selenium 爬党建新闻与应用(确定版)
selenium 爬党建新闻与应用
- 1、前言:
- 2、知识点总结:
- 2.1爬虫指定页码(for循环、格式化字符串)
- 2.2空列表 怎么把内容插入空列表
- 2.3selenium点击链接进入子页面抓取内容(新闻抓取案例一)
- 3、完整代码
- 4、实际应用
1、前言:
①selenium 去爬
②我爬的数据是新闻的所有内容,目前图片爬不到
③爬所有的新闻数据
被爬网站
我爬的信息是党建网的7页的所有新闻标题、内容、来源这3个字段
1、因为目前只有7页 所以我爬7页,这里可以自己自定义爬虫页码
党建网地址:http://cpc.people.com.cn/GB/64093/64387/index.html
2、知识点总结:
2.1爬虫指定页码(for循环、格式化字符串)

这里用到for循环 和格式化字符串知识点 详情:
http://www.python3.vip/tut/py/basic/10/
http://www.python3.vip/tut/py/basic/11/#for-%E5%BE%AA%E7%8E%AF
2.2空列表 怎么把内容插入空列表
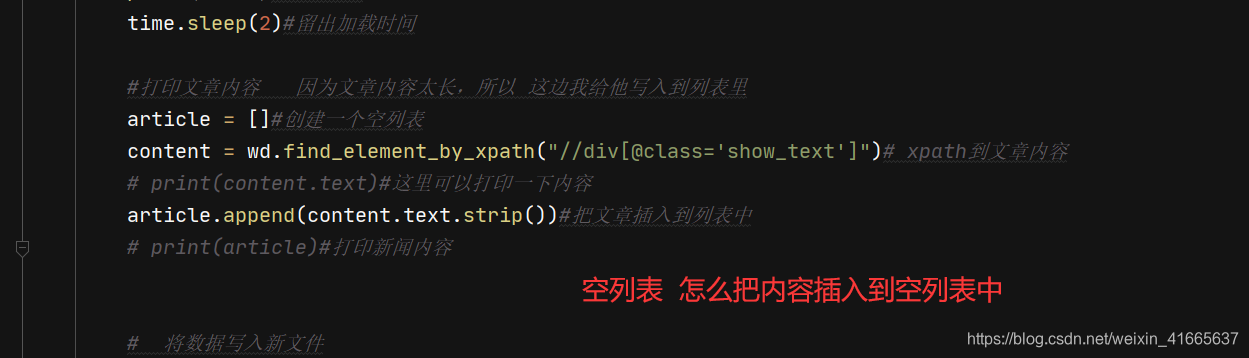
article = []#创建一个空列表
content = wd.find_element_by_xpath("//div[@class='show_text']")# xpath到文章内容
article.append(content.text.strip())#把文章插入到列表中
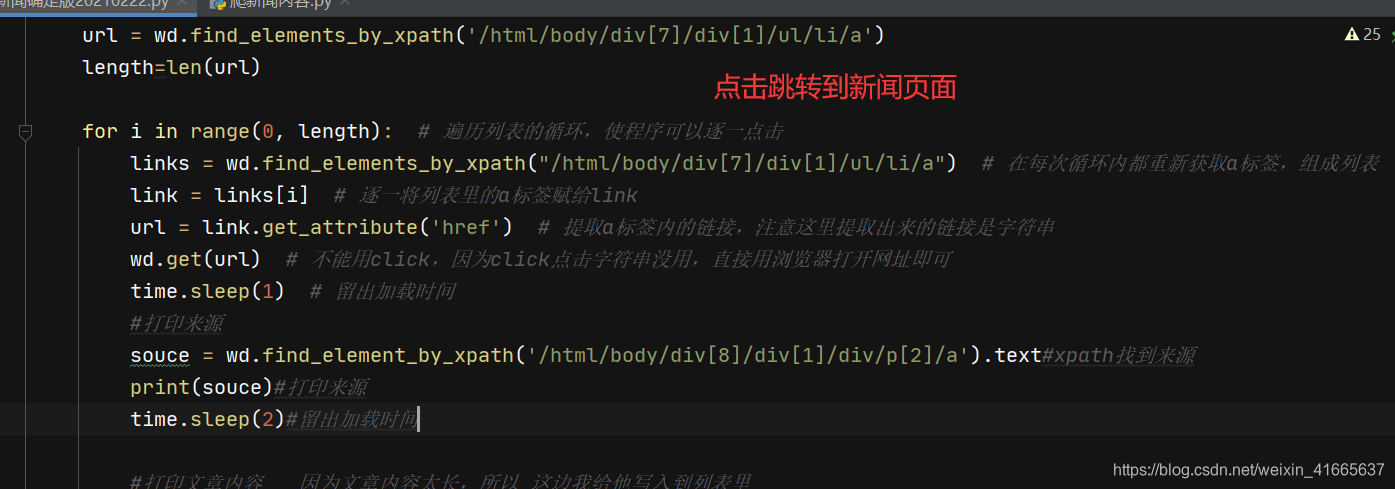
2.3selenium点击链接进入子页面抓取内容(新闻抓取案例一)
参考地址:https://blog.csdn.net/qq_43251443/article/details/82819887
3、完整代码
from selenium import webdriver
import time
# 创建 Webwd 实例对象,指明使用chrome浏览器驱动wd = webdriver.Chrome(r'D:\tools-work\chromedriver_win32\chromedriver.exe')wd.implicitly_wait(5)#等待时间 一定要写# 链接地址
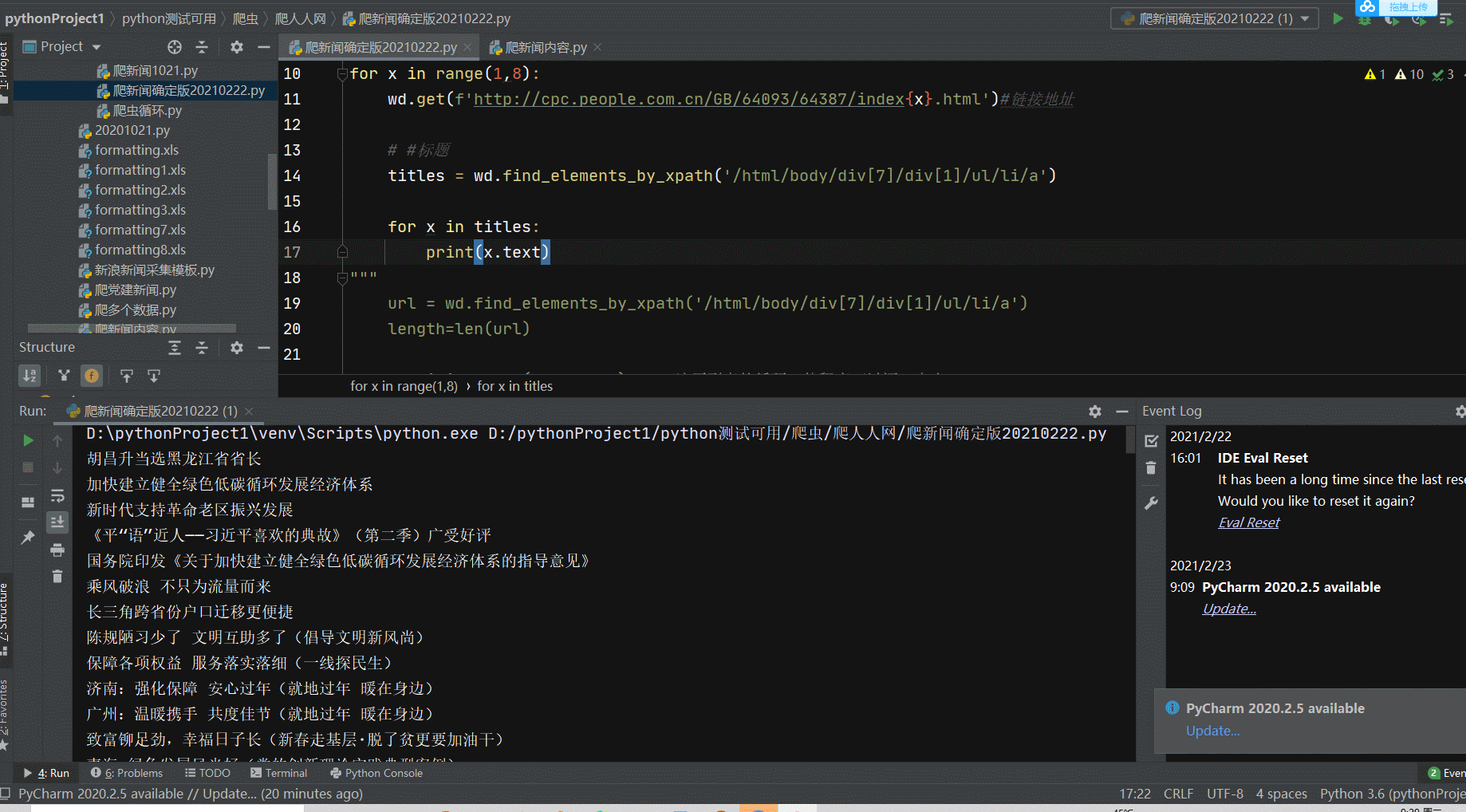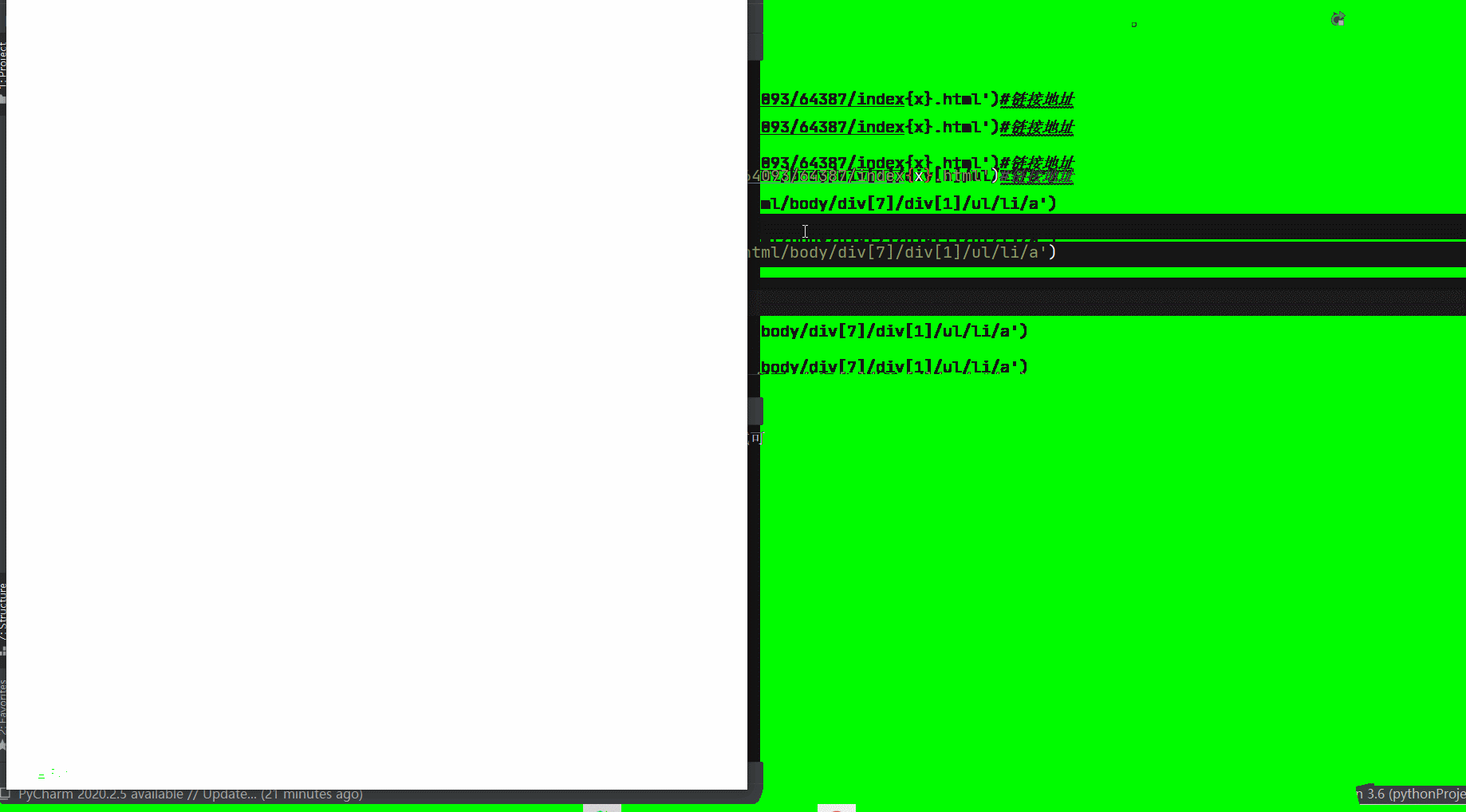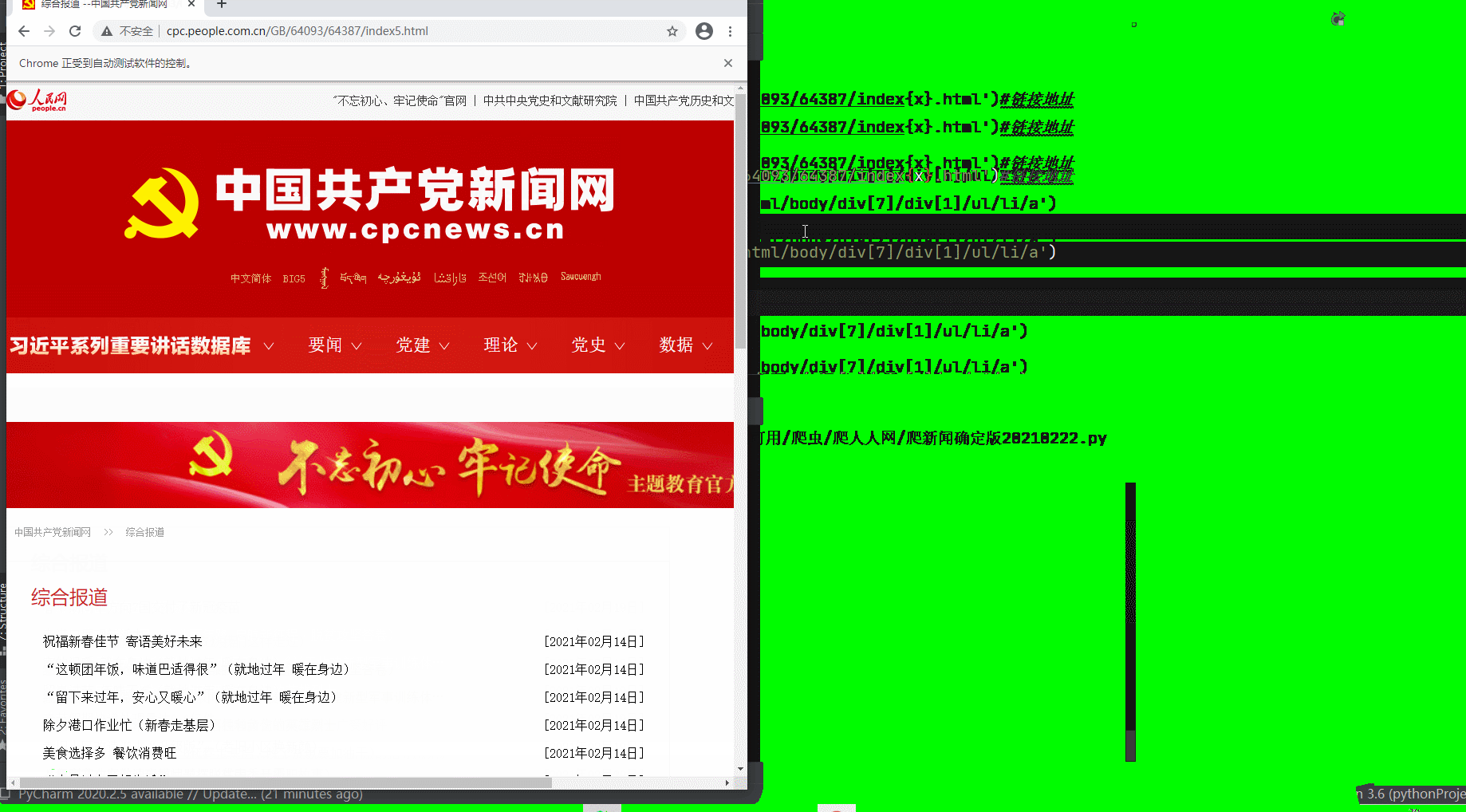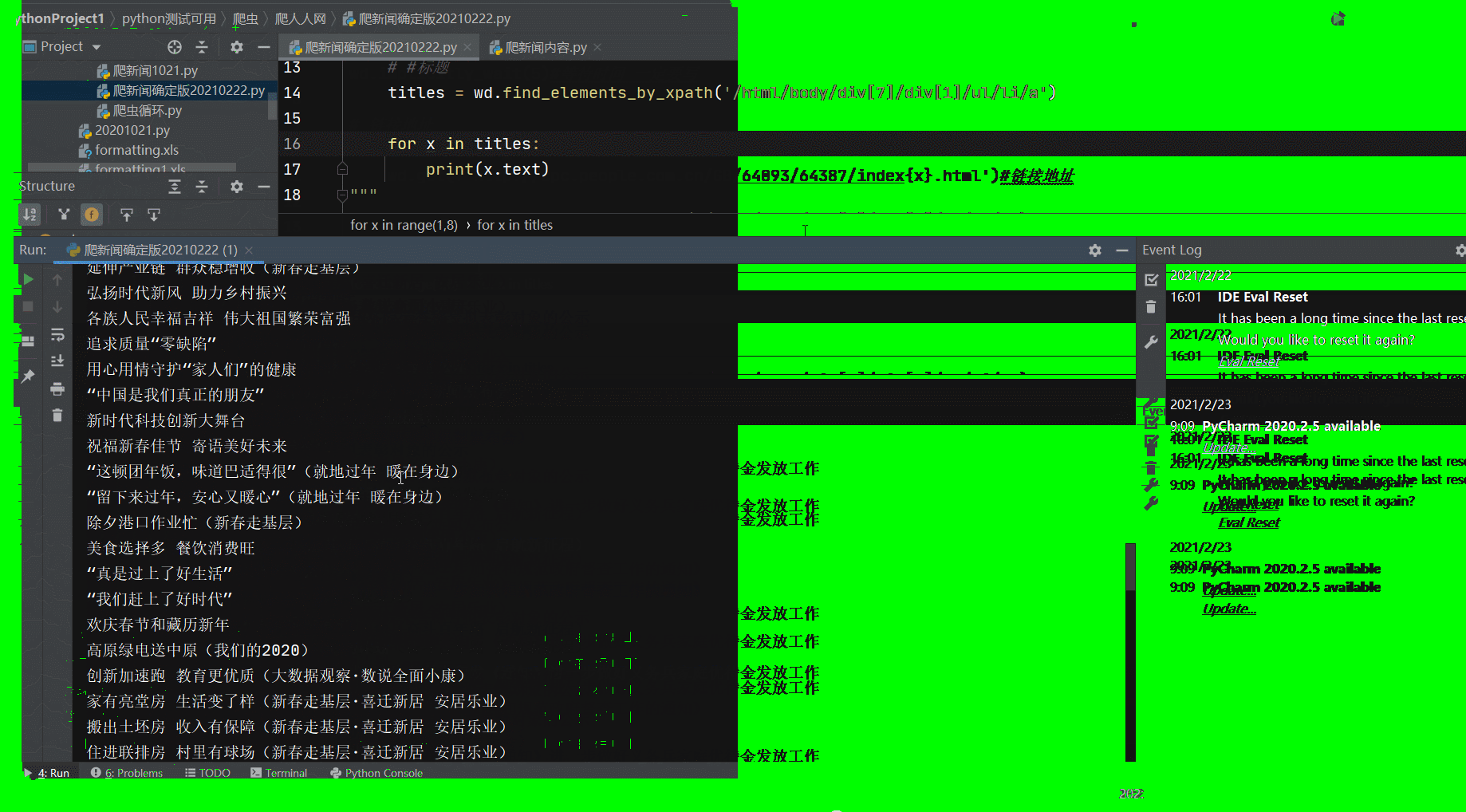
for x in range(1,8):wd.get(f'http://cpc.people.com.cn/GB/64093/64387/index{x}.html')#链接地址# #标题titles = wd.find_elements_by_xpath('/html/body/div[7]/div[1]/ul/li/a')for x in titles:print(x.text)url = wd.find_elements_by_xpath('/html/body/div[7]/div[1]/ul/li/a')length=len(url)for i in range(0, length): # 遍历列表的循环,使程序可以逐一点击links = wd.find_elements_by_xpath("/html/body/div[7]/div[1]/ul/li/a") # 在每次循环内都重新获取a标签,组成列表link = links[i] # 逐一将列表里的a标签赋给linkurl = link.get_attribute('href') # 提取a标签内的链接,注意这里提取出来的链接是字符串wd.get(url) # 不能用click,因为click点击字符串没用,直接用浏览器打开网址即可time.sleep(1) # 留出加载时间#打印来源souce = wd.find_element_by_xpath('/html/body/div[8]/div[1]/div/p[2]/a').text#xpath找到来源print(souce)#打印来源time.sleep(2)#留出加载时间#打印文章内容 因为文章内容太长,所以 这边我给他写入到列表里article = []#创建一个空列表content = wd.find_element_by_xpath("//div[@class='show_text']")# xpath到文章内容# print(content.text)#这里可以打印一下内容article.append(content.text.strip())#把文章插入到列表中print(article)#打印新闻内容# 将数据写入新文件# print("\n")wd.back() # 后退,返回原始页面目录页time.sleep(1) # 留出加载时间
print(length) # 打印列表长度,即有多少篇文章
wd.quit()#关闭列表代码运行展示
4、实际应用
1、打印时 根据实际情况 按print去打印,打印时 按需求打印 不用的 给注释了
2、打印完后 可以把内容直接复制到数据库,或者是先存入excle表再复制到数据库
3、xpath用法 这个要自己学习
4、selenium操作 这个要自己学习
参考地址:
https://blog.csdn.net/qq_43251443/article/details/82819887
http://www.python3.vip/tut/py/basic/10/
http://www.python3.vip/tut/py/basic/11/#for-%E5%BE%AA%E7%8E%AF
本文来自互联网用户投稿,文章观点仅代表作者本人,不代表本站立场,不承担相关法律责任。如若转载,请注明出处。 如若内容造成侵权/违法违规/事实不符,请点击【内容举报】进行投诉反馈!