0107-【课程实战】-Python数据分析炒菜-第10章-数据分组/数据透视表
文章目录
- 10.1 数据分组
- 10.1 分组键是列名
- 10.1.2 分组键是Series
- 10.1.3 神奇的aggregate方法
- 10.1.4 对分组后的结果重置索引
- 10.2 数据透视表
10.1 数据分组
10.1 分组键是列名
import pandas as pd
import numpy as npdf = pd.read_csv(r"C:\Users\leadi\Python\01.python\input\train-pivot.csv",encoding="gbk")
df
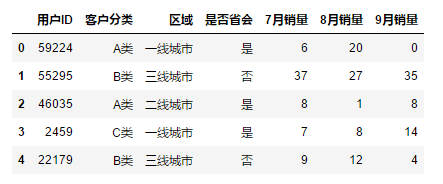
单列
df.groupby("客户分类")输出
df.groupby("客户分类").count()
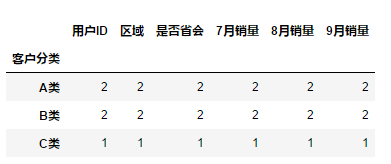
df.groupby("客户分类").sum()
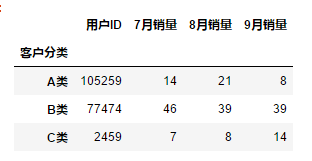
多列
df.groupby(["客户分类","区域"]).sum()
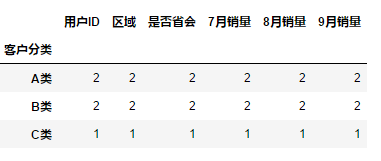
10.1.2 分组键是Series
df.groupby(df["客户分类"]).sum()
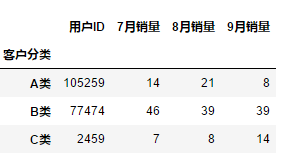
与单列一致
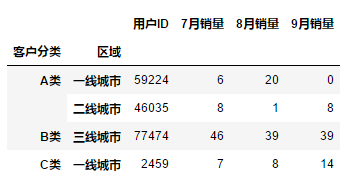
df.groupby([df["客户分类"],df["区域"]]).sum()
10.1.3 神奇的aggregate方法
可以同时,做多个汇总
df.groupby("客户分类").aggregate(["count","sum"])
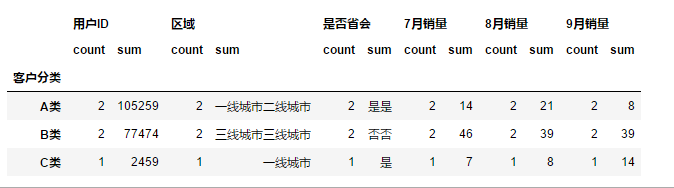
针对不同的列进行汇总
df.groupby("客户分类").aggregate({"用户ID":"count","7月销量":"sum"})
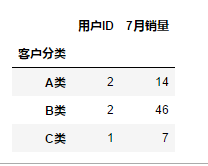
10.1.4 对分组后的结果重置索引
df.groupby("客户分类").aggregate({"用户ID":"count","7月销量":"sum"}).reset_index()
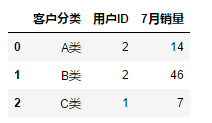
10.2 数据透视表
pd.pivot_table(df,values = "用户ID",columns = "区域",index = "客户分类",aggfunc = "count",margins = True)
-
df 数据框
-
value 对象为值
-
columns 列名分类
-
index 行分类
-
aggfunc 计算方式
-
margins 两边的all统计
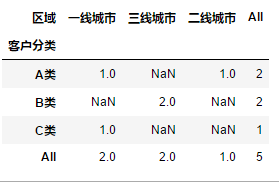
-
margins _name 替换名
-
fill_value ,缺失填充值
替换名
pd.pivot_table(df,values = "用户ID",columns = "区域",index = "客户分类",aggfunc = "count",margins = True,margins_name = "总计")
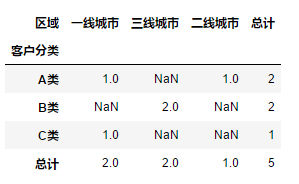
填充
pd.pivot_table(df,values = "用户ID",columns = "区域",index = "客户分类",aggfunc = "count",margins = True,margins_name = "总计",fill_value = 0)
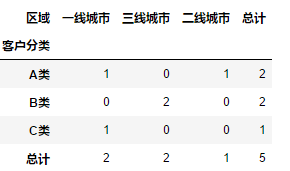
多列分别统计
pd.pivot_table(df,values = ["用户ID","7月销量"],columns = "区域",index = "客户分类",aggfunc = {"用户ID":"count","7月销量":"sum"},margins = True,margins_name = "总计",fill_value = 0)

本文来自互联网用户投稿,文章观点仅代表作者本人,不代表本站立场,不承担相关法律责任。如若转载,请注明出处。 如若内容造成侵权/违法违规/事实不符,请点击【内容举报】进行投诉反馈!