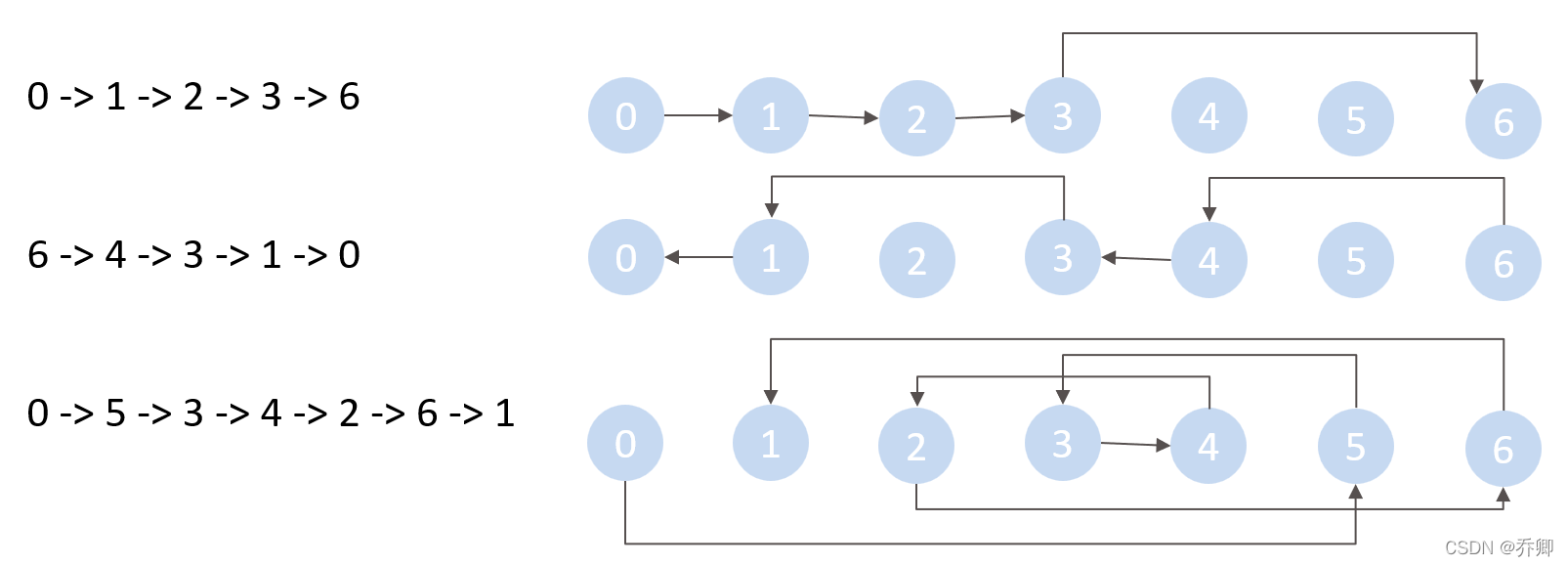
上图中的第一行是Ef及其拓扑排序,第二行是Eb及其拓扑排序,第三行是E以及从顶点0到顶点1的最短路径(0->5->3->4->2->6->1)。
那么,Yen改进算法的执行过程为:
第一趟循环:
Ef: 0->5
Eb: 0->5->3
第二趟循环:
Ef: 0->5->3->4
Eb: 0->5->3->4->2
第三趟循环:
Ef: 0->5->3->4->2->6
Eb: 0->5->3->4->2->6->1
通过如上分析,我们发现,每次循环能够向后找到的不仅仅是一个顶点,而是连续的一个递增序列与递减序列!在最坏情况下,每次循环能够至少向后找到两个顶点,因此循环次数减少了一半。具体地,不同情况下的循环次数总结为下表:

到这里,我们已经分析了Yen改进算法的正确性。最后,我们仍有一个问题——该算法是否改善了Bellman-Ford算法的渐进运行时间(时间复杂度)?
分析发现,尽管每次松弛操作基于拓扑排序的点进行,但每次仍处理|E|条边。
循环此时由|V|-1降低到⌈∣V∣/2⌉,但这是常数级别的优化。
它并没有改进Bellman-ford算法的渐近运行时间,
它只是将系数降低到1/2。时间复杂度仍为O(|E|*|V|)。
但不可否认的是,Yen的工作提高了Bellman-Ford算法的效率,同时其巧妙地利用了拓扑排序的思想,具有很好的启发性,值得我们学习。
本文来自互联网用户投稿,文章观点仅代表作者本人,不代表本站立场,不承担相关法律责任。如若转载,请注明出处。 如若内容造成侵权/违法违规/事实不符,请点击【内容举报】进行投诉反馈!