python3请求网页出现乱码
今天使用python脚本的requests请求一个网页,返回的内容出现了乱码,代码和现象如下图1:
import requestsdef do_post():r =requests.get("xxxxx")if r.status_code != requests.codes.ok:return Noneprint(r.text)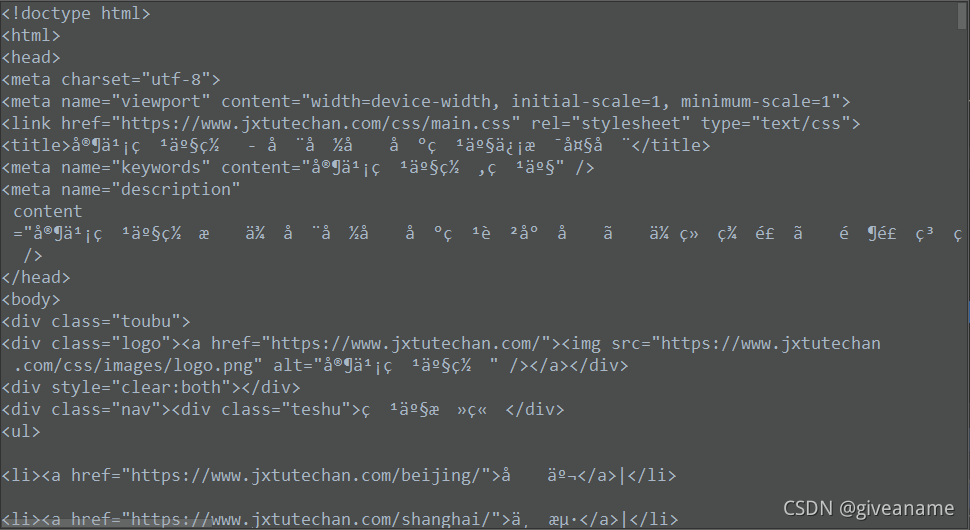
上网搜了解决方案,是页面编码问题导致的,在此做个记录。
1.较为规范的网页,都会在返回头中指明charset,即页面的编码。
比如,我们请求"必应"的首页,返回内容指明了页面编码是utf-8。

而有些网站没有返回charset内容,requests模块会默认其编码为"ISO-8859-1"。该编码显示英文页面没有问题,显示中文则乱码。
2.requests提供了几个参数和函数,可用于获取、记录、设置编码。
r.encoding:记录和设置页面的编码。如返回header里没有charset,则r.encoding = "ISO-8859-1"
r.apparent_encoding:记录了从返回内容中分析出的响应内容编码方式,猜测可能有些网页内容中指明了编码,如图1的第四行。
requests.utils.get_encodings_from_content:requests模块提供的一个函数,从body获取页面编码,注意内容必须是str格式。其功能和上面的差不多
r.content:二进制方式(即bytes方式)的页面响应内容,使用 r.encoding 记录的编码方式进行存储。因为是二进制数据,即一个byte作为一个单位记录信息。
r.text:字符串方式(即str方式)的页面响应内容,在python3中是unicode编码。
r.text和r.content我们可以看下requests的源码,如下:
@propertydef text(self):"""Content of the response, in unicode.If Response.encoding is None, encoding will be guessed using``chardet``.The encoding of the response content is determined based solely on HTTPheaders, following RFC 2616 to the letter. If you can take advantage ofnon-HTTP knowledge to make a better guess at the encoding, you shouldset ``r.encoding`` appropriately before accessing this property."""# Try charset from content-typecontent = Noneencoding = self.encodingif not self.content:return str('')# Fallback to auto-detected encoding.if self.encoding is None:encoding = self.apparent_encoding# Decode unicode from given encoding.try:content = str(self.content, encoding, errors='replace')except (LookupError, TypeError):# A LookupError is raised if the encoding was not found which could# indicate a misspelling or similar mistake.## A TypeError can be raised if encoding is None## So we try blindly encoding.content = str(self.content, errors='replace')return content可知在模块中,
- 判断 r.encoding 是否有值,有值则以此为转换编码
- 若r.encoding为None,则以 r.apparent_encoding 的值设置为转换编码
- 根据转换编码,将r.content 转为r.text
注意:python3中默认都是unicode编码,所以unicode编码转为其他编码是encode函数,反之是decode函数。
r.content和r.text可以通过decode/str函数和encode/bytes函数进行互转,即:
r.content.decode(r.encoding) == str(r.content,encoding=r.encoding) == r.text
r.text.encode(r.encoding) == bytes(r.text,encoding=r.encoding) == r.content
我们可以使用代码做下验证:
import requestsdef do_post():r =requests.get("xxxxx")if r.status_code != requests.codes.ok:return Noneprint("r.encoding:", r.encoding)print("r.apparent_encoding:", r.apparent_encoding)print("requests.utils.get_encodings_from_content:", requests.utils.get_encodings_from_content(r.text))print("content to text 1:", r.content.decode(r.encoding) == r.text)print("content to text 2:", str(r.content, encoding=r.encoding) == r.text)print("text to content 1:", r.text.encode(r.encoding) == r.content)print("text to content 2:", bytes(r.text, encoding=r.encoding) == r.content)打印结果:

3.综合1和2,得到结论和解决方法。
- 请求的页面没有返回charset,所以 r.encoding是默认的编码"ISO-8859-1"。
- 实际上,我们从r.apparent_encoding就可以知道,返回的页面是utf-8编码,所以 r.content 的内容是utf-8编码形式的二进制内容
- 因为 r.encoding 不对,r.text 对 r.content使用 ISO-8859-1 方式进行解码,得到的肯定是乱码
解决方法:
将 r.content 根据正确编码进行转换,或者将r.encoding设置为正确的utf-8内容。
import requestsdef do_post():r =requests.get("xxxxx")if r.status_code != requests.codes.ok:return Noneprint("r.encoding:", r.encoding)print("r.apparent_encoding:", r.apparent_encoding)print("requests.utils.get_encodings_from_content:", requests.utils.get_encodings_from_content(r.text))print("content to text 1:", r.content.decode(r.encoding) == r.text)print("content to text 2:", str(r.content, encoding=r.encoding) == r.text)print("text to content 1:", r.text.encode(r.encoding) == r.content)print("text to content 2:", bytes(r.text, encoding=r.encoding) == r.content)# 方法1,根据编码进行转换resp1 = r.content.decode(r.apparent_encoding)# print(r.text)# 方法2,设置页面的编码r.encoding = r.apparent_encodingresp2 = r.textprint("resp1 and resp2:", resp1 == resp2)print("++++++++++++++++++++++++++++++++++")print("resp:", resp1)输出结果,不乱码了:
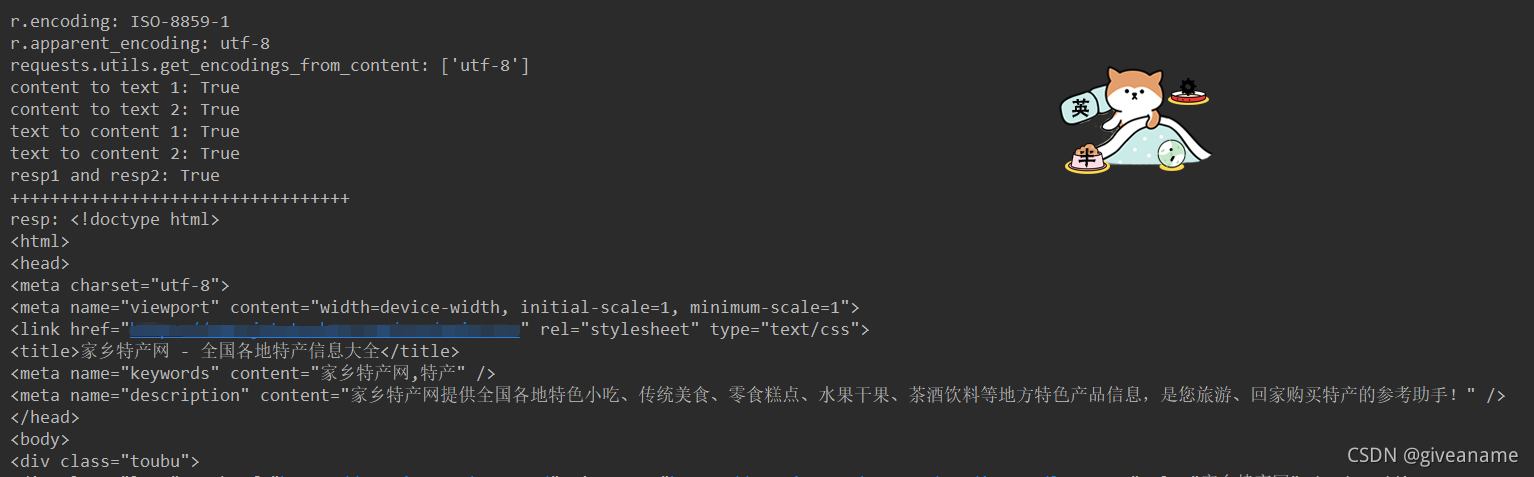
整理了很久,自己也算梳理清楚了。
ps:之前看到返回页面的 Content-Encoding是gzip,还以为是压缩导致的乱码。其实requests的r.content会自动解码 gzip 和 deflate 压缩。
pps:还有一种unicode-escape编码,是将unicode的内存编码值直接存储,在此只为做个提醒。
参考:python中unicode和unicodeescape - 开飞机的贝塔 - 博客园
本文来自互联网用户投稿,文章观点仅代表作者本人,不代表本站立场,不承担相关法律责任。如若转载,请注明出处。 如若内容造成侵权/违法违规/事实不符,请点击【内容举报】进行投诉反馈!