《神经网络和深度学习 学习笔记》(一)运行TensorFlow
文章目录
-
第9章 运行TensorFlow
2 创建一个计算图并在会话中执行
3 管理图
4 节点值的生命周期
5 TensorFlow中的线性回归
6 实现梯度下降
6.1 手工计算梯度
6.2 使用自动微分
6.3 使用优化器
7 给训练算法提供数据
8 保存和恢复模型
9 用TensorBoard来可视化图和训练曲线
10 命名作用域
11 模块化
12 共享变量
13 练习
1. 简介和安装
TensorFlow是一个用于数值计算的强大开源软件库,原理:
① 在python中定义个用来计算的图;
② TensorFlow使用这个图,并用优化的C++代码来执行计算。
比如,一个简单的计算 f ( x , y ) = x 2 y + y + 2 f(x,y)=x^2y+y+2 f(x,y)=x2y+y+2 ,其计算图如下:

重要的是,TensorFlow可以将一个计算图划分成多个子图,然后并行在多个CPU或GPU上执行。tf还支持分布式计算。比如,上面的例子, x 2 y x^2y x2y 和 y + 2 y+2 y+2可以分开,多CPU,多GPU,多服务器上 进行并行计算。
tf优势:设计清洗、扩展性、灵活性、文档完善。
具体特点:
① 跨平台:可运行在windows、Linux、mac和移动设备上(ios、Android);
② 提供TF.learn的python API 来兼容sklearn;
③ 提供TF-slim的简单API来简化神经网络的构建、训练和评估;
④ 在tf之上,独立构建了一些高级的API,比如Keras和Pretty Tensor;
⑤ 它的python API提供了很多灵活的方式(代价是很高复杂性)来创建所有类型的计算,包括所有你能想到的神经网络架构;
⑥ 通过它的API,可以用C++来实现自己的高性能操作;
⑦ tf会自动计算你定义的成本函数的梯度,这称为自动微分;
⑧ tensorboard可视化工具,用来浏览计算图,查看学习曲线等;
⑨ google还启动了一个运行TensorFlow计算图(https://cloud.google.com/ml)的云服务;
⑩ 社区活跃,开源代码GitHub
本章会将TensorFlow的基础知识,从安装、到创建、执行、保存、可视化的计算图。这些基础对构建自己的第一个神经网络非常重要。
2. 创建一个计算图并在会话中执行
import tensorflow as tfx = tf.Variable(3,name="x")
y = tf.Variable(4,name="y")
f = x*x*y + y + 2 # 仅仅创建了一个计算图
上面代码没有执行任何的计算,仅仅是创建了一个计算图而已。要执行这个图,需要打开一个TensorFlow的会话,然后用它来初始化变量并求值f。会话会将计算分发到诸如GPU和CPU上并执行,它还持有所有变量的值。
sess = tf.Session()
sess.run(x.initializer) #初始化
sess.run(y.initializer)
result = sess.run(f)
print(result)
sess.close()#更好的方式
#简化上面代码
with tf.Session() : # as sess:x.initializer.run()y.initializer.run()result = f.eval()#计算结果print(result)
这种写法:①增加可读性;②块中的代码执行结束后会话自动关闭。
除了手工初始化变量外,还可以设置全局的变量初始化。注意:它不会立刻做初始化,只是在图中创建了一个节点,这个节点会在会话执行时初始化所有变量。
#全局的初始化所有变量
init = tf.global_variables_initializer()
with tf.Session() as sess:init.run()result = f.eval()print(result)
总结,一个tf程序通常分为两部分:
① 构建阶段:用来构建一个计算图。这个图用来展现ML模型(假设函数)和训练所需的计算(损失函数)。
② 执行阶段:重复执行每一步训练动作,并逐步提升模型的参数。
3. 管理图
创建的所有节点都会添加到默认图上
x1 = tf.Variable(1)
x1.graph is tf.get_default_graph()

有时候可能会在同一个图上添加了很多重复节点,tf.reset_default_graph()来重置默认图。
4. 节点值的生命周期
当求值一个节点时,tf会自动检测该节点依赖的节点。
#tf会自动检测该节点的依赖的节点
w = tf.constant(3)
x = w + 2
y = x + 5
z = x * 3
with tf.Session() as s: # 执行阶段:计算图print(y.eval()) #级联传递计算:先找x,再找到w,发现w是常量3,则x = w + 2 =5,y=x+5=10print(z.eval())
注意:在单进程的tf中,即使它们共享同一个计算图,多个会话之间仍然互相隔离,不共享任何状态。对于分布式tf, 变量值保存在每个服务器上,而不是会话中,所以多个会话可以共享同一变量。
5. TensorFlow中的线性回归
输入和输出都是多维数组,叫作 张量。
import numpy as np
from sklearn.datasets import fetch_california_housingreset_graph()
housing = fetch_california_housing()
m, n = housing.data.shape
housing_data_plus_bias = np.c_[np.ones((m, 1)), housing.data]X = tf.constant(housing_data_plus_bias, dtype=tf.float32, name="X")
y = tf.constant(housing.target.reshape(-1, 1), dtype=tf.float32, name="y")
XT = tf.transpose(X) # X的转置
#根据标准方程直接求出theta = (Xt · X)的逆 · Xt · y
theta = tf.matmul(tf.matmul(tf.matrix_inverse(tf.matmul(XT, X)), XT), y) # matmul 矩阵相乘with tf.Session() as sess:theta_value = theta.eval()theta_value

上述代码跟我们之前用numpy实现的线性回归的区别是:如果我们有GPU,tf会把计算分发到GPU上去。
6. 实现梯度下降
6.1 手工计算梯度
#标准化
from sklearn.preprocessing import StandardScaler
scaler = StandardScaler()
scaled_housing_data = scaler.fit_transform(housing.data)
scaled_housing_data_plus_bias = np.c_[np.ones((m, 1)), scaled_housing_data]reset_graph()n_epochs = 2000
learning_rate = 0.01X = tf.constant(scaled_housing_data_plus_bias, dtype=tf.float32, name="X")
y = tf.constant(housing.target.reshape(-1, 1), dtype=tf.float32, name="y")
# ------------------ 先给定一个theta的初始值 --------------------- -1 到 1 之间 生成一个均匀分布矩阵
theta = tf.Variable(tf.random_uniform([n + 1, 1], -1.0, 1.0, seed=42), name="theta")
y_pred = tf.matmul(X, theta, name="predictions") # 预测值
error = y_pred - y #误差
mse = tf.reduce_mean(tf.square(error), name="mse") #mse
gradients = 2/m * tf.matmul(tf.transpose(X), error) #计算当前梯度
training_op = tf.assign(theta, theta - learning_rate * gradients)#在初始值的基础上,执行梯度下降,计算步长init = tf.global_variables_initializer() #设置全局变量初始化器best_theta = None
best_epoch = None
minimum_val_error = float("inf")with tf.Session() as sess:sess.run(init)#初始化变量for epoch in range(n_epochs):if epoch % 100 == 0:print("Epoch", epoch, "MSE =", mse.eval(),"当前theta的前2位:",theta.eval()[:2])if mse.eval() < minimum_val_error: #minimum_val_error = mse.eval()best_epoch = epochsess.run(training_op) #训练优化:迭代执行梯度下降best_theta = theta.eval() #得到最好的thetaprint("best_theta:",best_theta,"best_epoch:",best_epoch,"mse:",mse.eval())# best_theta

① random_uniform():在图中创建一个节点,这个节点生成一个张量,然后根据传入的shape和值域生成随机值填充这个张量。
② assign():创建一个为变量赋值的节点。比如,上例中,它实现了批量梯度下降 θ ( n e x t . s t e p ) = θ − η ∇ θ M S E ( θ ) \theta^{(next .step)} = \theta - \eta\nabla_\theta MSE(\theta) θ(next.step)=θ−η∇θMSE(θ) 。
6.2 使用自动微分
上面的代码可以很好的工作,但是需要从成本函数MSE中算出梯度。对于线性回归来说是很简单,但是要处理深度神经网络就很头疼了:过程会琐碎且容易出错。
TensorFlow的autodiff可以自动且高效的算出梯度。
reset_graph()n_epochs = 1000
learning_rate = 0.01X = tf.constant(scaled_housing_data_plus_bias, dtype=tf.float32, name="X")
y = tf.constant(housing.target.reshape(-1, 1), dtype=tf.float32, name="y")
theta = tf.Variable(tf.random_uniform([n + 1, 1], -1.0, 1.0, seed=42), name="theta")
y_pred = tf.matmul(X, theta, name="predictions")
error = y_pred - y
mse = tf.reduce_mean(tf.square(error), name="mse")#自动微分,计算梯度
gradients = tf.gradients(mse, [theta])[0]training_op = tf.assign(theta, theta - learning_rate * gradients)init = tf.global_variables_initializer()with tf.Session() as sess:sess.run(init)for epoch in range(n_epochs):if epoch % 100 == 0:print("Epoch", epoch, "MSE =", mse.eval())sess.run(training_op)best_theta = theta.eval()print("Best theta:")
print(best_theta)

gradients函数接受一个操作符(比如mse)和一个参数列表(theta)作为参数,然后创建一个操作符的列表来计算每个变量的梯度。所以,梯度节点将计算mse相对于theta的梯度向量。
四种自动计算梯度的方法:
① 数值微分:精度低,实现琐碎;
② 符号微分:精度高,构建一个完全不同的图;
③ 前向自动微分:精度高,基于二元树;
④ 反向自动微分:精度高,由TensorFlow实现。
TensorFlow使用反向的autodiff算法计算梯度,非常适用于多个输入和少量输出的场景(高效精确),在神经网络中这种场景非常常见。它只需要 n o u t p u t s + 1 n_{outputs}+1 noutputs+1 次遍历,就可以求出所有输出相对于输入的偏导。
6.3 使用优化器
计算梯度,tf提供了很多内置优化器,比如梯度下降优化器:
reset_graph()n_epochs = 1000
learning_rate = 0.01X = tf.constant(scaled_housing_data_plus_bias, dtype=tf.float32, name="X")
y = tf.constant(housing.target.reshape(-1, 1), dtype=tf.float32, name="y")
theta = tf.Variable(tf.random_uniform([n + 1, 1], -1.0, 1.0, seed=42), name="theta")
y_pred = tf.matmul(X, theta, name="predictions")
error = y_pred - y
mse = tf.reduce_mean(tf.square(error), name="mse")optimizer = tf.train.GradientDescentOptimizer(learning_rate=learning_rate)
training_op = optimizer.minimize(mse)init = tf.global_variables_initializer()with tf.Session() as sess:sess.run(init)for epoch in range(n_epochs):if epoch % 100 == 0:print("Epoch", epoch, "MSE =", mse.eval())sess.run(training_op)best_theta = theta.eval()print("Best theta:")
print(best_theta)

动量优化器,只要改一行代码
optimizer = tf.train.MomentumOptimizer(learning_rate=learning_rate,momentum=0.9)
7. 给训练算法提供数据
对于小批次梯度下降,每次迭代时用下一个小批量替换X和y的方法: 占位符节点。需要调用placeholder()。
reset_graph()A = tf.placeholder(tf.float32, shape=(None, 3))
B = A + 5
with tf.Session() as sess:B_val_1 = B.eval(feed_dict={A: [[1, 2, 3]]})B_val_2 = B.eval(feed_dict={A: [[4, 5, 6], [7, 8, 9]]})print(B_val_1)
要实现小批次梯度下降:
① 在构造阶段把X和y定义为占位符
reset_graph()X = tf.placeholder(tf.float32, shape=(None, n + 1), name="X")
y = tf.placeholder(tf.float32, shape=(None, 1), name="y")theta = tf.Variable(tf.random_uniform([n + 1, 1], -1.0, 1.0, seed=42), name="theta")
y_pred = tf.matmul(X, theta, name="predictions")
error = y_pred - y
mse = tf.reduce_mean(tf.square(error), name="mse")
optimizer = tf.train.GradientDescentOptimizer(learning_rate=learning_rate)
training_op = optimizer.minimize(mse)init = tf.global_variables_initializer()
② 定义批次的大小并计算批次的总数
n_epochs = 10 #迭代次数
batch_size = 100 # 每个批次的数量
n_batches = int(np.ceil(m / batch_size)) # 总的批次数
print(m)
③ 执行阶段,逐个获取小批次,通过feed_dict参数提供X和y的值。
def fetch_batch(epoch, batch_index, batch_size):np.random.seed(epoch * n_batches + batch_index) # # 根据总样本数m 和 批次数量 100 ,随机生成100个切分索引indices = np.random.randint(m, size=batch_size) # 切分索引, 随机生成 m是总的样本数print("indices",indices)X_batch = scaled_housing_data_plus_bias[indices] # 随机获取一个批次的Xy_batch = housing.target.reshape(-1, 1)[indices] # 随机获取一个批次的yreturn X_batch, y_batchwith tf.Session() as sess:sess.run(init)for epoch in range(n_epochs):for batch_index in range(n_batches):X_batch, y_batch = fetch_batch(epoch, batch_index, batch_size)sess.run(training_op, feed_dict={X: X_batch, y: y_batch})best_theta = theta.eval()

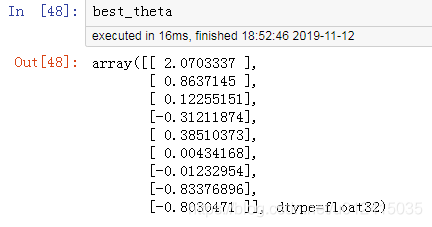
8. 保存和恢复模型
一旦训练好了模型,就需要将模型的参数保存到硬盘上。这样可以在任何时刻使用这些参数,可以在其他程序中使用,与其他模型做比较等。
tf中存取模型非常容易,创建一个saver节点即可。
reset_graph()n_epochs = 1000
learning_rate = 0.01 X = tf.constant(scaled_housing_data_plus_bias, dtype=tf.float32, name="X") # 常量X
y = tf.constant(housing.target.reshape(-1, 1), dtype=tf.float32, name="y") # 常量y
theta = tf.Variable(tf.random_uniform([n + 1, 1], -1.0, 1.0, seed=42), name="theta") # 给定theta初始值
y_pred = tf.matmul(X, theta, name="predictions") # 预测值: X · theta
error = y_pred - y # 误差
mse = tf.reduce_mean(tf.square(error), name="mse") # 均方误差mse
optimizer = tf.train.GradientDescentOptimizer(learning_rate=learning_rate) # 优化器计算梯度
training_op = optimizer.minimize(mse) # not showninit = tf.global_variables_initializer() #全局变量初始化器
saver = tf.train.Saver() # 创建saver节点with tf.Session() as sess:sess.run(init) # 初始化变量for epoch in range(n_epochs): #迭代if epoch % 100 == 0: # 每100轮打印信息,并保存当前的模型参数print("Epoch", epoch, "MSE =", mse.eval()) save_path = saver.save(sess, os.path.join(path_ckpt_model,"my_model.ckpt"))sess.run(training_op) # 执行计算best_theta = theta.eval() # 得到最好的thetaprint("best_theta:",best_theta)save_path = saver.save(sess,os.path.join(path_ckpt_model,"my_model_final.ckpt")) #保存最终的模型

恢复模型
with tf.Session() as sess:saver.restore(sess, os.path.join(path_ckpt_model,"my_model_final.ckpt"))best_theta_restored = theta.eval() # not shown in the bookbest_theta_restored

看,我们得到了之前训练好的模型的参数哦~~!~
默认的,saver也会保存图结构本身,保存在扩展名为.meta的文件中,可以使用tf.train.import_meta_graph()恢复图形结构,这个方法加载图结构并加入到默认的graph中,返回一个saver,saver可以恢复图的状态。
reset_graph()
# 注意:我们是从一个空的图开始的.saver = tf.train.import_meta_graph("/tmp/my_model_final.ckpt.meta") # 加载图形结构
theta = tf.get_default_graph().get_tensor_by_name("theta:0") # 获取thetawith tf.Session() as sess:saver.restore(sess, "/tmp/my_model_final.ckpt") # 恢复图的状态best_theta_restored = theta.eval() # best_theta_restored

9. 用Tensorboard来可视化图和训练曲线
用于可视化训练进度,比如学习曲线。
注意:每次运行程序时,都需要指定一个不同的目录,否则tensorboard会将这些状态信息合并起来,这会导致可视化结果变成一团糟。方法:利用时间戳生成不同的文件夹。
mse_summary = tf.summary.scalar('MSE', mse)
file_writer = tf.summary.FileWriter(logdir, tf.get_default_graph())n_epochs = 10
batch_size = 100
n_batches = int(np.ceil(m / batch_size))with tf.Session() as sess: # not shown in the booksess.run(init) # not shownfor epoch in range(n_epochs): # not shownfor batch_index in range(n_batches):X_batch, y_batch = fetch_batch(epoch, batch_index, batch_size)if batch_index % 10 == 0:summary_str = mse_summary.eval(feed_dict={X: X_batch, y: y_batch})step = epoch * n_batches + batch_indexfile_writer.add_summary(summary_str, step)sess.run(training_op, feed_dict={X: X_batch, y: y_batch})best_theta = theta.eval()
logdir下生成的日志文件:

将上面的日志文件怼到tensorboard中去展示,执行命令:tensorboard --logdir tf_logs/

计算图

总结:tensorboard其实主要的作用有2个: 可视化各种指标 学习曲线(偏应用) 和 可视化计算图(偏研究)
10. 命名作用域
神经网络等复杂模型,图很容易变得庞大且杂乱,所以引入命名作用域 将节点分组。比如,将mse ops 和error分到名为 'loss’的命名作用域中:
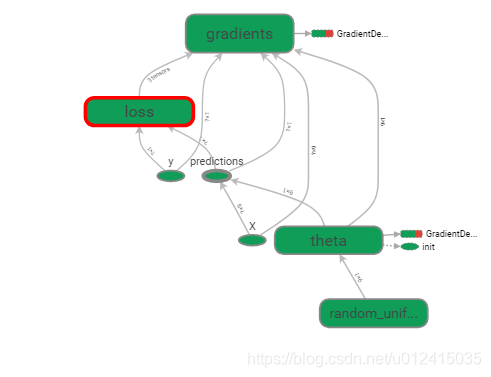
reset_graph()now = datetime.utcnow().strftime("%Y%m%d%H%M%S")
root_logdir = "tf_logs"
logdir = "{}/run-{}/".format(root_logdir, now)n_epochs = 1000
learning_rate = 0.01X = tf.placeholder(tf.float32, shape=(None, n + 1), name="X")
y = tf.placeholder(tf.float32, shape=(None, 1), name="y")
theta = tf.Variable(tf.random_uniform([n + 1, 1], -1.0, 1.0, seed=42), name="theta")
y_pred = tf.matmul(X, theta, name="predictions")with tf.name_scope("loss") as scope:error = y_pred - ymse = tf.reduce_mean(tf.square(error), name="mse")optimizer = tf.train.GradientDescentOptimizer(learning_rate=learning_rate)
training_op = optimizer.minimize(mse)init = tf.global_variables_initializer()mse_summary = tf.summary.scalar('MSE', mse)
file_writer = tf.summary.FileWriter(logdir, tf.get_default_graph())n_epochs = 10
batch_size = 100
n_batches = int(np.ceil(m / batch_size))with tf.Session() as sess:sess.run(init)for epoch in range(n_epochs):for batch_index in range(n_batches):X_batch, y_batch = fetch_batch(epoch, batch_index, batch_size)if batch_index % 10 == 0:summary_str = mse_summary.eval(feed_dict={X: X_batch, y: y_batch})step = epoch * n_batches + batch_indexfile_writer.add_summary(summary_str, step)sess.run(training_op, feed_dict={X: X_batch, y: y_batch})best_theta = theta.eval()file_writer.flush()
file_writer.close()
print("Best theta:")
print(best_theta)
11. 模块化
这里所说的模块化其实就是函数化 (复用),再结合命名作用域(即分组,分模块),使得代码和图更加清晰。
12. 共享变量
其实就是指的全局变量,类似于配置项,不要写死,可以是代码更加灵活。除了这种直接定义配置变量的方式之外,tf还提供了一种更加模块化,代码更清晰的方式:get_variable()函数 和 reuse属性。
reset_graph()def relu(X):with tf.variable_scope("relu"):threshold = tf.get_variable("threshold", shape=(), initializer=tf.constant_initializer(0.0))w_shape = (int(X.get_shape()[1]), 1)w = tf.Variable(tf.random_normal(w_shape), name="weights")b = tf.Variable(0.0, name="bias")z = tf.add(tf.matmul(X, w), b, name="z")return tf.maximum(z, threshold, name="max")X = tf.placeholder(tf.float32, shape=(None, n_features), name="X")
with tf.variable_scope("", default_name="") as scope:first_relu = relu(X) # 创建共享变量 thresholdscope.reuse_variables() # 复用它relus = [first_relu] + [relu(X) for i in range(4)]
output = tf.add_n(relus, name="output")file_writer = tf.summary.FileWriter("logs/relu8", tf.get_default_graph())
file_writer.close()
总结:我们将在后续章节中讨论更多的高级主题,特别是:深度神经网络、卷积神经网络、复发神经网络相关的操作,以及如何通过多线程、队列、多GPU、多服务器等对TensorFlow进行扩容。
本文来自互联网用户投稿,文章观点仅代表作者本人,不代表本站立场,不承担相关法律责任。如若转载,请注明出处。 如若内容造成侵权/违法违规/事实不符,请点击【内容举报】进行投诉反馈!