【GAN】SAGAN ICML‘19
《Self-Attention Generative Adversarial Networks》ICML’19,Goodfellow署名。
深度卷积网络能够提升 GANs 生成高分辨率图片的细节。这篇文章为了解决在生成大范围相关(Long-range dependency)的图片区域时,CNN局部感受野的影响,因此在DCGAN的基础上引入了Self-attention。
解决什么问题
在生成例如人脸图片时,细节是非常重要的,比如左右眼,只要左右眼有一点点不对称,生成的人脸就会特别不真实,因此左右眼的区域就是“大范围相关”(Long-range dependency)的。存在Long-range dependency的场景有很多,但是由于CNN局部感受野的限制(卷积核很难覆盖很大的区域),很难捕捉到全局的信息,比如在对右眼区域做卷积时看不到左眼对右眼的影响,这样生成的人脸图片的左右眼很可能没有什么关系。
想要看到全局的信息,有几种做法:1、增大卷积核尺寸、扩大感受野——增大参数量和计算量,而且除非卷积核和图片一样大,否则还是存在视野盲区;2、加深卷积层——增大计算量;3、采用全连接层来获取全局信息——因小失大。
因此把self- attention引入是一个简约且高效的方法。
怎么做——SAGAN模型
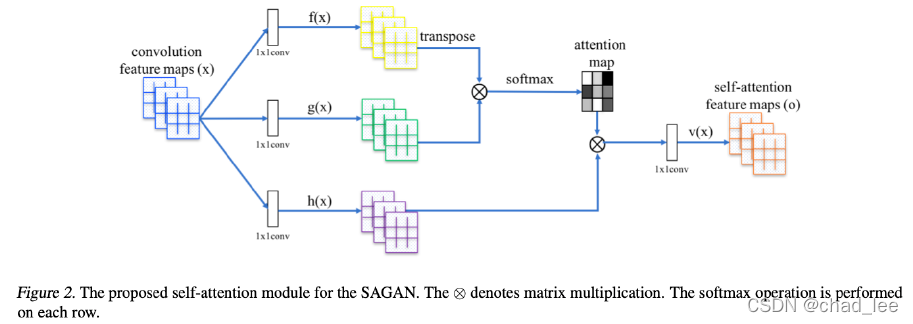
我们先按文章中的说法介绍:
经过卷积操作得到的feature map x x x, x ∈ R C × N \boldsymbol{x} \in \mathbb{R}^{C \times N} x∈RC×N。 f ( x ) , g ( x ) , h ( x ) f(x), g(x),h(x) f(x),g(x),h(x)都是 1 × 1 1 \times1 1×1的卷积,将 f ( x ) f(x) f(x)输出的转置和 g ( x ) g(x) g(x)的输出相乘,再经过softmax归一化得到一个attention map;将得到的attention map和 h ( x ) h(x) h(x)逐点相乘,得到self-attention的特征图。
具体实现: f ( x ) = W f x , g ( x ) = W g x , h ( x ) = W h x \boldsymbol{f}(\boldsymbol{x})=\boldsymbol{W}_{\boldsymbol{f}} \boldsymbol{x}, \boldsymbol{g}(\boldsymbol{x})= \boldsymbol{W}_{\boldsymbol{g}} \boldsymbol{x}, \boldsymbol{h}(\boldsymbol{x})=\boldsymbol{W}_{\boldsymbol{h}} \boldsymbol{x} f(x)=Wfx,g(x)=Wgx,h(x)=Whx,$W_{g} \in R^{\bar{C} \times C}, W f ∈ R c ˉ × C , W_{f} \in R^{\bar{c} \times C}, Wf∈Rcˉ×C,W_{h} \in R^{C \times C}$是学习的权重矩阵,通过
本文来自互联网用户投稿,文章观点仅代表作者本人,不代表本站立场,不承担相关法律责任。如若转载,请注明出处。 如若内容造成侵权/违法违规/事实不符,请点击【内容举报】进行投诉反馈!