论文阅读笔记《Common Visual Pattern Discovery via Spatially Coherent Correspondences》
核心思想
两组点集中共有的匹配区域通常具备两个特点:1.局部的特征相似;2.特征点在空间上的分布也相似。作者将候选匹配点对作为图的节点,将两种相似性统一到边的权重来表示。通过寻找图中稠密连接的子图来寻找两个点集中的匹配区域,如下图所示
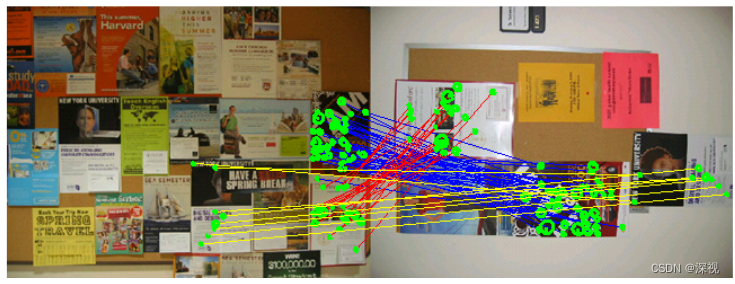
实现过程
首先,利用SIFT等算法分别从两幅图像中提取特征点集 P , Q P,Q P,Q,其中的特征点 p p p包含两个特征信息 p d , p c p_d,p_c pd,pc, p d p_d pd表示由SIFT提取的局部特征向量, p c p_c pc表示特征点的坐标。内积空间 C = P × Q C=P\times Q C=P×Q表示所有可能的对应关系,每组对应点 c i c_i ci都由一对点 ( i , i ′ ) (i,i') (i,i′)表示,其中 i ∈ P , i ′ ∈ Q i\in P, i'\in Q i∈P,i′∈Q。每组对应点的局部特征相似得分 S c i = f 1 ( i d , i d ′ ) S_{c_i}=f_1(i_d,i'_d) Sci=f1(id,id′),由于匹配点通常局部特征都比较相似,因此仅保留相似得分较大的对应点 M = { c ∣ c ∈ C , S c > ϵ } M=\{c|c\in C, S_{c}>\epsilon \} M={c∣c∈C,Sc>ϵ}。
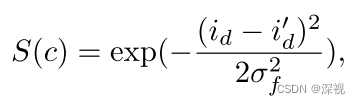
对于两组对应点 c i = ( i , i ′ ) c_i=(i,i') ci=(i,i′)和 c j = ( j , j ′ ) c_j=(j,j') cj=(j,j′),设第一幅图中的点 i i i和 j j j之间的距离为 l i j l_{ij} lij,第二幅图中的点 i ′ i' i′和 j ′ j' j′之间的距离为 l i ′ j ′ l_{i'j'} li′j′。如果它们是两组匹配点,那么我们应该可以通过对第二幅图放缩 l i j / l i ′ j ′ l_{ij}/l_{i'j'} lij/li′j′倍,来使两组点对齐。同理,如果两个公共的匹配区域包含 n n n组对应点,那么他们两两之间构成的匹配关系应该有较为接近的放缩系数,而噪点或离群点通常不具备这样的特点。两组对应点之间的几何一致性得分 S c i c j ( s ) = f 2 ( ∣ l i j − s l i ′ j ′ ∣ ) S_{c_ic_j}(s)=f_2(|l_{ij}-sl_{i'j'}|) Scicj(s)=f2(∣lij−sli′j′∣), s s s表示放缩系数。 f 2 ( x ) f_2(x) f2(x)是一个非负单调递减函数,本文中取
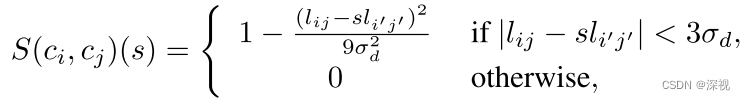
假设一个对应点集 M M M包含 m m m组对应点, M = { c 1 , c 2 . . . c m } M=\{c_1, c_2...c_m\} M={c1,c2...cm}。可以构建一个包含 m m m个节点的图 G G G,每个节点都表示一组对应点,这个图称之为动态对应图(dynamic correspondence graph)。节点 i i i和 j j j之间的边的权重 w i j w_{ij} wij可表示为
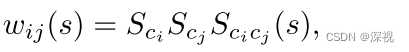
该权重与放缩系数 s s s有关,则加权邻接矩阵 A ( s ) A(s) A(s)可定义为
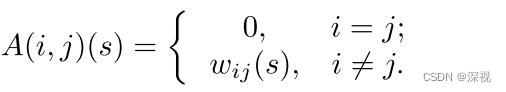
A ( s ) A(s) A(s)是一个对称的非负矩阵。
对于一个由 n n n个特征点构成的共同匹配区域,当选择正确的放缩系数 s 0 s_0 s0时,对应点之间的局部特征相似得分和几何一致性得分应该都很高,即边的权重会较大,那么就对应图 G G G中的一个稠密子图 T T T。这个稠密子图具备较高的平均类内相似性得分(average intra-cluster affinity score) S a v ( s 0 ) = 1 n 2 ∑ i ∈ T , j ∈ T A ( i , j ) ( s 0 ) S_{av}(s_0)=\frac{1}{n^2}\sum_{i\in T,j\in T}A(i,j)(s_0) Sav(s0)=n21∑i∈T,j∈TA(i,j)(s0)。如果使用指示向量 y y y来表示 T T T,即如果 i ∈ T i\in T i∈T, y ( i ) = 1 y(i)=1 y(i)=1否则为 0 0 0。则 S a v ( s 0 ) S_{av}(s_0) Sav(s0)可表示为 S a v ( s 0 ) = 1 n 2 y T A ( s 0 ) y = x T A ( s 0 ) x S_{av}(s_0)=\frac{1}{n^2}y^TA(s_0)y=x^TA(s_0)x Sav(s0)=n21yTA(s0)y=xTA(s0)x,其中 x = y / n x=y/n x=y/n。由于 ∑ i y ( i ) = n \sum_iy(i)=n ∑iy(i)=n,则 ∑ i x ( i ) = 1 \sum_ix(i)=1 ∑ix(i)=1。
根据Motzkin-Straus定理,下式中的局部极大值点就对应图中的一个最大团
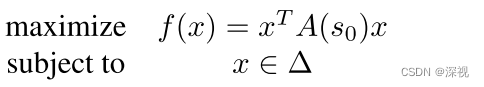
其中
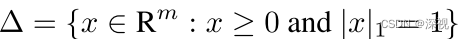
简而言之,作者将寻找图 G G G中稠密子图 T T T的问题转化为了求解目标函数 f ( x ) f(x) f(x)的局部极大值点的问题。
给定一个放缩系数 s 0 s_0 s0,优化目标函数 f ( x ) f(x) f(x)可能包含许多的局部极大值点,极值点的值越大越有可能对应正确的公共匹配区域。给定一个初始的 x ( 1 ) x(1) x(1),则 f ( x ) f(x) f(x)的局部极大值点 x ∗ x^* x∗可通过模仿者等式 (Replicator Equation)得到
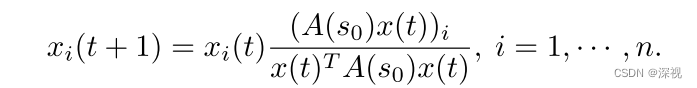
通过迭代计算上述等式,当数值收敛于稳定点时,则对应于 f ( x ) f(x) f(x)的一个局部极大值点。
为了找到全部的局部最大值点 { x ∗ } \{x^*\} {x∗},可以提供多个初始化 x ( 1 ) x(1) x(1)分别进行迭代计算。由于局部最大值点 x ∗ x^* x∗对应于共同匹配区域,因此它具备两个特性:
- 局部性,对于图 G G G中每个节点 v v v,包含 v v v在内的共同匹配区域是 N ( v ) ∪ v N(v)\cup v N(v)∪v的子集, N ( v ) N(v) N(v)表示 v v v的邻域。因此只需要对图 G G G中每个节点 v v v的邻域中对 x ( 1 ) x(1) x(1)进行初始化。
- 非交叉性,两个不同的共同匹配区域通常不会包含公共的顶点。这意味这两个局部极大值点 x ∗ , y ∗ x^*,y^* x∗,y∗,其对应两个不同的共同匹配区域,应满足 x ∗ T y ∗ ≈ 0 x^{*T}y^*\approx 0 x∗Ty∗≈0。
利用上述特性,可以对图 G G G中的每个节点及其邻域分别进行初始化,然后通过模仿者等式寻找到该初始化对应的局部极大值点。将所有的局部极大值点进行降序排列,并将极值较小的点舍去。最后,根据 x ∗ T y ∗ x^{*T}y^* x∗Ty∗是否大于 η \eta η来将局部极大值点进行合并,从而求得最终要保留的局部极大值点,如算法1所示

得到局部极大值点还要将其恢复到对应的共同匹配区域, x ∗ x^* x∗中的每个点 x i ∗ x_i^* xi∗表示对应点 i i i是正确匹配点的概率,可以通过算法2得到共同匹配区域

在实际应用中,放缩系数 s s s通常属于一个范围 R = [ s 0 , s 1 ] R=[s_0,s_1] R=[s0,s1],因此可以通过在该范围内均匀采样得到 s s s,然后分别计算不同放缩系数条件下对应的共同匹配区域,如算法3所示

创新点
- 将特征点的匹配问题转化为了寻找图的最大团问题
- 利用共同匹配区域的局部性和非交叉性来优化求解过程
算法总结
作者关注的是寻找两幅图中局部的共同匹配区域问题,并且非常巧妙地将其转化为了寻找图的最大团问题,并利用了共同匹配区域的局部性和非交叉性来优化求解过程,使其能够更好更快地求解。该方法还有一个优势是可以解决一对一、一对多和多对多的匹配问题,这在应用中具备很高的价值。
本文来自互联网用户投稿,文章观点仅代表作者本人,不代表本站立场,不承担相关法律责任。如若转载,请注明出处。 如若内容造成侵权/违法违规/事实不符,请点击【内容举报】进行投诉反馈!