爬虫项目二十二:学爬虫就是单纯的喜欢,用Python爬下4K壁纸网所有美女壁纸
文章目录
- 前言
- 一、生成页面url
- 二、获取图片链接
- 三、下载图片
- 总结
前言
用Python将4K美女高清壁纸爬取下载到本地
提示:以下是本篇文章正文内容,下面案例可供参考
一、生成页面url
目标网页:https://www.4kbizhi.com/meinv/index.html
我们打开进行翻页
第一页:https://www.4kbizhi.com/meinv/index.html
第二页:https://www.4kbizhi.com/meinv/index_2.html
第三页:https://www.4kbizhi.com/meinv/index_3.html
根据上面我们可以发现其规律就是index_后变化的数字,根据这我们可以批量生成url
代码如下:
def Page_Urls(self):page_urls=[]start_page = input("请输入起始页数:")end_page = input("请输入结束页数:")for i in range(int(start_page),int(end_page)+1):if i == 1:st_url = "https://www.4kbizhi.com/meinv/index.html"page_urls.append(st_url)else:url = "https://www.4kbizhi.com/meinv/index_%d.html"%(i)page_urls.append(url)print("共拼接%d个页面url"%(len(page_urls)))return page_urls
二、获取图片链接
我们在上面已经拼接了页面url,现在我们需要根据页面获取每个图片的链接
我们在浏览器上右键 检查元素,利用XPath定位,可找到每个图片的链接和名称,如下图所示,据此可写代码
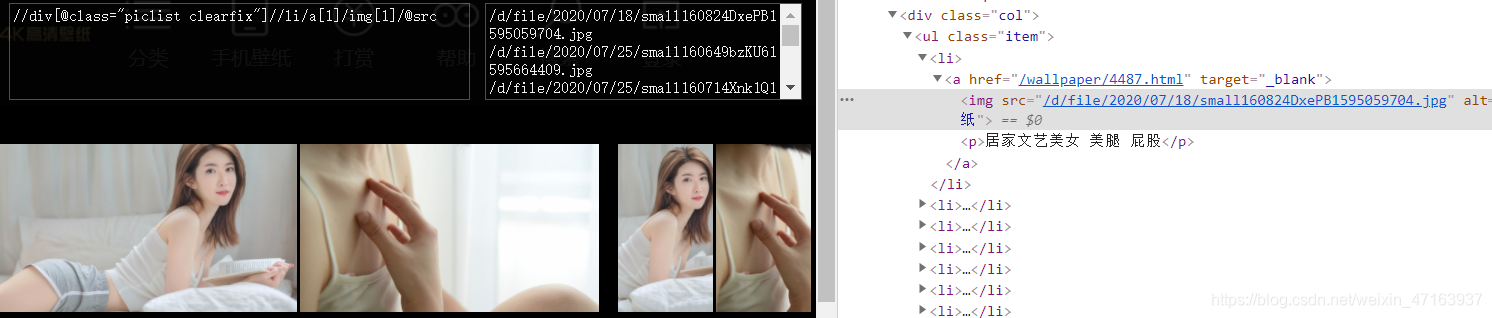
代码如下:
def Get_img_link(self,url):try:r=requests.get(url=url,headers=self.header)r.encoding="gbk"text=r.texthtml = etree.HTML(text)img_links=['http://www.4kbizhi.com/'+url for url in html.xpath('//div[@class="piclist clearfix"]//li/a[1]/img[1]/@src')]img_names=html.xpath('//div[@class="piclist clearfix"]//li/a[1]/img[1]/@alt')self.img_link_list.extend(img_links)self.img_name_list.extend(img_names)except Exception as e:print("第%s页获取图片链接出现错误:"%(url.split('index_')[-1].replace('.html',"")),e)pass
三、下载图片
第二步我们已经获取了图片的链接,现在我们只需要将其以二进制保存到本地,即实现下载
代码如下:
def Dowload_img(self,img_link,img_name):try:r = requests.get(url=img_link, headers=self.header).contentname = img_name + ".jpg"img_path = "4Kbizhi/" + namewith open(img_path, "wb") as f:f.write(r)except Exception as e:print("下载%s图片时出现错误:"%(img_name),e)pass
总结
三个函数,环环相扣,拼接页面url传递给获取图片链接函数,获取了图片链接,传递给下载图片函数
如果你对爬虫感兴趣,欢迎到我主页浏览,已经更新多个爬虫项目,文中所以源码均在“阿虚学Python”中,本篇源码回复“4K壁纸”获取

原创文章不易,如果觉得不错,点个赞是对原创博主最大的支持
转载请标明出处
本文来自互联网用户投稿,文章观点仅代表作者本人,不代表本站立场,不承担相关法律责任。如若转载,请注明出处。 如若内容造成侵权/违法违规/事实不符,请点击【内容举报】进行投诉反馈!