python爬虫酷狗论文_酷狗音乐的爬取,基于python,从无到有完整教程-上:搭建环境及爬取原理讲解...
所需的库:
import requests,random,string,re,time,jsonfrom bs4 import BeautifulSoupfrom selenium import webdriver#Requests库是用Python编写的,基于urllib,采用Apache2 Licensed开源协议的HTTP库;#相比urllib库,Requests库更加方便,可以节约我们大量的工作,完全满足HTTP测试需求;#WebDriver是一个用来进行复杂重复的web自动化测试的工具#Beautiful Soup 提供一些简单的、python 式的函数用来处理导航、搜索、修改分析树等功能。它是一个工具箱,通过解析文档为用户提供需要抓取的数据1234567
配置interpreter(编译器):
http://dxb.myzx.cn
1、 构建编译器
进入软件,左上角File > settings,进入到下图界面
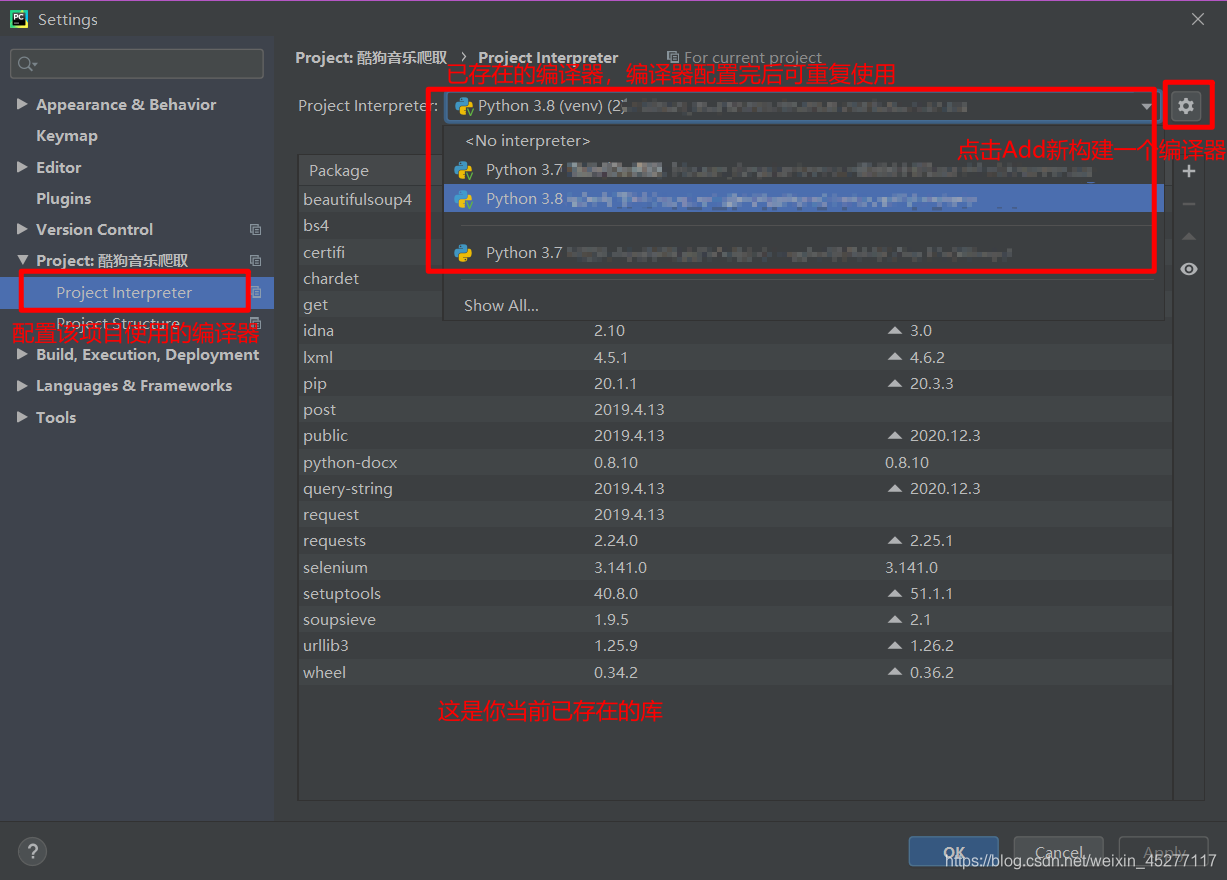
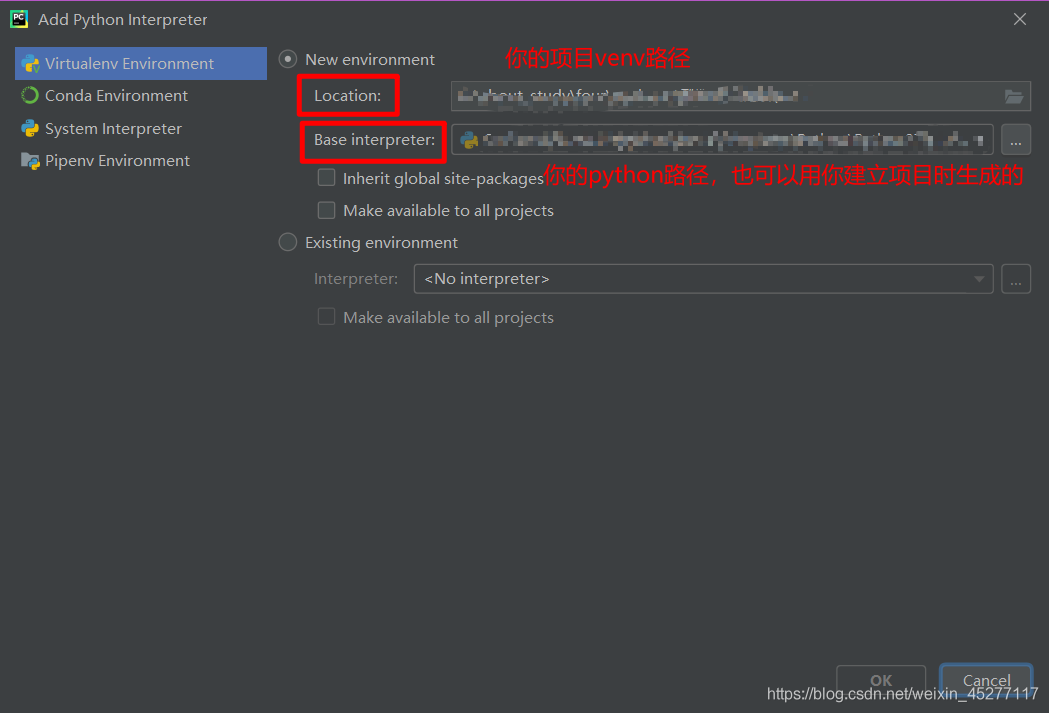
2、 下载库
还是刚刚那个settings窗口
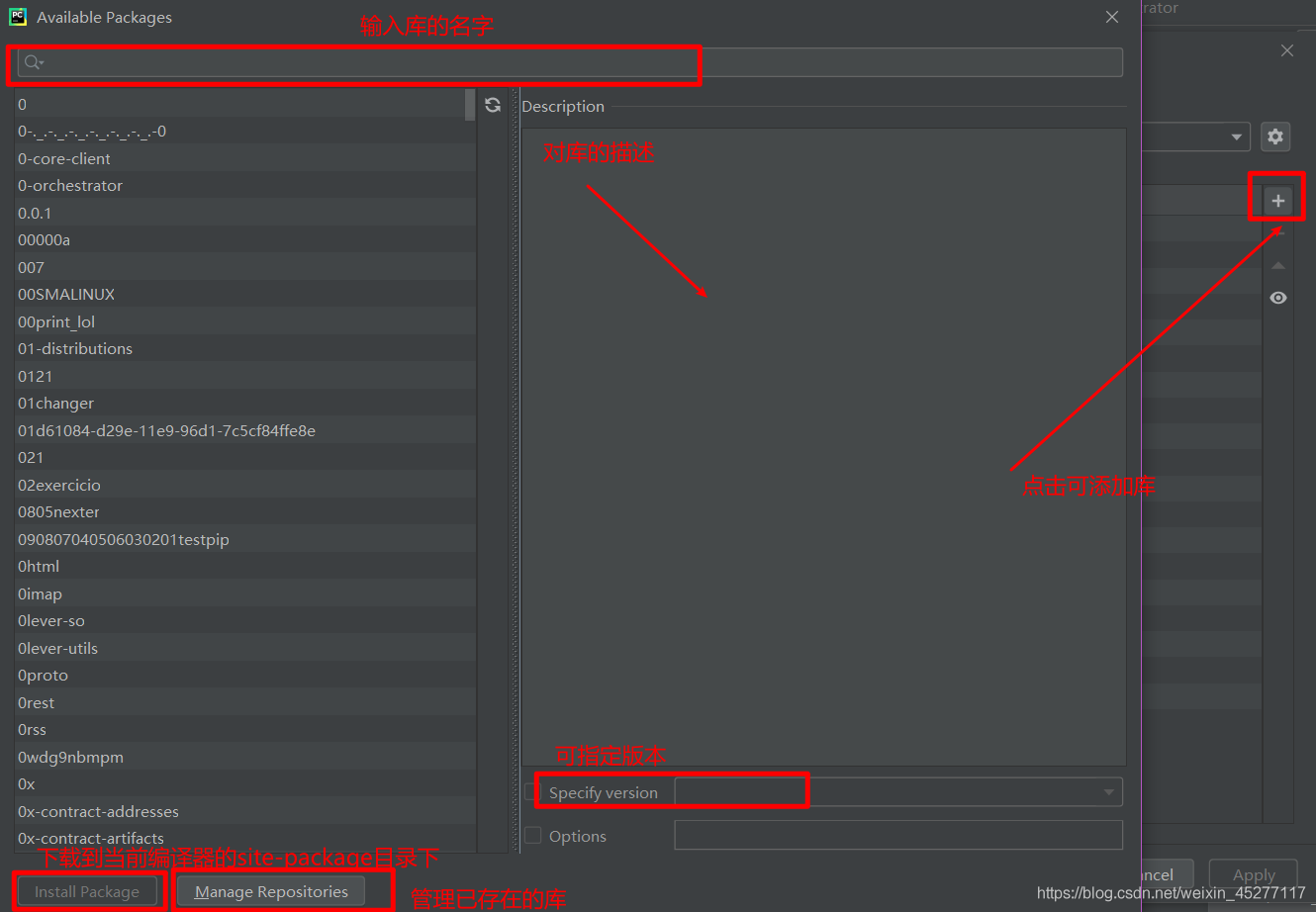
获取网页数据:
http://ask.baikezh.com/hunan/
建立webdriver,此处使用微软的edge浏览器
需要下载edge的
webdriver
然后还要将此webdriver的目录加到selenium的webdriver目录中,为什么呢,因为selenium库要使用他,为什么要用selenium,因为我们要用它来解码html(当然它还可以干很多活,比如根据特征定位某个元素并执行动作,比如鼠标点击或键盘输入)
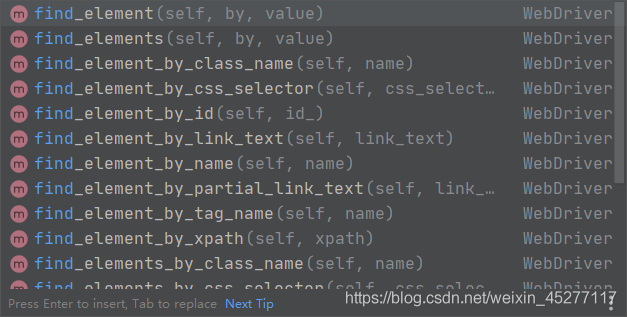
此处选择-
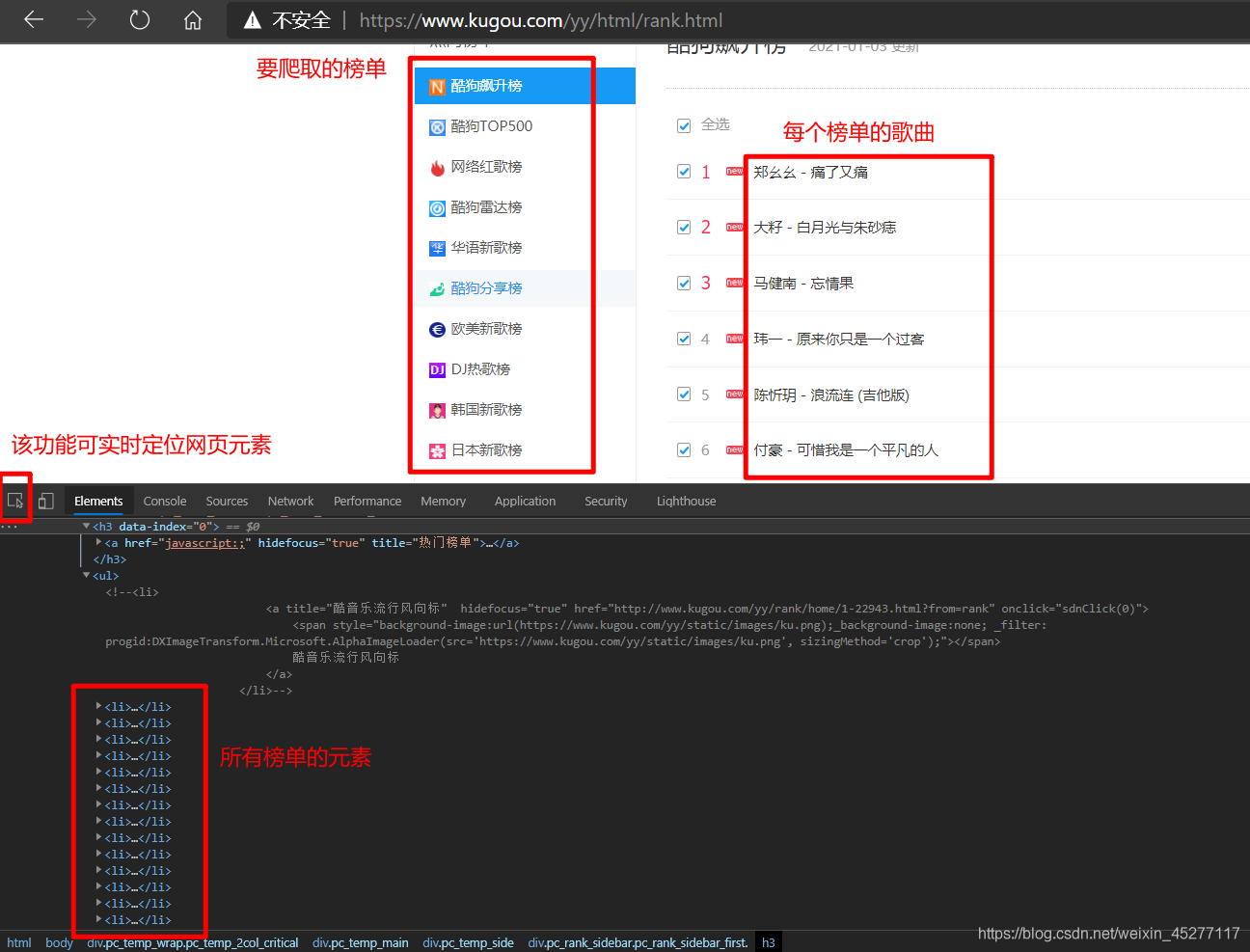
经过分析,每个榜单的定位元素为li,其中的href属性值即为每个
榜单的歌曲页面url,即上图中的右侧

而每首歌曲的播放页面在一个id为rankwrap的div里面,里面也有一长串li列表元素,其中也就是包含每个
歌曲播放页面链接的元素,如下图
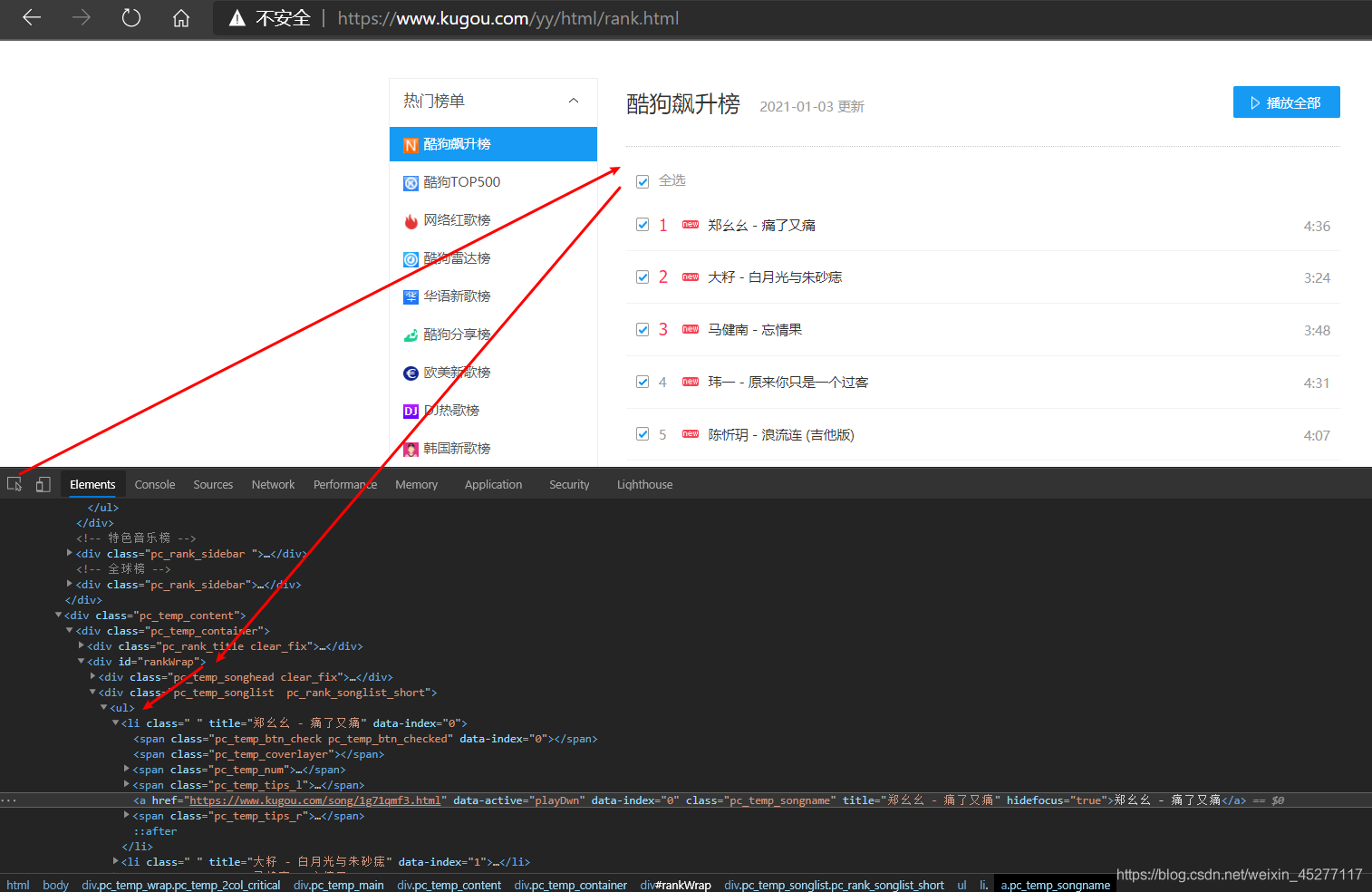
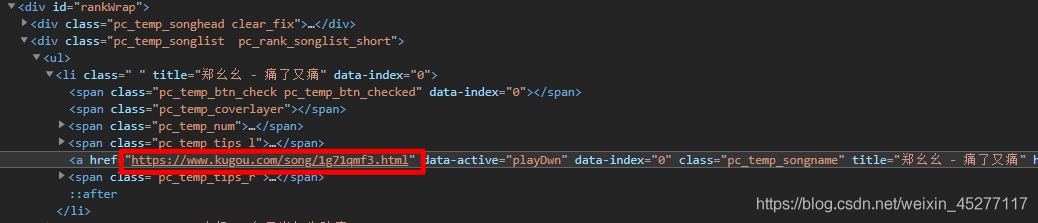
到此,我们分析这些分别包含了
榜单链接,歌曲播放页面链接的元素,然后使用beautifulsoup库所提供给我们的find方法来写一个自动化爬取流程,如下,爬取的目标为歌曲播放页链接
soup = BeautifulSoup(data, 'html.parser')
# 网页带有16进制,需解码href_list = soup.findAll('a', attrs="data-active=\"playDwn\"", class_="pc_temp_songname")123
find和findall方法都是基于给定特征来运作,如id,class等等
像特殊的属性,如data-active参数项,要使用attrs=" “关键字来包含
其他的可直接写入括号中,如class,而标签直接写在开头,如"a”,“div”,“li”
获取歌曲的下载url:
上一步骤中,我们已经获取了每个歌曲的
播放页面链接
我们手动跳转到其中一首歌曲的播放页面链接,如下图
我们F12打开开发者工具,转到network来查看在在加载当前页面时,浏览器后台所发生的网络请求
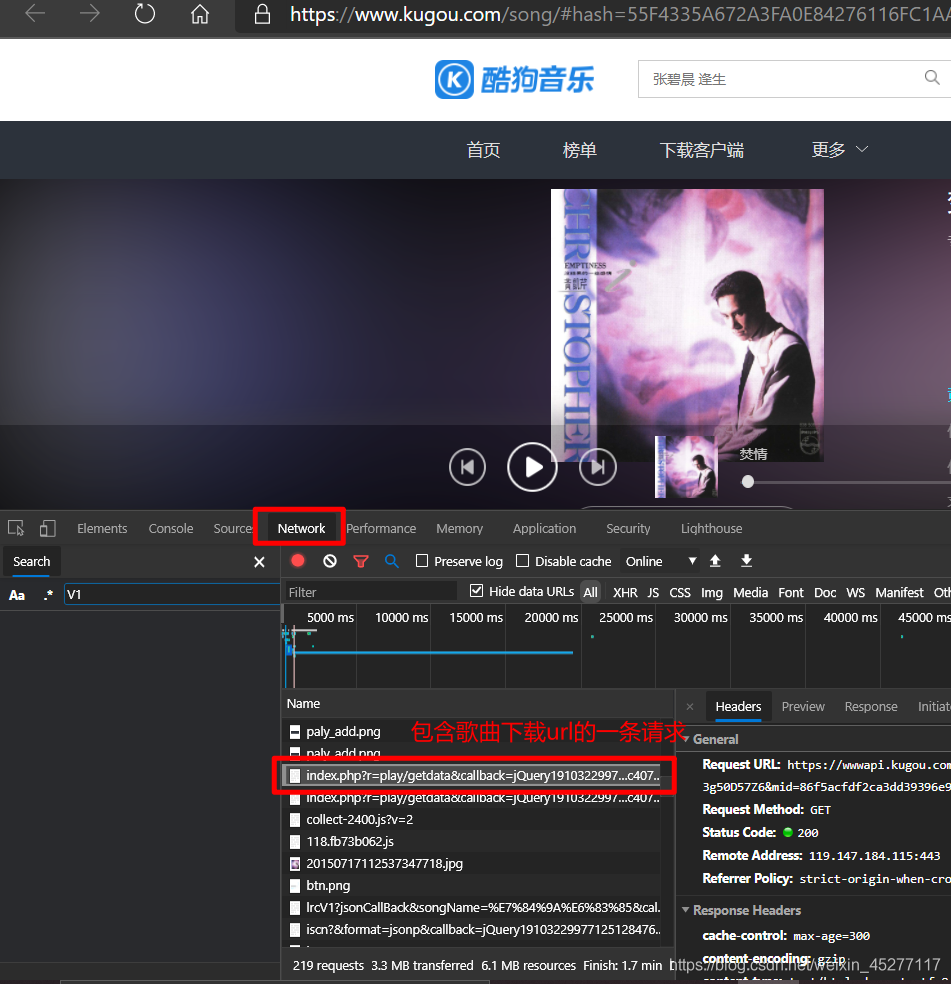
其中有一条请求就包含了歌曲下载url,我已经帮大家找出来了
该请求前缀名为
index.php?r=play/getdata&callback,该请求包含了作者名,歌曲名,歌曲播放链接,封面等等,是一个json格式文件,如下图
http://dxb.myzx.cn/oldage/
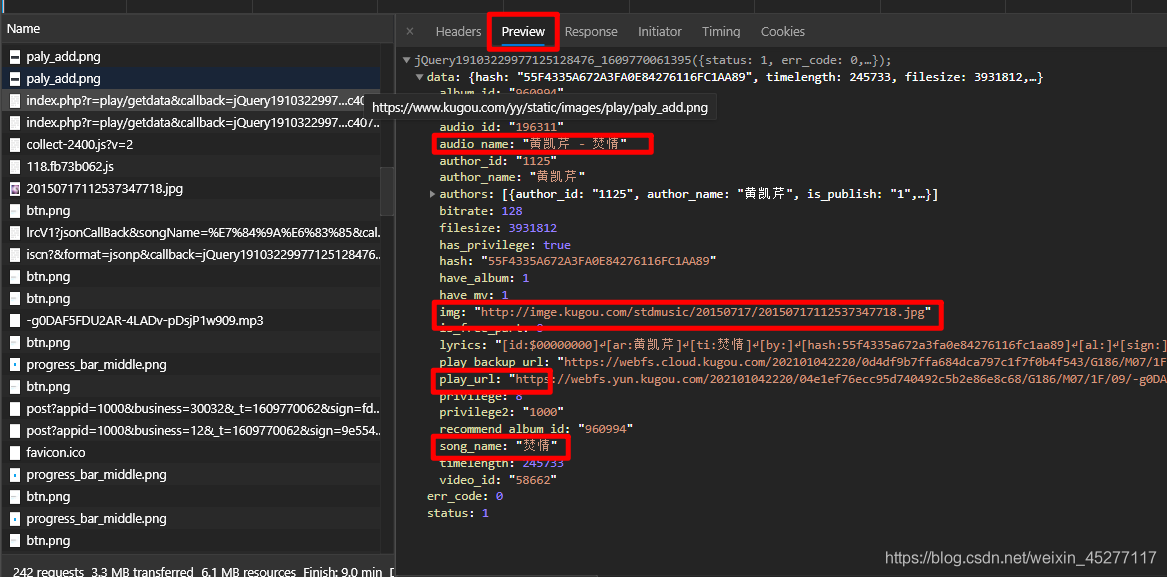
那么我们看看如何让我们的虚拟浏览器自动去得到这个包含了如此多信息的链接?
我们回到这个地方
http://zzdxb.baikezh.com/

可以看到,这是由大大小小的参数项拼接而成的一条请求
https://wwwapi.kugou.com/yy/index.php?r=play/getdata&callback=jQuery19103229977125128476_1609770061395&hash=55F4335A672A3FA0E84276116FC1AA89&dfid=2SoVLy2WYH7H12v3g50D57Z6&mid=86f5acfdf2ca3dd39396e98ac4074a42&platid=4&album_id=960994&_=16097700613961
里面分别有hash,dfid,mid,platid,albumid这些参数项,经过分析,除了hash和platid指定之外,其他都是随机数就行(是不是很好操作了<_>)
hash呢,细心的小伙伴应该有发现,他就包含在
歌曲播放页面的链接里面,然后platid固定为4就ok了,其他的我们就需要用万能的random来实现了。
http://ask.baikezh.com/
接下来就是写代码了,代码部分分在下一章,不然加起来太长了,怕你们不看||_||
本文来自互联网用户投稿,文章观点仅代表作者本人,不代表本站立场,不承担相关法律责任。如若转载,请注明出处。 如若内容造成侵权/违法违规/事实不符,请点击【内容举报】进行投诉反馈!