mysql实现删除某一列的重复数据(只留一行或全部删除)
事例数据库
其中 第一列为id(主键),弟2列为file_id,弟3列为file_name
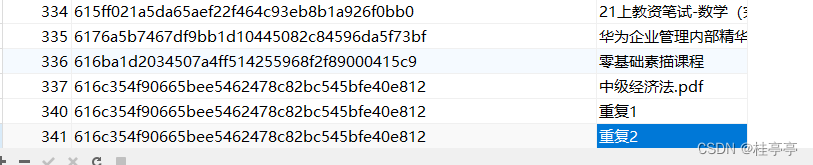
只包留一行
我们要想删除掉重复的数据
弟一步
先筛选出来哪些数据重复了?
我们可以先将表中的数据以目标字段(这里是file_id)进行分组聚类,然后找出每一组的最小ID(或最大ID)并将这些ID放入一个临时表t(可以随意命名这里是t)中
于是我们就有了以下代码
id:表的主键
klx.file_id_name:表名
file_id:包含重复项的字段
SELECT t.id FROM ((select MIN(id) id from klx.file_id_name group by file_id) as t)弟2步
通过第1步,我们已经找出了各行中最大的id值,并将它放到一个临时表t中了
这时候我们就可以想到,如果有一项是重复两次或以上的,那么此项应该有两个或以上不同的id值
而我们临时表存的只是最小的那个id值,反过来,如果有一项是不重复的,那么它应该有唯一的一个id值,并且这个id值,也一定是最小的id值,也一定在我们的临时表t中
于是:
其中关键字印是判断file_id_name表中的id是否在临时表t之中,如果不存在则将此项删除,这样我们就过滤掉了重复的项
DELETE FROM file_id_name WHERE id not in(SELECT t.id FROM ((select MIN(id) id from klx.file_id_name group by file_id) as t))结果截图

重复的全部删除(一项都不留)
代码如下
DELETE FROM WHERE SELECT t.file_id,t.count_ FROM ((select file_id,COUNT(file_id) count_ from klx.file_id_name group by file_id) as t) where t.count_>1本文来自互联网用户投稿,文章观点仅代表作者本人,不代表本站立场,不承担相关法律责任。如若转载,请注明出处。 如若内容造成侵权/违法违规/事实不符,请点击【内容举报】进行投诉反馈!