【计算机基础】计算机科学速成课
电子计算机系统的 抽象层次:
物理(电子)——>器件(晶体管、二极管)——>模拟电路(放大器、滤波器)——>数字电路(与门或门)——>逻辑(加法器、储存器)——>微体系结构(数据路径控制器)———>体系结构(指令寄存器)——>操作系统(设备驱动程序)——>应用软件(程序)
课程链接:
【https://www.bilibili.com/video/av21376839?p=1】
正文
第一课:计算机早期历史
0、课程目标:从高层次总览一系列计算机话题,快速入门计算机科学。
1、计算机技术的影响——进入信息时代
- 出现自动化农业设备与医疗设备
- 全球通信和全球教育机会变得普遍
- 出现意想不到的虚拟现实/无人驾驶/人工智能等新领域
2、计算机的实质:
极其简单的组件,通过一层层的抽象,来做出复杂的操作。
计算机中的很多东西,底层其实都很简单,让人难以理解的,是一层层精妙的抽象。像一个越来越小的俄罗斯套娃。
3、关于计算的历史:
- 公元前2500年,算盘出现,为十进制,功能类似一个计数器。
- 公元前2500年-公元1500年:星盘、计算尺等依靠机械运动的计算设备出现
- 公元1613年:computer的概念出现,当时指的是专门做计算的职业,
- 1694年:步进计算器出现,是世界上第一台能自动完成加减乘除的计算器。
- 1694-1900年:计算表兴起,类似于字典,可用于查找各种庞大的计算值。
- 1823年:差分机的设想出现,能近似多项式可以做函数计算,但计划最后失败,1991年差分机实现。
- 19世纪中期:分析机的设想出现,设想存在可计算一切的通用计算机,有内存,但未实现。
- 1890年:打孔卡片制表机。原理:在纸上打孔→孔穿过针→针泡入汞→电路连通→齿轮使计数+1。
第二课:电子计算机的发展史
1、电子计算机元器件变化:
继电器→真空管→晶体管:提高电路闭合速度。
继电器:用电控制的机械开关
控制线路:控制电路是开还是关,连着一个线圈,当电流流过线圈,线圈产生电磁场吸引金属臂,从而闭合电路。无法快速开关。

真空管:其中一个电极可以加热,从而发射电子;另一个电极会吸引电子,形成"电龙头"的电流。
但只有带正电才行,若带负电荷或中性电荷,电子无法被吸引,越过真空区域,因此没有电流。
二极管:电流只能单向流动的电子部件,缺少电流开关。
两电极之间加入第三个"控制"电极:向控制电极施加正电荷,允许电子流动;施加负电荷会组织电子流动(三级真空管)。

晶体管:它是一个开关,可用控制线路来控制开或关。
晶体管有两个电极,电极之间有一种材料隔开它们,这种材料有时导电有时不导电(半导体)。
控制线连到一个"门"电极,通过改变"门"的电荷可以控制半导体材料的导电性,来控制是否电流流动。

2、计算机的出现背景:
20世纪人口暴增,科学与工程进步迅速,航天计划成形。以上导致数据的复杂度急剧上升、计算量暴增,对于计算的自动化、高速有迫切的需求。
3、电子计算机的发展:
1944年 哈佛马克1:使用继电器,用电磁效应,控制机械开关,缺点为有磨损和延迟。
*1947.9哈弗马克2型最早还因为有虫子飞进去导致故障,引申出bug=故障的意思。
机电(马达、齿轮)—>电子
1943年 巨人1号:使用1600个真空管(三极管),制造出世界上第一个可编程的计算机。
1946年 ENIAC:第一个电子数值积分计算机,为第一台真正的通用计算机,每秒可执行5000次十位数加减法。
1947年 晶体管出现,使用的是固态的半导体材料,相对真空管更可靠。
1950年 空军AN/FSQ-71955: 真空管到达计算极限。
1957年 IBM 608: 第一个消费者可购买的晶体管计算机出现,3000个晶体管,每秒执行4500次加法,80次左右的乘除法。
第三课:布尔逻辑与逻辑门
1、计算机为什么使用二进制:
- 计算机的元器件晶体管只有2种状态,通电(1)&断电(0),用二进制可直接根据元器件的状态来设计计算机。
- 而且,数学中的“布尔代数”分支,可以用True和False(可用1代表True,0代表False)进行逻辑运算,代替实数进行计算。
- 计算的状态越多,信号越容易混淆,影响计算。对于当时每秒运算百万次以上的晶体管,信号混淆是特别让人头疼的的。
2、布尔代数&布尔代数在计算机中的实现
- 变量:没有常数,仅True和False这两个变量。
- 三个基本操作:
- NOT/AND/OR。
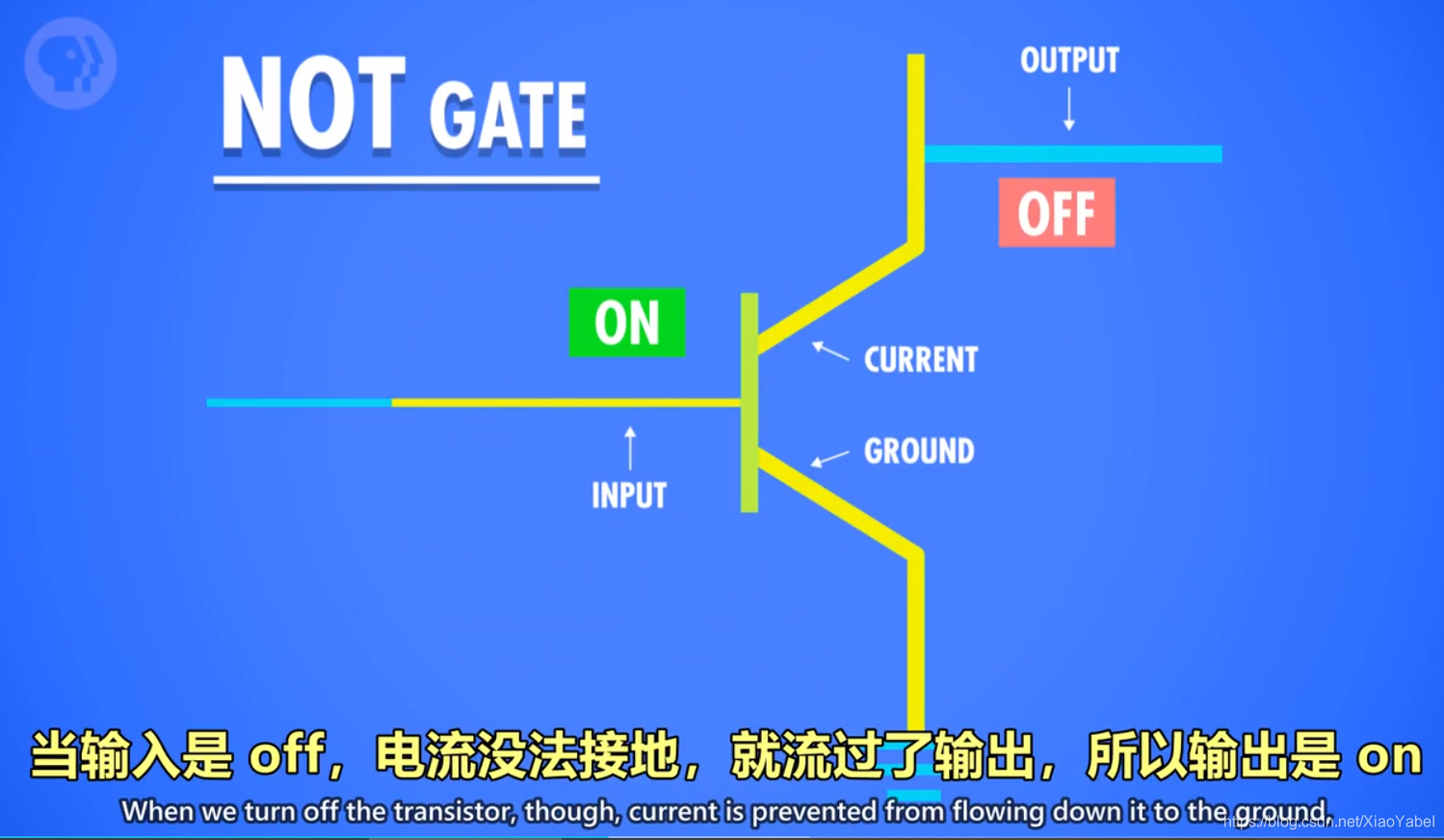
1)NOT操作:
1.命名:称为NOT门/非门。
2.作用:将输入布尔值反转。输入的True或False,输出为False或True。
3.晶体管的实现方式:
- 半导体通电True,则线路接地,无输出电流,为False。
- 半导体不通电False,无法接地,则输出电流从右边输出,为True。
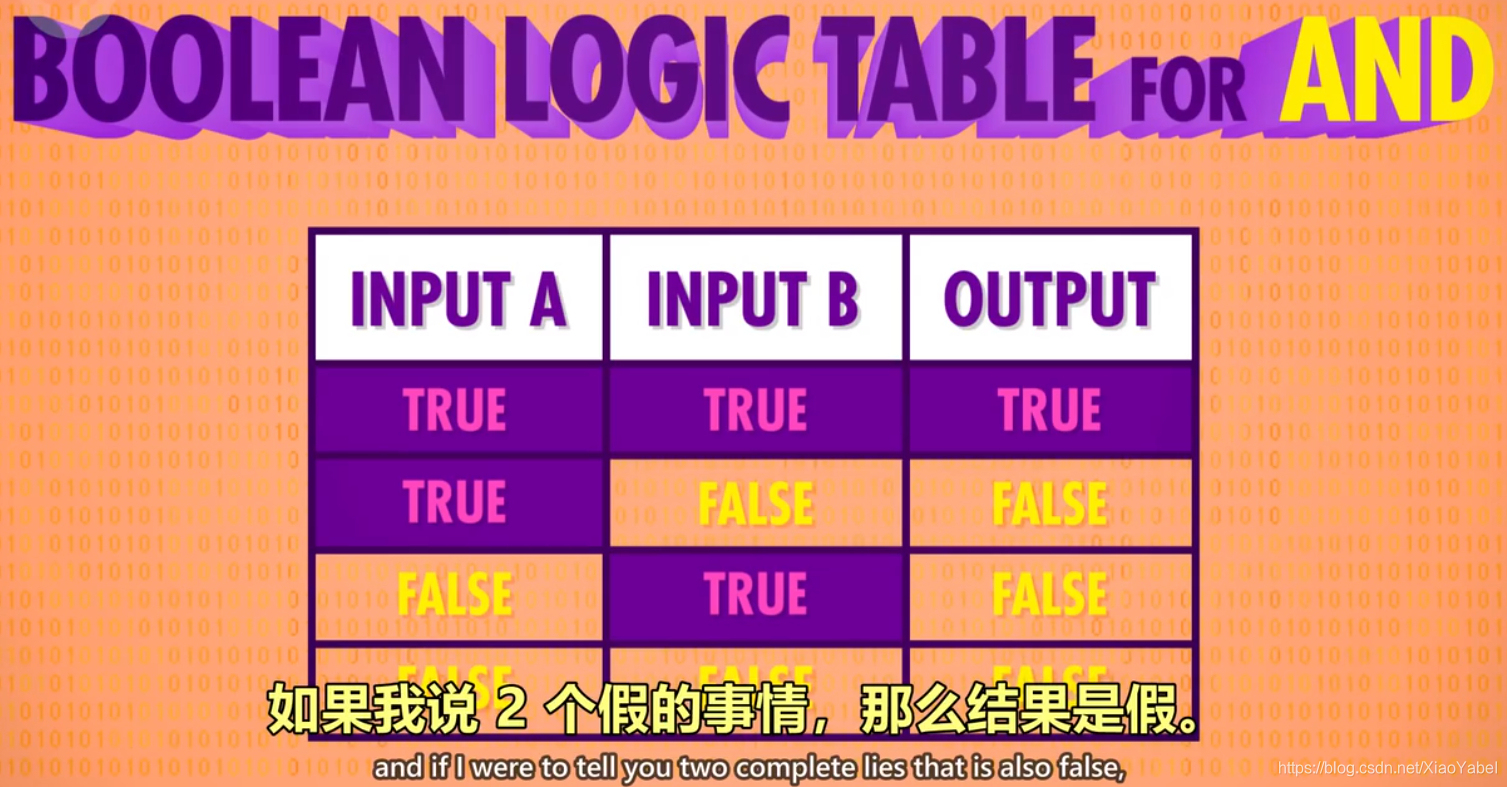
2)AND操作
1.命名:AND门/与门
2.作用:由2个输入控制输出,仅当2个输入input1和input2都为True时,输出才为True,2个输入的其余情况,输出均为False。
*可以理解为,2句话(输入)完全没有假的,整件事(输出)才是真的。
3.用晶体管实现的方式:
串联两个晶体管,仅当2个晶体管都通电,输出才有电流(True)

3)OR操作
1.命名:OR门/或门
2.作用:由2个输入控制输出,只要其中一个输入为True,则输出True。

3.用晶体管实现的方式:
使用2个晶体管,将它们并联到电路中,只要有一个晶体管通电,则输出有电流(True)。

3、特殊的逻辑运算——异或
1.命名:XOR门/异或门
2.作用:2个输入控制一个输出。当2个输入均为True时,输出False,其余情况与OR门相同,仅2个输入不同时输出True。
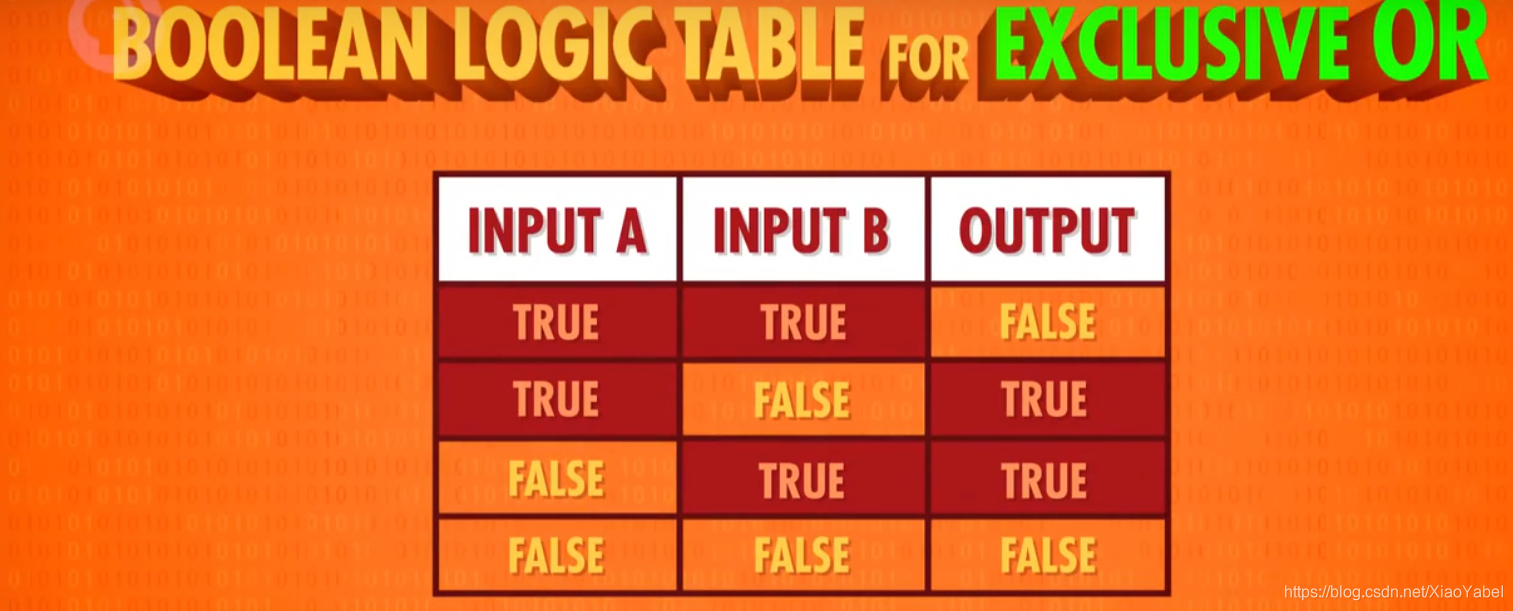
3.图示:
先用一个OR门,将其与AND门并联,AND门与NOT门串联,最后让NOT与AND门并联,获得输出。

4、逻辑门的符号表示
1.作用:将逻辑门简化,将逻辑门用于构建更大的组件,而不至于太复杂。
2.图示:
- 非门:用三角形+圆圈表示
- 与门:用D型图案表示
- 或门:用类似D向右弯曲的图案表示
- 异或门:用或门+一个圆弧表示




5、抽象的好处
使得分工明确,不同职业的工程师各司其职,而不用担心其他细节。
第四课:二进制
1、二进制的原理,存储单元MB/GB/TB解释
0.计算机中的二进制表示:
单个数字1或0,1位二进制数字命名为位(bit),也称1比特。
1.字节(byte)的概念:
1byte=8bit,即1byte代表8位数字。
最早期的电脑为八位的,即以八位为单位处理数据,2^8=256个取值(意味着八位机的游戏只有256种颜色)。为了方便,将八位数字命名为1字节(1byte).
2.十进制与二进制的区别:
- 十进制有10个数字,0-9,逢10进1(不存在10这个数字),则每向左进一位,数字大10倍。
- 二进制有2个数字,0-1,逢2进1,(不存在2这个数字),则每向左进一位,数字大2倍。
- 如何进行二进制与十进制联系起来:
- 将十进制与二进制的位数提取出来,编上单位:
eg.二进制的1011=1*2^0 + 0*2^1 + 1*2^2 + 1*2^3= 14(从右往左数)
eg.十进制的1045= 1*10^3 + 0*10^2 + 4*10^1 + 5*10^0
3.十进制与二进制的图示:
十进制的263

二进制的10110111
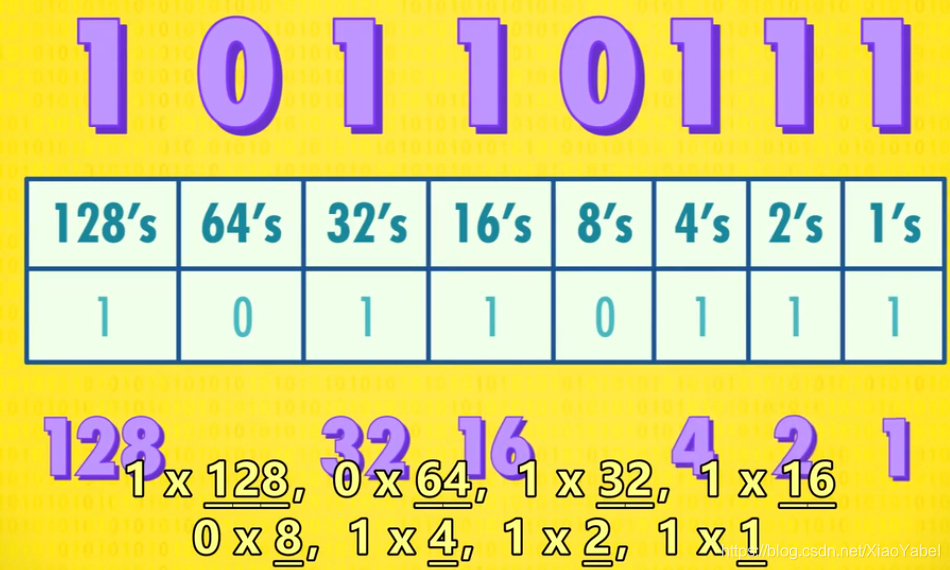
4.二进制的运算:
相同的位数相加,逢2进1

5. byte在电脑中的单位换算:
1kb=2^10 = 1024byte =1000byte
1TB=1000GB
1GB=十亿字节=1000MB=10^6KB
8bit(位)=1Byte(字节)
1024Byte(字节)=1KB
1024KB=1MB
1024MB=1GB
1024GB=1TB
6. 32位与64位电脑的区别
32位的最大数为43亿左右2*10^32=4,294,967,295=4G左右
64位的最大数为9.2*10^18
2、正数、负数、正数、浮点数的表示
1)计算机中表示数字的方法
1.整数:
表示方法:
- 第1位:表示正负 1是负,0是正(补码)
- 其余31位/63位: 表示实数
2.浮点数(Floating Point Numbers):
定义:小数点可在数字间浮动的数(非整数)
表示方法:IEEE 754标准下
用类似科学计数法的方式,存储十进制数值
- 浮点数=有效位数*指数
- 32位数字中:第1位表示正负,第2-9位存指数。剩下23位存有效位数
eg.625.9=0.6259(有效位数)*10^3(指数)
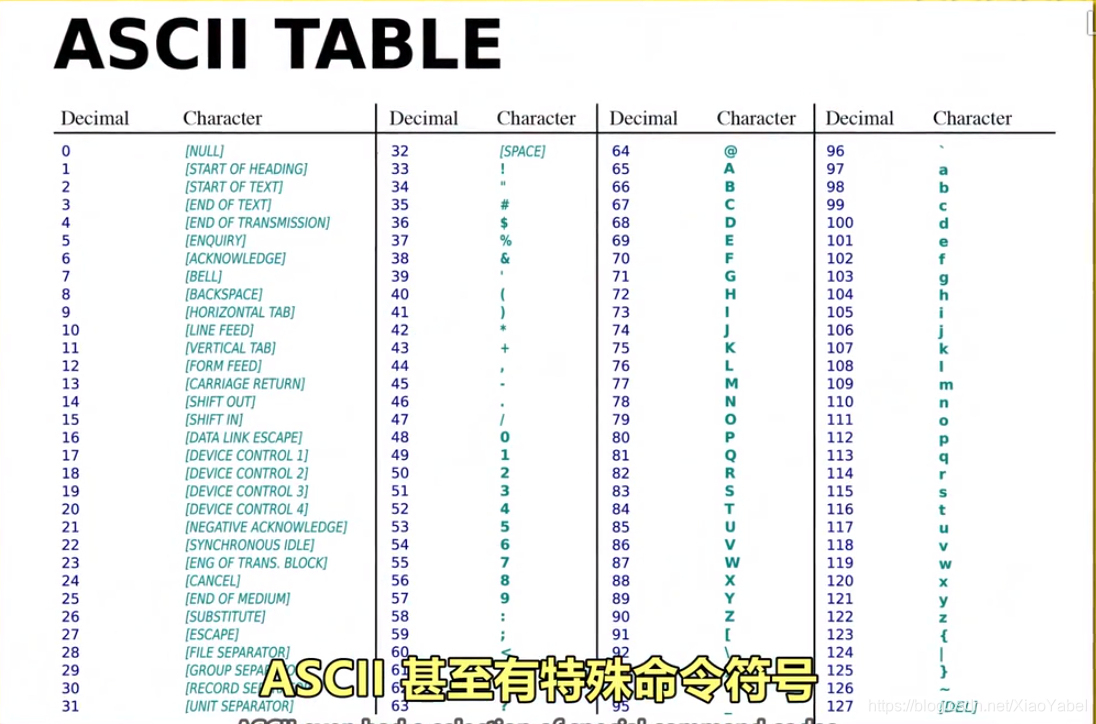
3、美国信息交换标准代码-ASCⅡ,用来表示字符
1.全称:美国信息交换标准代码
2.作用:用数字给英文字母及符号编号
3.内容:7位代码,可存放128个不同的值。
4.图示:
4、UNICODE,统一所有字符编码的标准
1.诞生背景:1992诞生,随着计算机在亚洲兴起,需要解决ASCⅡ不够表达所有语言的问题。
为提高代码的互用性,而诞生的编码标准。
2.内容:UNICODE为17组的16位数字,有超过100万个位置,可满足所有语言的字符需求。
第五课:算术逻辑单元
1、什么是算术逻辑单元
1.命名:简称ALU,Arithmetic&Logic Unit
2.组成:ALU有2个单元,1个算术单元和1个逻辑单元(Arithmetic Unit和Logic Unit)
3.作用:计算机中负责运算的组件,处理数字/逻辑运算的最基本单元。
2、算术单元
负责计算机里的所有数字操作
1)基本组件:
- 由半加器、全加器组成
- 半加器、全加器由AND、OR、NOT、XOR逻辑门组成
2)加法运算
1.组件:AND、OR、NOT、XOR逻辑门
2.元素:输入A,输入B,输出(均为1个bit,即0或1)
ps:1true,0false二进制加法的输入和输出,和XOR门的逻辑完全一样,即可以把XOR用作1位加法器(电路设计思路)
3.半加器:
- 作用:用于计算个位的数字加减。
- 输入:A,B(都是1位)
- 输出:总和,进位
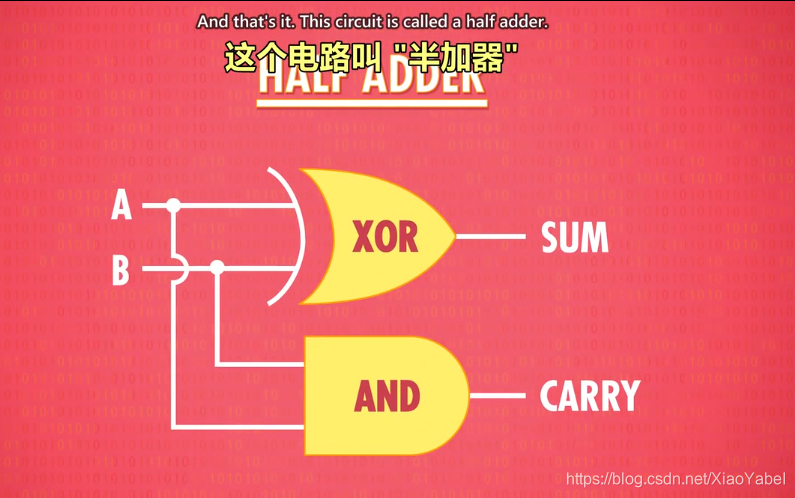
- 抽象成一个组件运用:
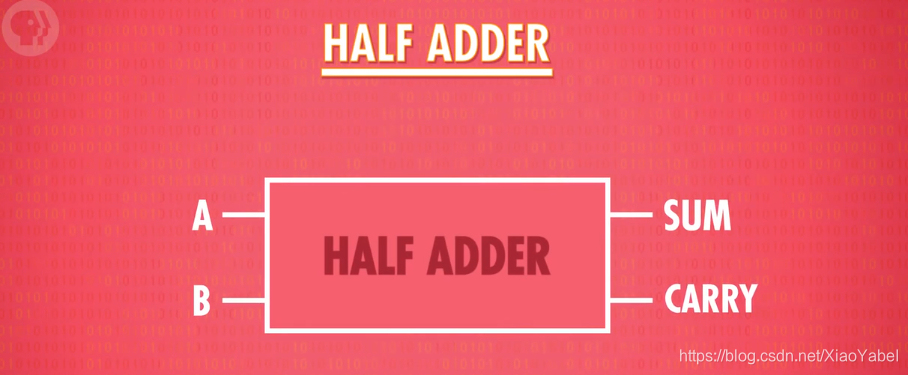
4.全加器:
- 作用:用于计算超过1位的加法,由于涉及进位,因此有3个输入(C充当进位)
- 3个输入:A,B,C(都是1个bit)
- 两条输出线:总和,进位
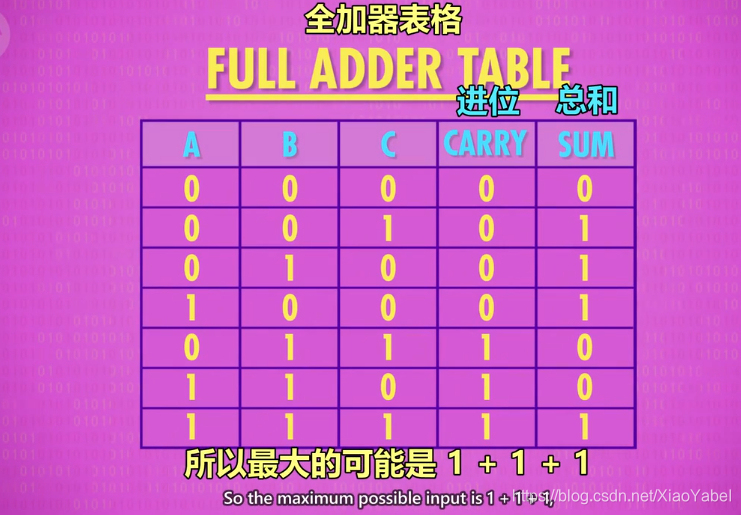
半加器制作全加器,原理图示:

抽象全加器:

3)如何用半加器与全加器做8位数的加法
1.说明:以8位行波加法器为例
- 用半加器处理第1位数(个位)的加法,得到的和为结果的第1位。
- 将输出的进位,输入到第2位用的全加器的输入C中。
- 将第2位的2个数用全加器计算,得到的和为结果的第2位(sum)。
- 将第2位计算的进位连接到百位的全加器输入C中。
在第3-8位上,循环第3-4步的操作。
*现在电脑使用的加法器叫“超前进位加法器”

4)算术单元支持的其他运算

专门做乘法的算术单元,更多的逻辑门来实现,处理器性能更优。
3、溢出的概念
内容:在有限的空间内,无法存储位数过大的数,则称为溢出。(两个数字的和太大了,超过了用来表示的位数)
说明:第8位的进位如果为1(第9位有进位),则无法存储,此时容易引发错误,所以应该尽量避免溢出。
4、逻辑单元
作用:执行逻辑操作,如NOT、AND、OR等操作,以及做简单的数值测试。
比如:一个数字是否是负数。
5、ALU的抽象
1)74181用了70个逻辑门,但不能执行乘除
8位ALU需要数百个逻辑门
作用:ALU的抽象让工程师不再考虑逻辑门层面的组成,简化工作。(输入二进制,会执行计算)
2)图示:
抽象成符号像一个大“V”。

3)说明:
图示内容包括:
- 输入A,B
- 输出
- 标志:溢出、零、负数(高级ALU有更多标志)
- 算数结果为负,“负数标志”才是真
- 作差比较法

第六课 寄存器与内存
0、课程导入
当玩游戏、写文档时如果断电,进度会丢失,这是为什么?
- 损失数据的原因是这是电脑使用的是RAM(随机存取存储器),俗称内存,内存只能在通电情况下存储数据。
- 另一种存储(memory)叫持久存储,电源关闭时数据也不会丢失,存其他东西。
- 先由只能存储1位的电路再扩大,做出内存模块,和ALU结合起来做出CPU。
1、概念梳理
- 此前电路都是单向的,向前流动——>可以回向电路,输出连回输入
永久记录1

永久记录0
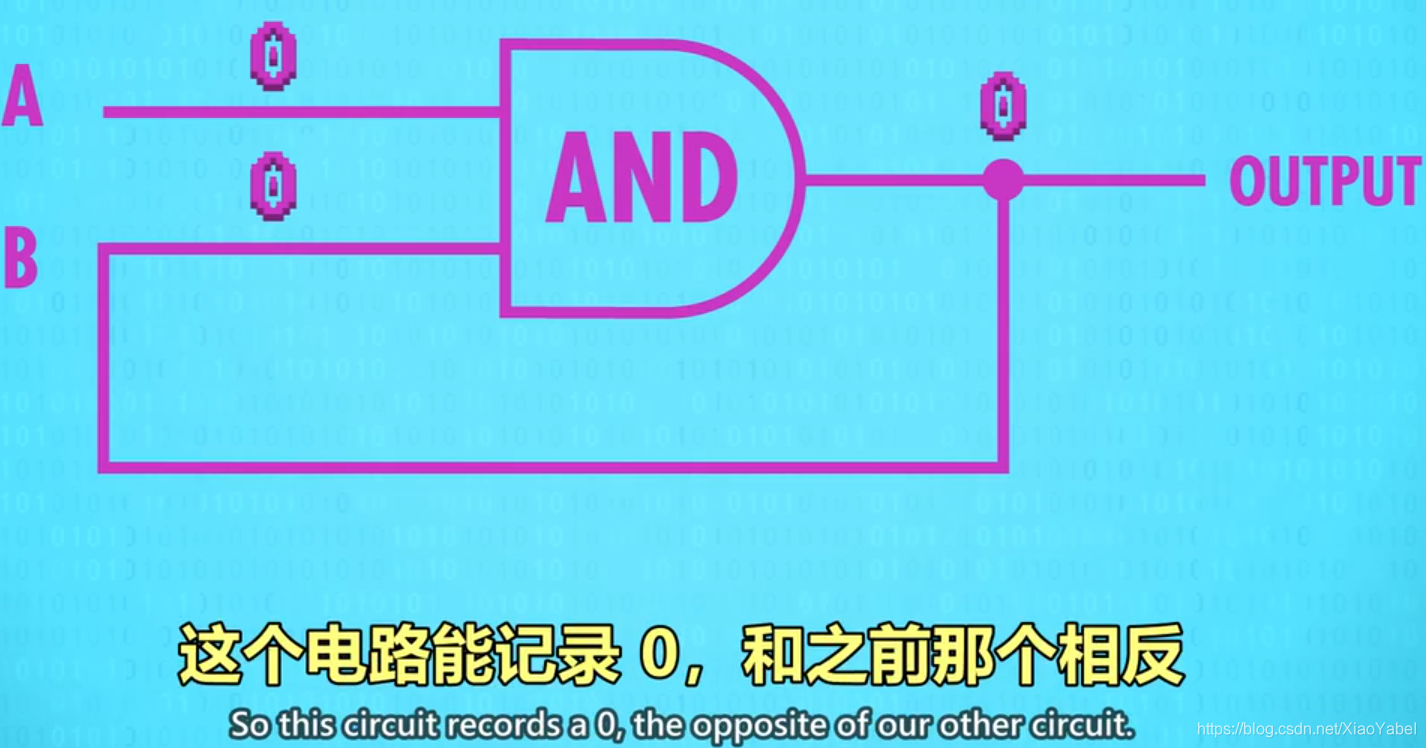
有用的存储,把两个电路结合起来
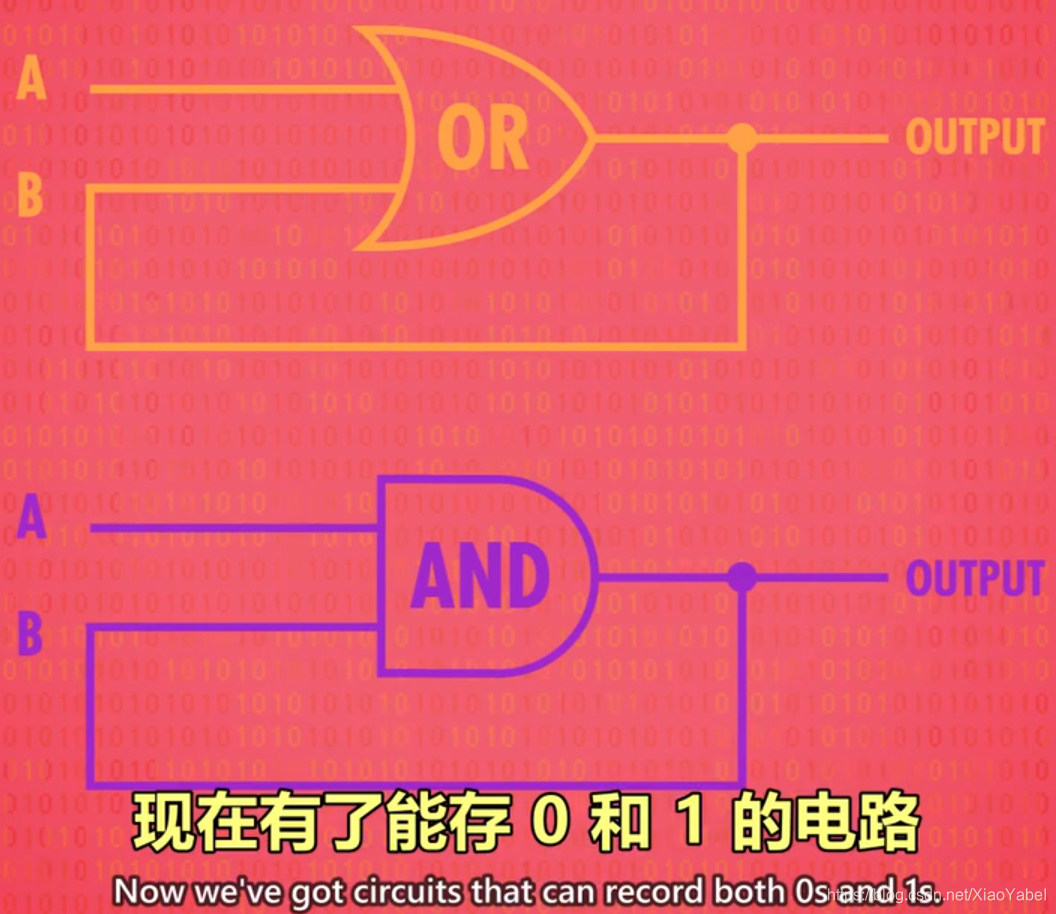
- 锁存器:锁存器是利用AND、OR、NOT逻辑门,实现存储1位数字的器件。
- 寄存器:1组并排的锁存器。(并排放8个锁存器,存8位信息)
- 寄存器能存一个数字,这个数字有多少位,叫"位宽"。
- 矩阵:以矩阵的方式来存放锁存器的组合件,n*n门锁矩阵可存放n^2个锁存器,但同一时间只能写入/读取1个数字。(早期为16*16矩阵)
- 启用某个锁存器,就打开相应的行线和列线。
- 位址:锁存器在矩阵中的行数与列数。
- 唯一指定'交叉路口"地址 eg.12行 8列
- 2^4>12,最多16行,4位就够12=【1100】,8=【1000】,12行 8列=【1100 1000】,地址的行列转换。
- 多路复用器:一组电线,输入2进制的行址&列址,可启用矩阵中某个锁存器
- 内存(RAM):随机存取存储器,由一系列矩阵以及电路组成的器件,可根据地址来写入、读取数据。类似于人类的短期记忆,记录当前在做什么事情。
2、锁存器
作用:存储1位的电路,"锁定"了一个值。
写入:放入数据
读取:拿出数据
图示:
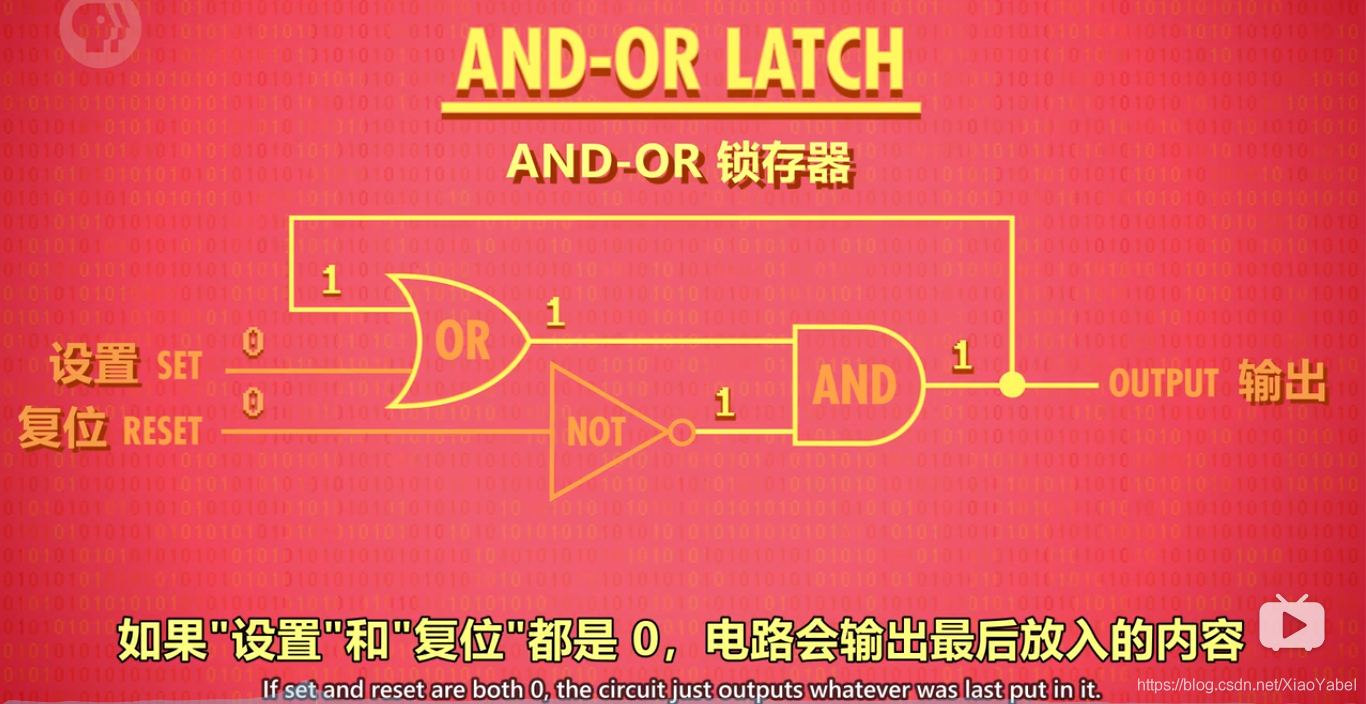
2.5、门锁:
锁存器需要同时输入2个数字,不太方便。
为了使用更方便,只用1根电线控制数据输入(将它设为0或1来存储值),发展了门锁这个器件。
另外,用另一根电线来控制整个结构的开关(“启用”内存),启用时允许写入,没启用时就"锁定"。(和复位作用不同)

抽象:
把"门锁"放到盒子里,这个盒子能存一个bit
- 允许写入0(锁门):无论数据输入如何,数据输出不会改变
- 允许写入1(开门):数据输入改变数据输出,关闭允许写入,数据即存储。

3、寄存器
作用:并排使用门锁,存储多位数字
图示:
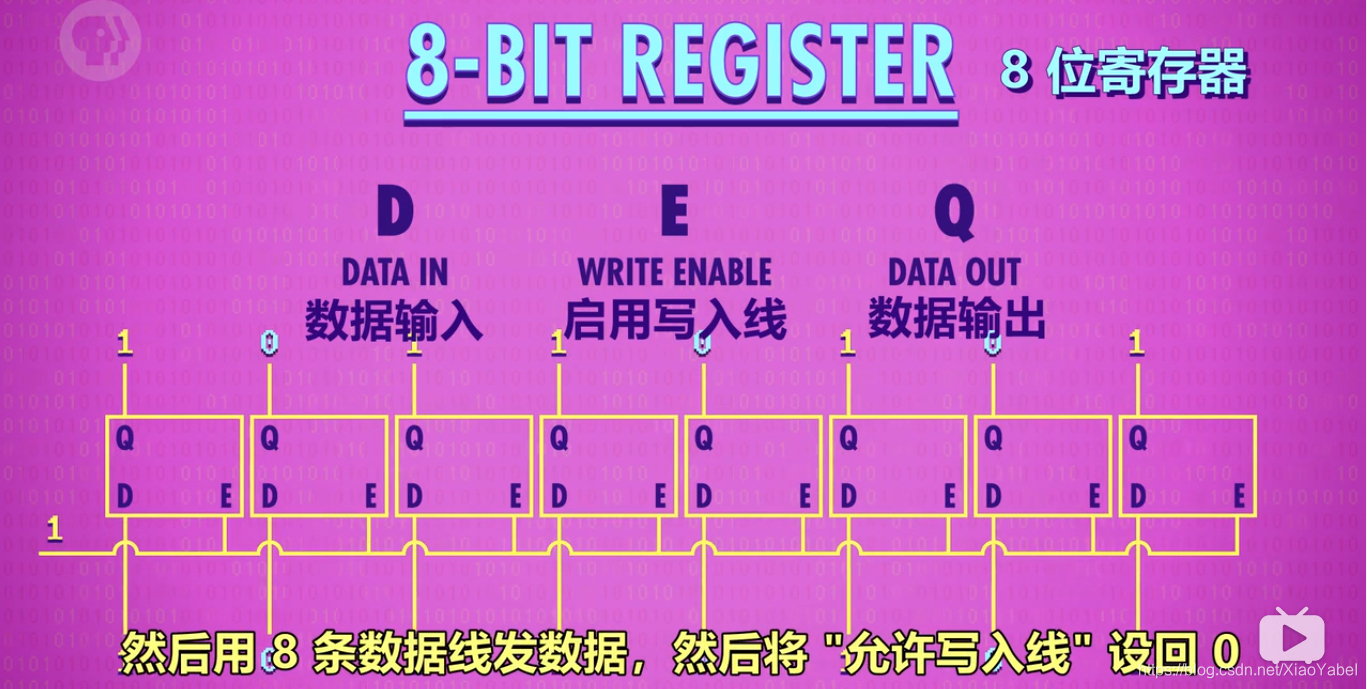
写入寄存器前,要先启用里面所有锁存器,E=1
然后用8条D数据线发数据,然后将"允许写入线"E设回0,8位值即存起来。
8D+8Q+1E=17根线
4、门锁矩阵
作用:
n*n的矩阵有n^2个位址,则可以存储n^2个数。但1个矩阵只可记录1位数字,n个矩阵组合在一起,才可记录n位数。如1个8位数,会按位数分成8个数,分别存储在8个矩阵的同一个位址中。
8个矩阵,则可以记录256个8位数字。
通俗理解:
16*16的门锁矩阵,可理解为1个公寓,1个公寓256个房间。
8个门锁矩阵并排放,则有了8个公寓。
规定每一个公寓同一个编号的房间,都有一样的标记(地址),共同组成8位数字。
那么8个公寓就能存 (8*256 / 8)个数字。
原因:
16*16的门锁矩阵虽然有256个位置,但每次只能存/取其中1个位置的数字。因此,要表示8位数字,就需要同时调用8个门锁矩阵。
图示:

- 启用某个锁存器,就打开相应的行线和列线。
- 打开交叉处,存储器的"允许写入线",所有其他锁存器,保持关闭
- 可选择当个锁存器,这种行/列排列,用一根"允许写入线"连所有锁存器。锁存器为允许写入,行列必须均为1。
- 实现可以只用一根"数据线"连所有锁存器来传数据(因为只有一个锁存器会启用,只有那个会存数据。其他锁存器会忽略数据线上的值因为没有"允许写入")
- 256位存储只要35条线(【1数据线+1允许写入线+1允许读取线】控制矩阵线+32矩阵线选择锁存器)

4.5、多路复用器
工作方式:
16行,需要1到16多路复用器。输入一个4位数字(二进制),它会把那根线,连到相应的输出线。一个多路复用器处理行;另一个多路复用器处理列。
使用方法:
在多路复用器中输入位址,x行x列(2进制),即可点亮x行x列的锁存器。

举例:
| 行列数 | 矩阵1 | 矩阵2 | 矩阵3 | 矩阵4 | 矩阵5 | 矩阵6 | 矩阵7 | 矩阵8 |
| 1行5列 | 1 | 0 | 1 | 1 | 0 | 0 | 1 | 0 |
| 2行3列 | 0 | 1 | 0 | 0 | 1 | 1 | 0 | 1 |
256位内存抽象当成一个整体:
- 输入一个8位地址:4位代表列,4位代表行;需要"允许写入线""允许读取线";还需要一条数据线,用于读/写数据。
- 256位内存像寄存器一样并排放置,一行8个,可以存一个8位数字(1byte)
- 为了存一个8位数字,同时给8个256位内存一样的地址,每个地址存1位,总共能存256个字节(byte)
- 看成一个整体的可寻址内存

5、内存
粗略定义:将一堆独立的存储模块和电路看做1个单元,组成内存方块,n个内存方块组成内存模块。在一个电路板上所有的内存方块统称为内存(RAM)。
- 一个memory只能存一个bit位,由于地址线、允许写入线、允许读取线是共用的,意味着对每个memory的同一地址进行读取、写入操作。
- 数据的写入、读取是单独分开的,从而实现一个8位数(二进制)的存储。
- 256个内存地址(0-255),每个地址能读或写一个8位值(8个256位内存)。
内存特性:可以随时访问任何位置
图示:

1980年内存RAM条:
128*64=8192位

- 锁存器实现SRAM(静态随机存取存储器)
- DRAM、闪存、NVRAM,用不同的电路存单个位(不同的逻辑门,电容器,电荷捕获或忆阻器)
- 矩阵层层嵌套,来存储大量信息。
第七课 中央处理器(CPU)
1、概念梳理
- CPU(Central Processing Unit):中央处理单元,负责执行程序,程序由一个个操作组成(这些操作叫指令)。
- 通常由寄存器/控制单元/ALU/时钟组成。与RAM配合,执行计算机程序。
- CPU和RAM之间用“地址线”、“数据线”和“允许读/写线”进行通信。
- 指令:指示计算机要做什么,多条指令共同组成程序。如数学指令(加/减)CPU会让ALU进行数学运算;内存指令,CPU和内存通信,然后读/写。
- 微体系架构:CPU有很多组件,重点放在功能,而不是一根根线具体怎么连。当用一条线连接两个组件时,这条线只是所有必须线路的一个抽象,是一种高层次视角。
- 时钟:负责管理CPU运行的节奏,以精确地间隔,触发电信号,控制单元用这个信号,推动CPU的内部操作。
- 时钟速度:CPU执行“取指令→解码→执行”中每一步的速度叫做“时钟速度”,单位赫兹Hz,表示频率。
- 超频/降频:
- 超频,修改时钟速度,加快CPU的速度,超频过多会让CPU过热或产生乱码。
- 降频,降低时钟速度,达到省电的效果,对笔记本/手机很重要。
2、CPU工作原理
1)必要组件:
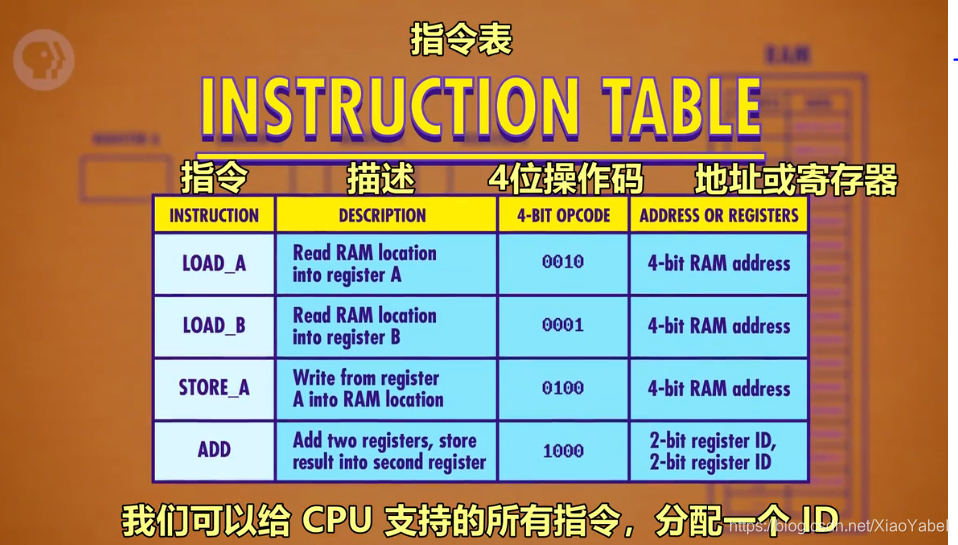
- 指令表:给CPU支持的所有指令分配ID
- 0010:LOAD_A将RAM地址为后4位的二进制值存入寄存器A
- 0001:LOAD_B将RAM地址为后4位的二进制值存入寄存器B
- 0100:STORE_A将寄存器A的值放入内存
- 1000:ADD后4位,2位2位分别代表2个寄存器,前2位代表的寄存器的值,加到后2位代表的寄存器里
- 读取---》读取---》相加---》存储
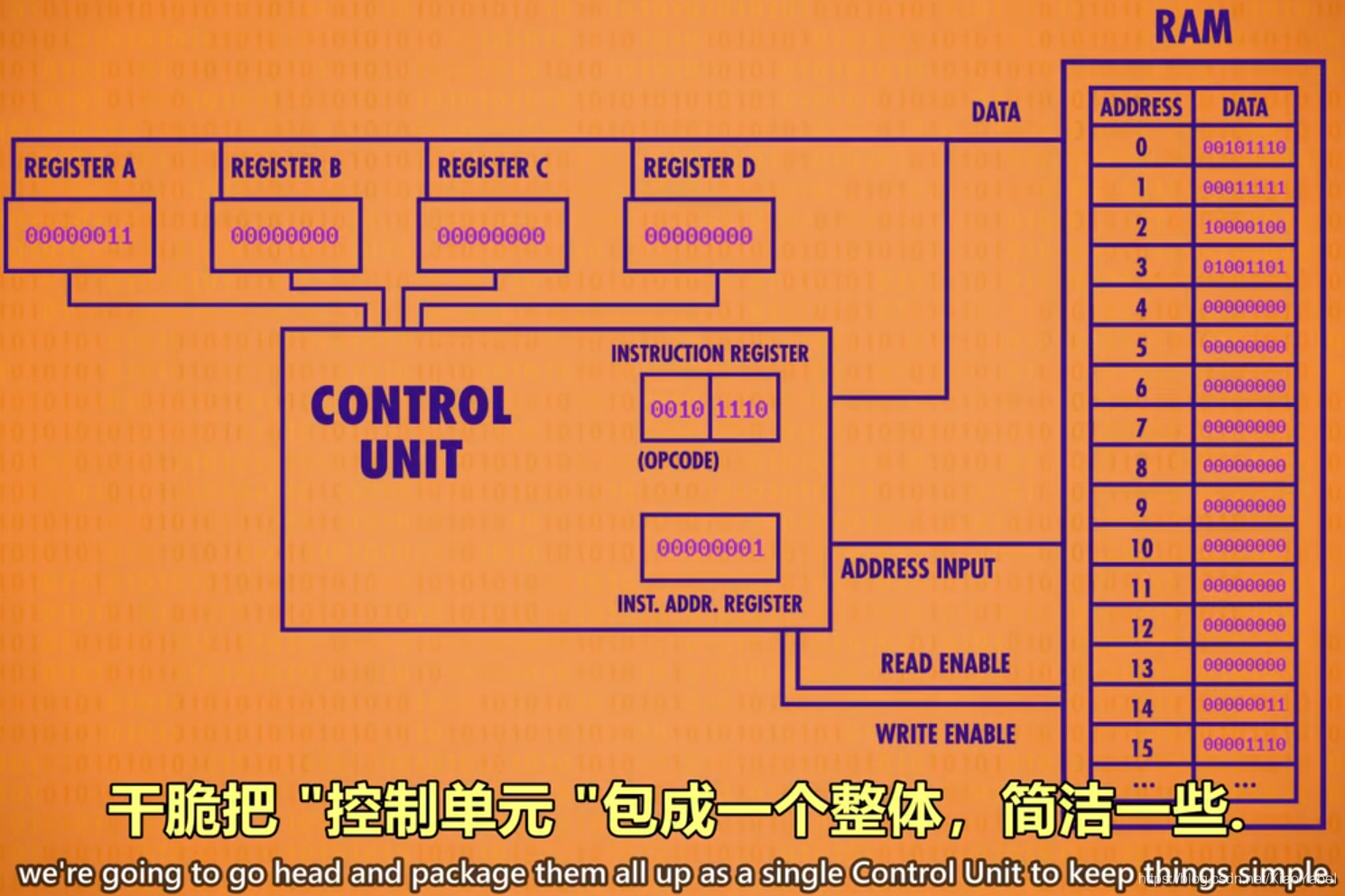
- 控制单元:像指挥部指挥CPU所有组件,有序的控制指令的读取、运行与写入。
- 指令地址寄存器:追踪程序运行到哪里了,存当前指令的内存地址。类似于银行取号。该器件只按顺序通报地址,让RAM按顺序将指令交给指令寄存器。
- 指令寄存器:存当前指令,存储具体的指令代码。
- CPU假设配置前提:
- RAM内存
- 4个8位寄存器ABCD:临时存数据和操作数据
- 数据以二进制存在内存,程序同样可以
- 给CPU支持的所有指令,分配一个ID,用前四位存“操作代码”(操作码)后四位代表数据来自哪里(可以是寄存器或内存地址)
- 还需2个寄存器,完成cpu。即:指令地址寄存器和指令寄存器
2)过程
当启动计算机时,所有寄存器从0开始,假设在RAM里放了一个程序。
- CPU的第一个阶段(取指令阶段)
- 取指令:负责拿到指令。
- 指令地址寄存器发地址给RAM→RAM发该地址内的数据给指令寄存器→指令寄存器接受数据
- 首先,将"指令地址寄存器"连到RAM,"指令地址寄存器"值为0因此RAM返回地址0的值,即0010 1110会复制到指令寄存器里
- 指令拿到了,要弄清是什么指令,才能执行,而不是kill,这是解码阶段。

- 解码:指令寄存器根据数据发送指令给控制单元 →控制单元解码(逻辑门确认操作码)
- 前4位0010是LOAD_A指令:把RAM的值放入寄存器A。(把地址为后4位(十进制)的8位二进制放入寄存器A)
- 后4位1110是RAM的地址,转成十进制是14
- 接下来,指令由“控制单元”进行解码
- 控制单元也是逻辑门组成的
- 比如,为了识别“LOAD_A”指令需要一个电路,检查操作码是不是0010,可用很少的逻辑门实现,即:知道了是什么指令就可以,开始执行了。

- 执行阶段:控制单元执行指令(→涉及计算时→调用所需寄存器→传输入&操作码给ALU执行)→调用RAM特定地址的数据→RAM将结果传入寄存器→指令地址寄存器+1
- 用检查是否是 LOAD_A指令的电路,可以打开RAM的“允许读取线”,把地址14传过去
- RAM拿到地址14的值:0000 0011(十进制的3)
- 因为是LOAD_A指令,需要把这个值只放到寄存器A,其他寄存器不受影响,所以需要一根线,把RAM连到4个寄存器,用“检查是否LOAD_A指令的电路”启用寄存器A的“允许写入线”
- 成功把RAM地址14的值,放到了寄存器A,指令完成,关掉线路拿下一条指令
- “指令地址寄存器”+1,"执行阶段"就此结束

- 取指令--->解码--->执行
3)必要组件:
不同指令由不同逻辑电路解码,这些逻辑电路会配置CPU内的组件来执行对应操作,具体解码电路比较繁琐
把“控制单元”包成一个整体
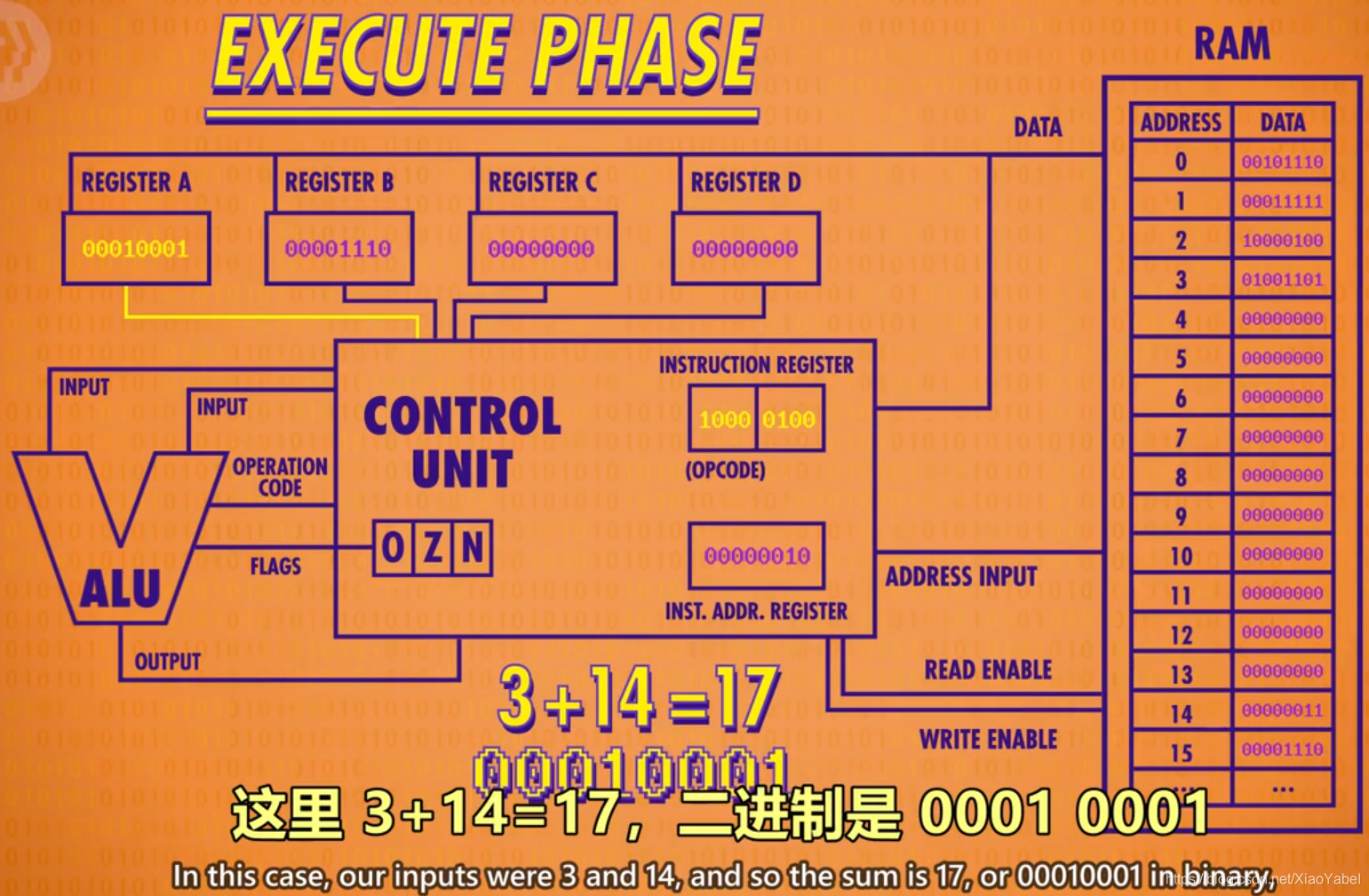
- ADD指令举例1000 0100:ADD后4位,2位2位分别代表2个寄存器,
-
- 2位可以表示4个值(00--寄存器A;01--寄存器B;10--寄存器C;11--寄存器D)
- 前2位代表的寄存器(寄存器B)的值,加到后2位代表的寄存器(寄存器A)里
- 执行该指令,需要整合ALU,“控制单元”复制选择正确的寄存器作为输入,并配置ALU执行正确的操作
- 对于ADD指令,“控制单元”会启用寄存器B,作为ALU的第一个输入;还启用寄存器A,作为ALU的第二个输入,ALU可以执行不同操作所以控制单元必须传递ADD操作码告知ALU执行什么操作。
- 结果应该存到寄存器A
- 但不能直接写入寄存器A,这样新值会进入ALU,不断和自己相加
- 控制单元需要用一个自己的寄存器暂时保存结果
- 关闭ALU,然后把值写入正确的寄存器
- 最后把指令地址+1,完成循环
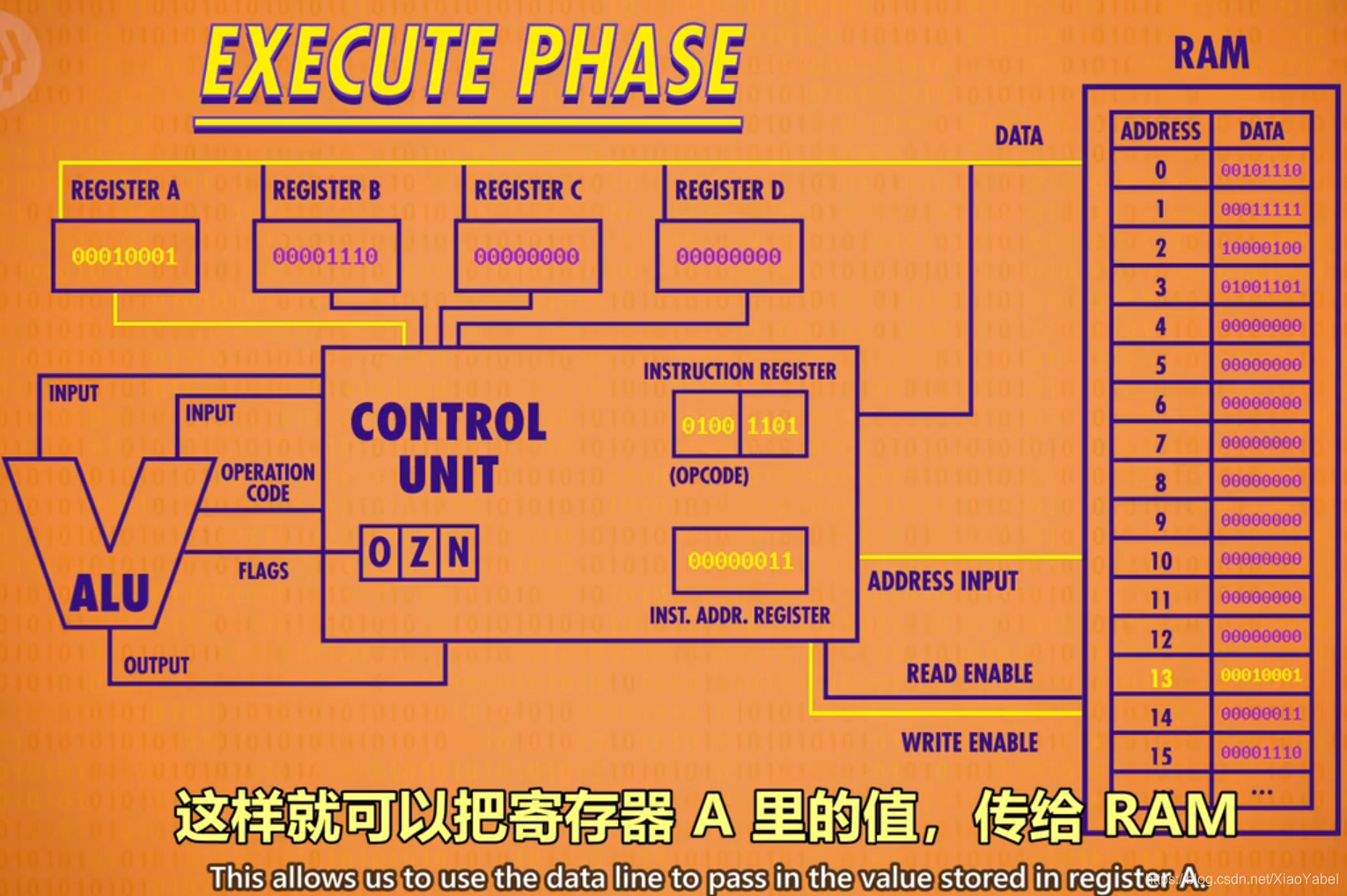
- STORE_A指令举例0100 1101:将寄存器A的值放入地址为13(1101)的内存
- 把地址传给RAM,但这次不是“允许读取”,而是“允许写入”,同时,打开寄存器A的“允许读取”,这样就可以把寄存器A的值传给RAM
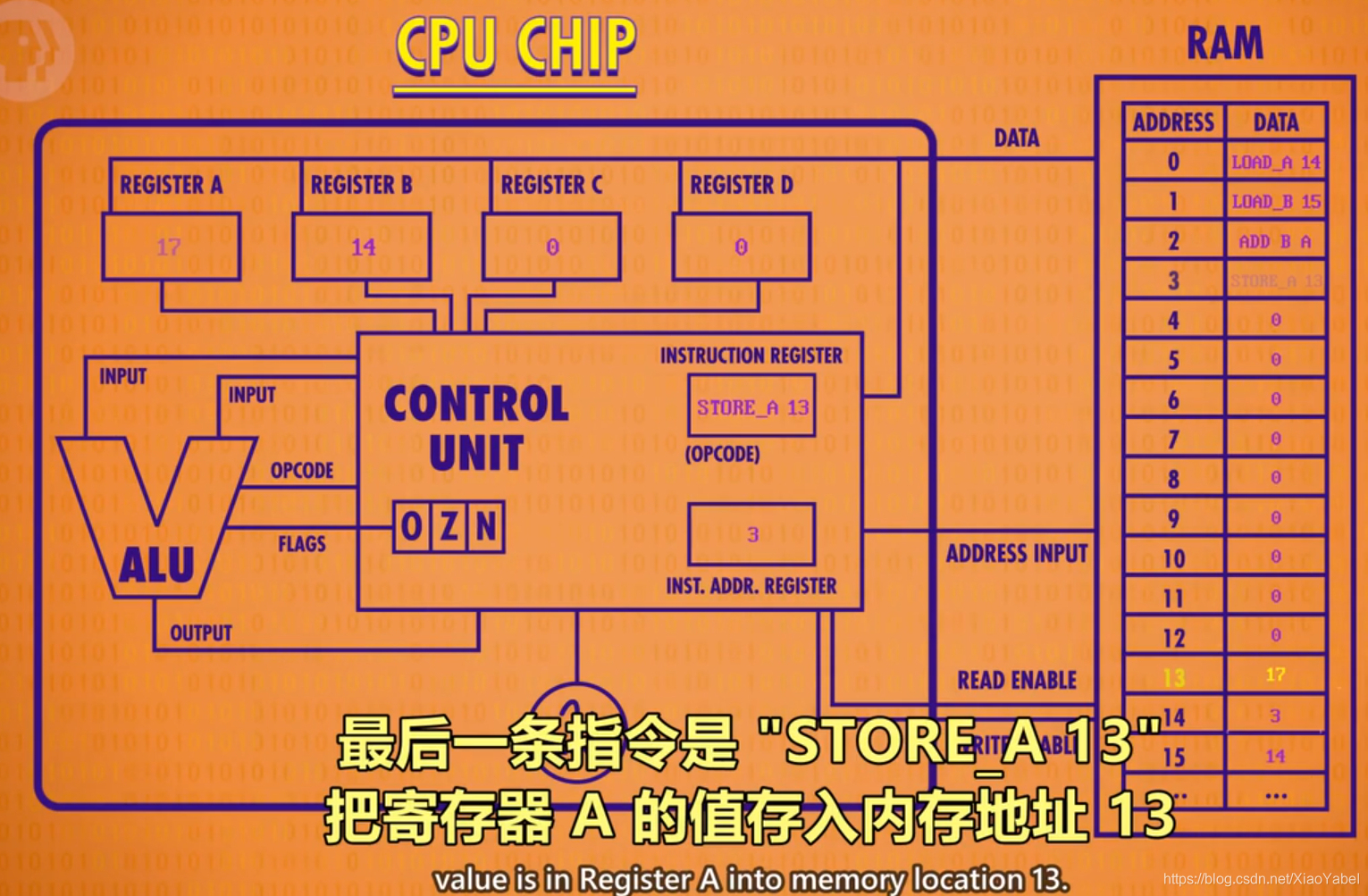
- 时钟:负责管理CPU节奏,以精确的时间间隔触发电信号,控制单元会用这个信号,推进CPU的内部操作,确保一切按步骤进行
- 时钟速度:CPU执行“取指令→解码→执行”中每一步的速度叫做“时钟速度”,单位赫兹Hz,表示频率。
- 1Hz代表1秒1个周期(740kHz--每秒74万次)
- 6分钟4个指令 4*3/360s=0.03Hz(每个指令做了3步,用了3个时钟周期)
- 动态调整频率:超频/降频
- 超频,修改时钟速度,加快CPU的速度,超频过多会让CPU过热或产生乱码。
- 降频,降低时钟速度,达到省电的效果,对笔记本/手机很重要。

4)图示:
第一个CPU
RAM是独立的组件,CPU和RAM之间用“地址线”“数据线”和“允许读/写线”进行通信

第八课 指令和程序
1、概念梳理
- 指令:指示计算机要做什么的代码(机器码),多条指令共同组成程序。如数学指令,内存指令。
- 注:指令和数据都是存在同一个内存里的。都是二进制数。
- 指令集:记录指令名称、用法、操作码以及所需RAM地址位数的表格。
- LOAD_A:将RAM地址为(后4位的二进制)的值存入寄存器A
- LOAD_B:将RAM地址为(后4位的二进制)的值存入寄存器B
- STORE_A:将寄存器A的值放入地址为(后4位的二进制)的内存
- ADD:后4位,2位2位分别代表2个寄存器,前2位代表的寄存器的值,加到后2位代表的寄存器里
- SUB:减法,同ADD一样要2个寄存器操作,后2位代表的寄存器的值—前2位代表的寄存器的值,结果放入后2位代表的寄存器里。
- JUMP:跳转,让程序跳转到新位置,可以改变指令顺序或跳过一些指令
- JUMP 0:跳回开头
- 把指令后4位代表的内存地址的值,覆盖掉“指令地址寄存器”里面的值
- 可实现无限循环
- 特别版JUMP:JUMP_NEGATIVE,它只有在ALU的“负数标志”为真时,进行JUMP(带条件跳转)
- 不同的带条件JUMP有很多:JUMP_IF_EQUAL(如果相等)/JUMP_IF_GREATER(如果更大)
- HALT:停止。(很重要,能区分指令和数据)
2、指令的执行
- 无限循环:
- LOAD_A 14(0010 1110),把1存入A(因为地址14里的值是1),指令地址寄存器+1(顺序执行)
- LOAD_B 15(0001 1111),把1存入B(因为地址15里的值是1),指令地址寄存器+1(顺序执行)
- ADD B A(1000 00 01),把寄存器B和A相加结果以二进制放到A里(结果是2:0000 0010),指令地址寄存器+1(顺序执行)
- STORE_A 13(0100 1011),把寄存器A的值存入内存地址13,指令地址寄存器+1(顺序执行)
- JUMP 2:CPU会把“指令地址寄存器”的值由4,改成2
- 因此下一步不是HALT,回到第2步读内存地址2里的指令ADD B A。
- 即:寄存器B值为1,寄存器A的值无限循环+1,并将结果存入内存地址13。
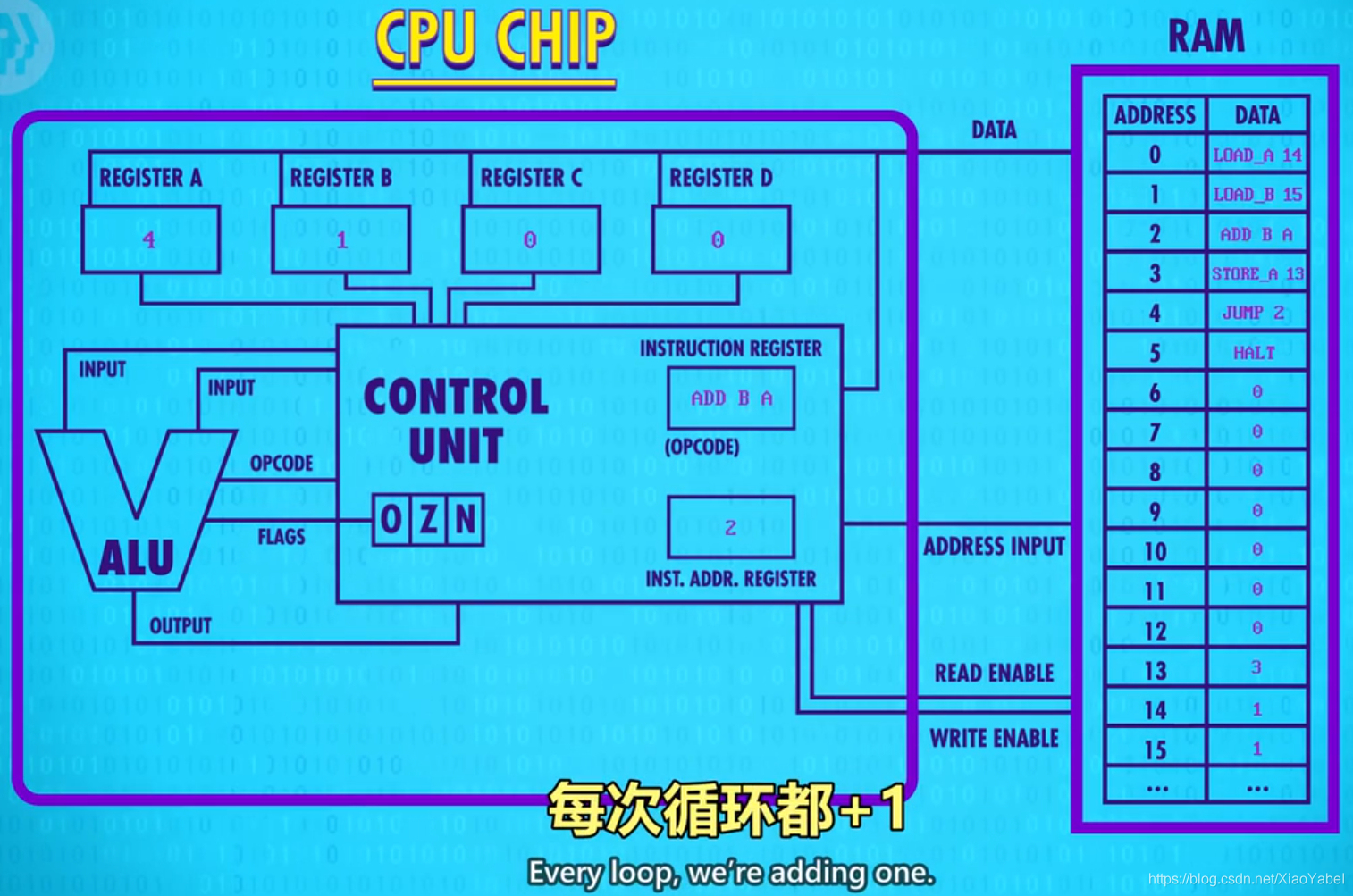
- 特定条件才执行JUMP(条件跳转)
- 通过指令LOAD_A 14,LOAD_B 15程序先把内存值放入寄存器A(值11)和B(值5)
- SUB B A,用A-B,11-5=6,结果存入寄存器A
- JUMP_NEG 5
- 上一次ALU运算结果是6为正数,所以“负数标志”是假(0/false)
- 因此处理器不会执行JUMP,继续执行下一条指令,指令地址寄存器+1
- JUMP 2,没有条件,直接执行。回到第2步读内存地址2里的指令SUB B A
- SUB B A,A-B=6-5=1>0
- JUMP_NEG不执行
- JUMP 2
- SUB B A,A-B=1-5=-4
- JUMP_NEG 5
- ALU的“负数标志”是真(1/true)
- CPU的执行跳到内存地址5
- ADD B A,B+A=-4+5=1结果放入A
- STORE_A 13,寄存器A的值以二进制存入内存地址13
- HALT,程序停止
-
- 程序只有7个指令,但CPU执行了13个指令,内部循环了2次
- 程序作用:11 mod 5=1(11除5余1)
- 可以用任意两个数求余数
- 软件实现硬件做不到的运算,ALU没有除法功能
- 程序实现了除法,别的程序可以用除法程序来实现其他功能(抽象)

3、计算机指令长度
- 以上假设CPU很基础(指令集也是假设的)
- 所有指令都是8位,操作码只占了前面4位(即:对应指令集)最多代表16个指令
- 后4位有的代表指定内存地址,只能操作16个地址
- 由于早期计算机每个字只有8位,指令只占4位,意味着只能有16个指令,这远远不够。
- 现代计算机有两种方式解决指令不够用的问题:
- 最直接的是用更多位来表示指令,如32位或64位,这叫“指令长度”。
- 采用“可变指令长度”,令不同的指令的长度不同,尽量节约位数。
- 比如某CPU用8位长度的操作码,若看到HALT指令,HALT不需要额外数据那么会马上执行(因为不需要操作内存所以可以省下内存那4位)
- 若看到JUMP,它需要知道位置值(内存地址),这个值在JUMP的后面(内存地址里的值即,跳转要执行的指令),这叫“立即值‘(8位的”立即值”来执行JUMP,以表示更多内存地址)
- 这样设计,指令可以是任意长度,但读取阶段比较复杂。
- 假设1个字为16位,如果某指令不需要操作内存,则可以省去寻址的位数。
- 该情况下,部分指令后面需要跟数据,如JUMP,称为立即值。
- 真正现代CPU用更多指令集,位数更长
- 1971年的英特尔4004处理器,有46个指令
- 如今英特尔酷睿i7,有上千条指令和指令变种
- 指令越多CPU功能越多
第九课 高级CPU设计
0、概念梳理
- 缓存CACHE:在CPU中的小块RAM,用于存储批量指令。
- 缓存命中CACHE HIT:想要的数据已经在缓存里
- 缓存未命中CACHE MISS:想要的数据不在缓存里
- 脏位:缓存里每块空间,有个特殊标记,叫脏位,用于检测缓存内的数据是否与RAM一致。
- 多核处理器:一个CPU芯片中,有多个独立处理单元。
1、现代CPU如何提升性能:
- 早期计算机的提速方式:减少晶体管的切换时间加快晶体管速度,晶体管组成了逻辑门,ALU以及前几集的其他组件。但很快该方法到达了极限。
- 后来给CPU设计了专门除法电路+其他电路来做复杂操作:如游戏,视频解码
- 除法程序通过一连串减法实现,需要多个时钟周期低效:现代CPU直接在硬件层面设计了除法可直接给ALU除法指令,使ALU更大也更复杂。复杂度 vs 速度
- 处理器:MMX、3DNOW、SSE,有额外电路做更复杂的操作用于游戏和加密等场景
- 超高的时钟速度
- 如何快速传递数据给CPU?
- RAM是CPU之外的独立组件,即使CPU性能高,但需要RAM的数据才能执行
- 数据要用线来传递“总线BUS”,电信号接近光速,CPU每秒可处理上亿条指令,延迟会造成问题
- 从RAM到CPU的数据传输有延迟。RAM需要时间找地址,取数据,配置,输出数据
- 一条“从内存读数据”的指令LOAD可能要多个时钟周期,CPU空等数据
- 解决延迟方法:
- 给CPU加一点RAM—缓存CACHE,因为处理器里空间不大,所以缓存一般只有KB或MB,而RAM都是GB起步
- CPU从RAM拿数据,RAM不用传一个,可以传一批,时间久一点(时间局部性和空间局部性),但数据可以存在缓存。这很实用,因为数据常常是一个个按顺序处理
- 缓存离CPU近,一个时钟周期就能给数据,CPU不用空等
- 指令流水线提升性能。
2、缓存:
- 为了不让CPU空等数据,在CPU内部设置了一小块内存,称为缓存,让RAM可以一次传输一批数据到CPU中。(不加缓存,CPU没位置放大量数据)
- 缓存也可以当临时空间,存一些中间值(部分运算结果),适合长/复杂的运算
- 存在问题:缓存和RAM不一致
- 这种不一致必须记录下来,之后要同步
- 因此缓存里每块空间,有一个特殊标记——“脏位”DIRTY BIT
3、缓存同步:
- 缓存同步一般发生在CPU缓存已满,但CPU又需要缓存,仍需往缓存内输入数据。
- 在清理缓存腾出空间之前,会先检查“脏位‘
- 如果是”脏“的,在加载新内容之前,会把数据写回RAM
- 即:被标记为脏位的数据会优先传输回RAM,腾出位置以防被覆盖,导致计算结果有误。
4、指令流水线:
- 优化1个指令的吞吐量
- CPU按序处理:取址→解码→执行,不断重复。
- 三个时钟周期执行1条指令,因为每个阶段用的是CPU的不同部分,所以可以实现”并行处理“。
- ”执行“一个指令时,同时”解码“下一个指令,”读取“下下个指令
- 并行处理;
- 作用:让取址→解码→执行三个步骤同时进行。并行处理执行指令,提升CPU性能。
- 不同任务重叠进行,同时用上CPU里所有部分,如同流水线
- 原本需要3个时钟周期执行1个指令,现在只需要1个时钟周期,吞吐量*3。
- 设计难点
- 指令之间的依赖关系:例如读某个数据,而正在执行的指令会改这个数据,拿的是旧数据
- 因此流水线处理器,先要弄清数据依赖性,必要时停止流水线,避免出问题
- 条件跳转
- JUMP_NEGATIVE这些指令会改变程序的执行流
- 简单的流水线处理器,看到JUMP指令会停一会儿,等待条件值确定下来
- 一旦JUMP的结果出了,处理器就继续流水线
- 空等会造成延迟,所以高端处理器会用一些技巧
- 指令之间的依赖关系:例如读某个数据,而正在执行的指令会改这个数据,拿的是旧数据
- 数据依赖性解决方法:
- 乱序执行:动态排序有依赖关系的指令,最小化流水线的停工时间
- 电路复杂,非常高效,现代CPU都有流水线
- 分支预测(高端CPU)
- JUMP想成”岔路口branch“
- 高端CPU会猜哪条路的可能性大一些,然后提前把指令放进流水线,这叫”推测执行“
- JUMP结果出来,若CPU猜对了,流水线已经塞满正确指令,可以马上运行
- 若CPU猜错了,就要清空流水线(走错路掉头),为减少清空流水线次数,CPU厂商开发复杂的方法叫分支预测,提高预测准确率
- 乱序执行:动态排序有依赖关系的指令,最小化流水线的停工时间

5、一次性处理多条指令
- 超标量处理器:一个时钟周期完成多个指令
- 流水线设计,在指令执行阶段处理器有些区域还是可能会空闲
- 从内存取值指令期间,ALU闲置
- 一次性处理多条指令(取指令+解码)
- 多条指令要CPU的不同部分,就多条同时执行
- 例如,很多CPU有四个,八个甚至更多完全相同的ALU可以执行多个数学运算

6、同时运行多个指令流(多核CPU)——提升性能
- 多核处理器:一个CPU芯片中,有多个独立处理单元。但因为它们整合紧密,可以共享一些资源。
- 多核不够时,可以用多个CPU
- 高端计算机,比如大型服务器
7、超级计算机(多个CPU)
- 在一台计算机中,用无数个CPU
- 做怪兽级的复杂运算,如模拟宇宙形成需要强大的计算能力。
- 中国无锡神威·太湖之光:有40960个CPU,每个CPU有256个核心
- 超过一千万个核心
- 每个核心的频率是1.45GHz
- 每秒可以进行9.3亿亿次浮点数运算(每秒浮点运算次数FLOPS)
- 提高处理器速度,榨干每个时钟周期做更多的运算,利用运算能力做实用的事(编程)
上述,指令的执行等均为计算机程序。
第十课 早期的编程方式
1、早期,程序如何进入计算机
- 程序并非直接在内存,需要加载进内存
- 程序必须人为地输入计算机。
- 早期,电脑无内存的概念,人们通过打孔纸卡等物理手段,输入数据(数字),进入计算机。
- 机器编程,在计算机出现之前
- 可编程纺织机1801雅卡尔织布机——每一行图案由可穿孔纸卡决定,特定位置没有穿孔决定了线是高是低
- 1890年美国人口普查:穿孔纸卡
- 1980年,计算机都有穿孔纸卡读取器把卡片内容写进内存,一旦程序和数据写入完毕,电脑会开始执行
- 程序运行结束,结果同样可以输到纸卡上,依旧是打孔的方式。人分析结果再次放入计算机做进一步计算
- 后面到纸带、硬盘、只读光盘、DVD,U盘
2、早期计算机的编程
打孔纸卡——>插线板——>面板拔开关
- 打孔纸卡/纸带:在纸卡上打孔,用读卡器读取连通电路,进行编程。原因,穿孔纸卡便宜、可靠也易懂。62500张纸卡=5MB数据
- (可插拔)插线板:给机器插入不同程序,通过插拔线路的方式,改变器件之间的连接方式,进行编程。
- 面板拨开关(1980s前):通过拨动面板上的开关,进行编程。输入二进制操作码,按存储按钮,推进至下一个内存位,直至操作完内存,按运行键执行程序。(内存式电脑)
- 面板编程,面板上有指示灯代表各种函数的状态和内存中的值
- 拨动面板开关,输入二进制操作码,按“存储键”将值存入,反复操作
- 最低级最麻烦的机器语言
3、现代计算机基础结构——冯诺依曼计算机
- 从把程序存在插线板——>存在内存(易于修改程序方便CPU快速读取),“存储程序计算机”,内存足够则不仅可以存要运行的程序,还可以存程序需要的数据,包括程序运行时产生的新数据——>程序和数据都存在一个地方,叫“冯诺依曼结构”
- 冯诺依曼计算机的标志:
- 一个处理器(有算术逻辑单元)+数据寄存器+指令寄存器+指令地址寄存器+内存(负责存数据和指令)
- 1948年,冯诺依曼架构的“储存程序计算机”
- 有内存,但程序和数据依然需要某种方式输入计算机(比如早期的穿孔纸卡)
第十一课 编程语言发展史
编程:二进制——>助记符(汇编器)——>A-0(编译器)——>FORTRAIN
0、概念梳理
- 第一条指令在内存地址0:0010 1110(前4位是操作码代表指令【OPCODE】后4位内存地址14)
- LOAD ADDRESS 14 INTO REGISTER A
- 计算机能处理二进制,二进制是处理器的“母语”——“机器语言”/“机器码”
- 伪代码PSEUDO-CODE:用自然语言(中文、英语等)对程序的高层次描述,称为“伪代码”
- 助记符——>汇编器:用于将汇编语言装换成机器语言。一条汇编语句对应一条机器指令。
- 软件
1、早期二进制写代码
- 先前都是硬件层面的编程,硬件编程非常麻烦,所以程序员想要一种更通用的编程方法,就是软件。
- 计算机早期阶段,必须用机器码写程序
- 英语写一个“高层次版”
- 这种对程序的高层次描述,叫“伪代码”
- 早期,人们先在纸上写伪代码,用"操作码表"把伪代码转成二进制机器码,翻译完成后,程序可以喂入计算机并运行。
2、汇编器&助记符
- 背景:1940~1950s,程序员开发出一种新语言, 更可读 更高层次。
- 每个操作码分配一个简单名字,叫"助记符"MNEMONICS。
- 助记符后面紧跟OPERANDS(C操作数),形成完整指令
- 0010 1110——>LOAD_A 14
- 但计算机不能读懂“助记符”,因此人们写了二进制程序“汇编器来帮忙”
- 汇编器Assembler
- 作用:汇编器读取用"汇编语言"写的程序,然后转成"机器码"。
- 读懂文字指令,自动转成二进制指令
- 功能之一:自动跳转,自动分析JUMP地址
- 因为开头插入指令可能会改变后面所有指令的地址,所以汇编器不用固定跳转地址,而是插入可跳转的标签
- LOOP(循环):...DONE(结束)当程序被传入汇编器,汇编器会自己搞定跳转地址
- 程序员可以不用管底层细节专心编程(隐藏不必要细节来做更复杂的工作)
3、最早高级编程语言“A-0”
- 汇编只是修饰了一下机器码,一般来说,一条汇编指令对应一条机器指令,所以汇编码和底层硬件的连接很紧密,汇编器仍然强迫程序员思考底层逻辑(用什么寄存器和内存地址)。
- 1944年:程序写在打孔纸带,放进计算机,若程序有漏洞直接用胶带补,带子连起来做循环重复执行程序
- 1950s,为释放电脑潜力,葛丽丝·霍普博士,设计了一个高级编程语言,叫 "Arithmetic Language Version 0"(算数语言版本0)
- 汇编与机器指令一一对应
- 一行高级编程语言 可以转成几十条二进制指令。
- 但由于当时人们认为,计算机只能做计算,而不能做程序,A-0未被广泛使用。
- 1952年,Hopper创造了第一个编译器
- 编译器专门把高级语言转成低级语言,比如汇编或机器码
- 过程:高级编程语言→编译器→汇编码/机器码
- Python举例
- 假设相加两个数字,保存结果
- 汇编代码
- 内存取值,和寄存器打交道,以及其他底层细节
- Load A 14
- Load B 15
- ADD B A
- STORE A 13
- HALT
- Python
- A=3
- B=9
- C=A+B
- 不用管寄存器或内存位置,编译器搞定细节,不用管底层
- 只需要创建代表内存地址的抽象,叫“变量‘Variables,给变量取名字,把数存在变量里
- 底层操作时,编译器可能把变量A存在寄存器A,但实际不用去管
4、开始广泛应用的高级编程语言FORTRAN
- FORTRAN——"公式翻译"formula translation
- 1957年由IBM1957年发布
- 平均来说,FORTRAN 写的程序,比等同的手写汇编代码短 20 倍,
- FORTRAN 编译器会把代码转成机器码。
- 运行速度慢,编程速度加快
5、通用编程语言——COBOL
- 1950年大多数编程语言和编译器只能运行在一种计算机上,升级电脑意味着重写所有代码
- 1959年,研发可以在不同机器上通用编程语言。
- 最后研发出一门高级语言:"普通面向商业语言",简称 COBOL
- 为了兼容不同底层硬件,每个计算架构需要一个 COBOL 编译器
- 这些编译器可以接收相同的COBOL代码
- 一次编写,到处运行,不必接触CPU特有的汇编码和机器码
- 不管是什么电脑都可以运行相同的代码,得到相同结果。
6、现代编程语言:1960s-2000
- 1960s起,编程语言设计进入黄金时代。
- 1960 :ALGOL, LISP 和 BASIC 等语言
- 1970年代有:Pascal,C 和 Smalltalk
- 1980年代有:C++,Objective-C 和 Perl
- 1990年代有:Python,Ruby 和 Java
- 2000年:Swift,C#,Go
- 用更高层次的抽象实现更多的功能
*7、安全漏洞&补丁由来:
在1940年代,是用打孔纸带进行的,但程序出现了问题(也就是漏洞),为了节约时间,只能贴上胶带也就是打补丁来填补空隙,漏洞和补丁因此得名。
第十二课 编程原理-语句和函数
0、概念梳理
大多数编程语言都有的基本元素
- 条件语句:根据条件执行一次
- 条件循环:根据条件执行多次
- 函数用方法,把代码”打包“package,直接使用得出结果
1、变量,赋值语句
- 语法:规定句子结构的一系列
- assignment statement赋值语句:把一个值赋给一个变量
- a=5:创建一个叫a的变量,把数字5放里面
- 变量名可以随意取,不重名即可(为方便读懂还是有点意义)
- 程序由一个个指令组成
- 从第一条语句开始,按序运行到结尾
2、Grace Hopper拍虫子游戏
- 游戏简介:阻止虫子飞进计算机造成故障,关卡越高,虫子越多,Grace在虫子损坏继电器之前抓住虫子,有备用继电器
- 开始编写时,需要值来保存游戏数据:当前关卡、分数、剩余虫子数、剩余继电器’
- 初始化initialize变量:设置最开始的值
- level=1,score=0,bugs=5,spare=4,playerName=Andre
- 初始化initialize变量:设置最开始的值
- 为了做成交互式游戏,程序执行顺序要更灵活,不止从上到下执行
- 控制语句流Control Flow Statements,即以下语句。
- 条件语句:根据条件执行一次
- 条件循环:根据条件执行多次
3、if 判断
- ”岔路口“走哪条路取决于”conditional表达式“的真true/假false
- if [expression] then
[some code]
else
[some code]
end if
- 具体语法略不同,主体结构一样
- if语句 根据条件执行一次

4、while循环
- 先判断条件,看要不要进入循环
- 当while条件为真,代码会重复执行
- 当while条件为假,退出循环,执行后面的代码
- while [expression]
[code to be]
[looped here]
...
loop
5、for循环
- 不判断条件,判断次数,会循环特定次数
- 当while条件为真,代码会重复执行
- 当while条件为假,退出循环,执行后面的代码
- for [variable=start——value] to [end_value]
[code to be looped here]
...
next
- 特点
- 每次结束,i=i+1
6、函数
- 条件循环可以写出数乘,进行次方、累加、累乘运算等
- 例如指数代码很实用,可以广泛运用
- 每次使用复制粘贴,麻烦,还要该变量名,若代码有误要补漏洞时,要把每一个复制粘贴的地方找出来改,代码更难懂
- less is more少即是多
- 用方法,把代码”打包“package,直接使用得出结果
- 所以用return语句,指明result(返回什么结果)
- 只需要写出名字,传入2个数字,例如2^44:result=exponent(2,44)

- 函数可调函数调函数
- 不需要知道内部的循环和变量
- 现代软件由上千个函数组成,每个负责不同的事
7、模块化编程
- 让单个程序员独立制作App
- 团队协作写更大型的程序
- 不同程序员写不同函数,只用确保自己的代码正常工作,把所有人的拼起来,整个程序也能正常运作
8、库
- 库libraries:现代编程语言,有很多预先写好的函数集合
- 由专业人员编写,效率高,且仔细检查过
- 几乎所有事情都有库,网络、图像、声音
第十三课 算法入门
0、概念梳理
- 算法:用不同顺序写不同语句,也能得到一样的结果
- 不同“算法”:解决问题的具体步骤,即使结果一致,有些算法会更好
- 相关因素:
- 一般所需步骤越少越好
- 占用内存
- 相关因素:
- 排序sorting
- 冒泡排序Bubble Sort
- 意面排序Spaghetti Sort
- 选择排序Selection Sort
- 归并排序Merge Sort
- Dijkstra算法
- 大O表示法
- 算法的复杂度:算法的【输入大小】和【运行步骤】之间的关系,表示运行速度的量级
- 经典算法问题:graph search图搜索
1、选择排序
- 数组Array:一组数据
- 以升序排序(从小到大)为例子
- 从上往下,先找到最小数
- 从第一个数开始,第一个数自然是最小
- 判断下一个是否更小,是则成为新的最小数,否则继续向下扫描,直到最后一个数
- 扫描完所有数字,把最小数和最上面的数字,交换位置,即排序了一个数字
- 重复上述过程,但不从最上面开始,从第二个数开始,依旧将第二个数当最小数向下扫描剩下的部分
- 循环,遍历数组
- 伪代码:

-
- 一个for循环套另一个for循环
2、大O表示法
- 算法的复杂度:算法的【输入大小】和【运行步骤】之间的关系,表示运行速度的量级
- 选择排序:排N个数,要循环N次,每次循环中再循环N次,共N^2,O(N^2)
3、归并排序
- 第一件事是检查数组大小是否>1
- 是则,把数组分成两半,例如数组大小是8,分成两个数组大小是4
- 依然>1,所以再分成大小为2的数组,最后变成8个数组,每个大小为1
- 现在开始“归并”
- 从前两个数组开始,读第一个(也是唯一一个)值,把更小的数组放前面,剩下的唯一数组只能放第二位
- 以上成功合并了两个数组,重复此过程按序排列
- 再归并一次
- 同样,取前两个数组(因为上一步合并了两个一个值的数组为一个数组,所以此过程每个数组有两个数值:即每个数组大小为2,共4个数),比较第一个数,更小的放前面。
- 再看两个数组里的第一个数(此时上一步的较小数被拿出来放最前面,所以这里的两个数组是一个大小为2的数组和一个大小为1的数组),选出较小值放上一个较小值后面
- 看两个数组分别剩下的两个数,选出较小数放下一位,最后一个数自然放最后(两个数组即合并成一个有序的有4个数值的数组)
- 每次都以2个数组开始,然后合并成更大的有序数组
- 8个数组因此可以归并成两个大小为4的有序数组
- 下面的数组继续归并
- 比较两个数组的第一个数,取最小数
- 重复直到合并成一个有序数组
- 算法复杂度:O(n*log n)
- n:是需要比较+合并的次数和数组大小成正比
- log N:是合并步骤的次数
- 大小为8的数组,分成4个数组,然后分成2个、1个,分了3次
- 重复切成两半,和数量成对数关系
- 分割次数很难因为数组大小而发生巨大变化
- 归并排序比选择排序更有效率
4、graph search图搜索
- 图:用线连起来的一堆“节点”
- 地图,每个节点是一个城市,线是公路。
- 一个城市到另一个城市,花的时间不同,用成本Cost或权重Weight来代称
- 问题:找到一个城市到另一城市的最快路线
- 蛮力方法:尝试每一条路,计算总成本
- 尝试每一种方法,排序组合,看是否排好序
- 复杂度O(n!)
- n:节点数
- Dijkstra算法
- 从“高庭”开始,此时成本为0,把0标在节点里,其他城市标问号(因为不知道成本多少)
- Dijkstra算法总是从成本最低的节点开始,目前只知道一个节点高庭(起点),所以从高庭开始
- 跑到所有相邻节点,记录成本标在节点里
- 完成了一轮算法
- 因为未到终点”凛冬城“,所以再执行一次Dijkstra算法
- 此时“高庭”已知下一个成本最低(8)的节点,是“君临城”
- 同理,从“君临城”记录所有相邻节点的成本
- 到“三叉戟河”成本是5
- 然而!!!需要记录的是从“高庭”到这里的成本,所以“三叉戟河”总成本是8+5=13
- 现在走“奔流城”成本高达25,总成本33,但“奔流城”中最低成本是10,所以无视新数字保留节点中的最低标记成本10
- 看了“君临城”每一条路,还没到“凛冬城”所以继续
- 下一成本最低的节点,是“奔流城”是10,从“奔流城”记录所有相邻节点的成本
- 到“三叉戟河”总成本10+2=12
- “奔流城”到“派克城”成本3,总成本10+3>14(高庭到派克城),所以更新“派克城”为13
- “奔流城”出发所有路径走遍
- 在执行一次Dijkstra算法
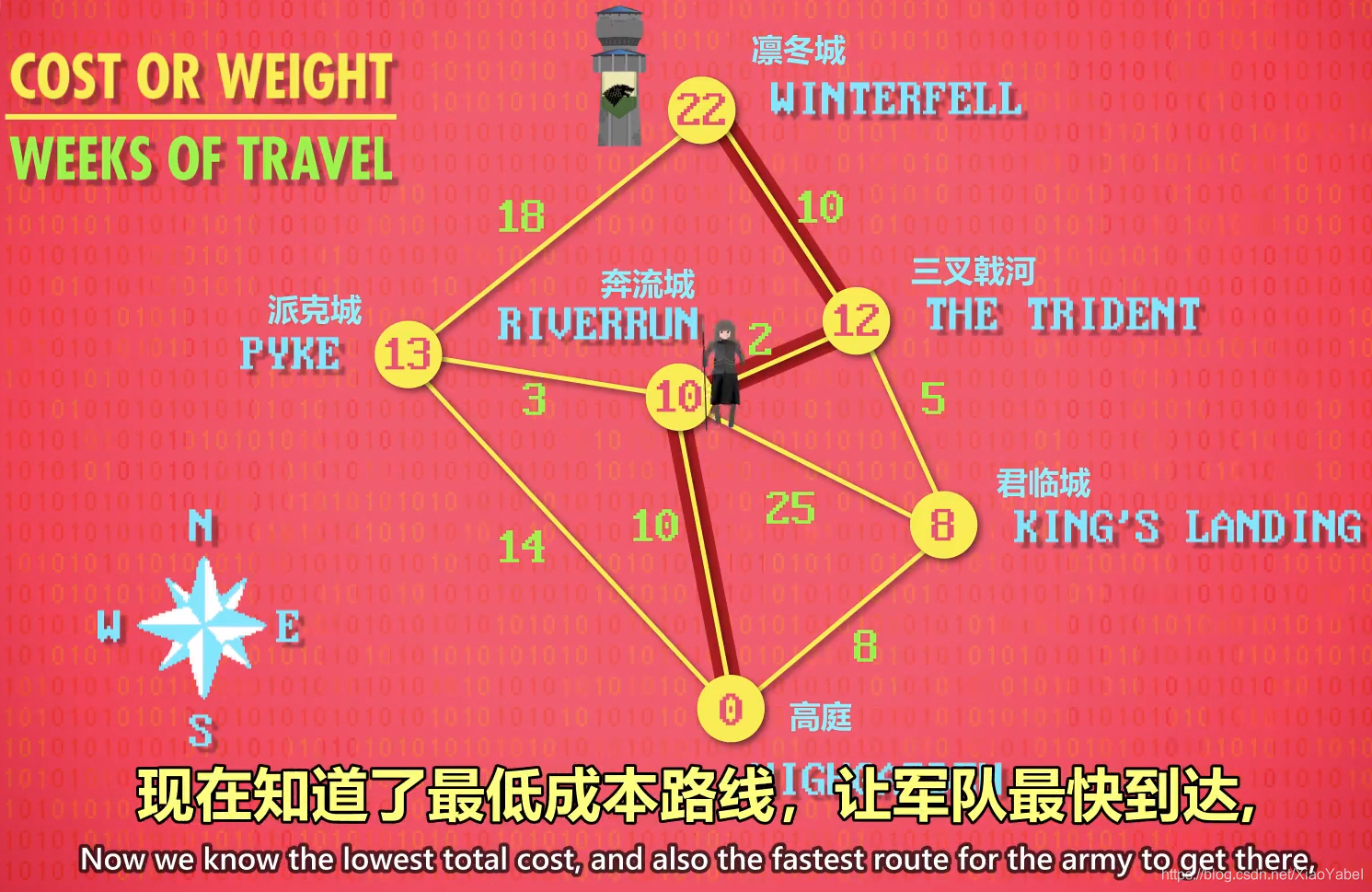
- 下一成本最低节点“三叉戟河‘
- 从”三叉戟河“出发唯一没看过的路,通往”凛冬城“成本10,总成本12+10=22
- 再看最后一条路,”派克城“到”凛冬城“,成本31>22
- 即最低成本路线:高庭----奔流城-----三叉戟河-------凛冬城
- O(n^2)
- 从“高庭”开始,此时成本为0,把0标在节点里,其他城市标问号(因为不知道成本多少)
-
- 改进后的Dijkstra算法O(n log n+I)
- n:节点数
- I:线路数
- 改进后的Dijkstra算法O(n log n+I)
5、算法运用
- 谷歌地图:类似Dijkstra算法在服务器上运行,找最佳路线
- 算法无处不在
第十四课 数据结构
0、概念梳理
- 算法处理的数据,存在内存里的格式是什么?
- 数据结构:
- 数组Array:数组的值一个个连续存在内存里
- 列表list
- 向量Vector
1、数组
- 数组Array:数组的值一个个连续存在内存里
- 可以把多个值存在数组变量里,为了拿出数组中某个值,要指定下标index(通常从0开始),例如:j={5,3,7,21,84,4,19}
- 用[ ]代表访问数组,例如:a=j[0]+j[2]=12
- 简单举例,假设编译器从内存地址1000开始存数组,数组有7个数字,则按顺序存在内存地址1000——1006
- 写j[0],会去内存地址1000,加0个偏移,得到地址1000,拿值:5
- 写j[5],会去内存地址1000,加5个偏移,得到地址1005,拿值:4
- 数组中第5个数
- 数组下标为5的数,是数组中第6个数
- 编程语言自带函数处理数组,数组排序函数‘
- 传入数组,返回排序后的数组,不需要写排序算法
2、字符串
- 字符串Strings:字母,数字,标点符号组成的数组
- 计算及存储字符,引号括起来
- j=“STAN ROCKS”
- 字符串在内存里以0结尾
- 不是字符0,是二进制值0,这叫字符null,表示字符串结尾
- 这个字符很重要,若调用print函数在屏幕输出字符串,会从开始位置逐个显示,需要停止否则会显示内存所有的东西。
- 0告诉函数何时停下

- 计算机经常处理字符串,有很多函数专门处理字符串
- 比如连接字符串string concatenation的strcat
- J接收两个字符串,把第二个放到第一个结尾
- 比如连接字符串string concatenation的strcat

3、矩阵
- 数组可以做一维列表
- 二维数组:电子表格,或者屏幕像素
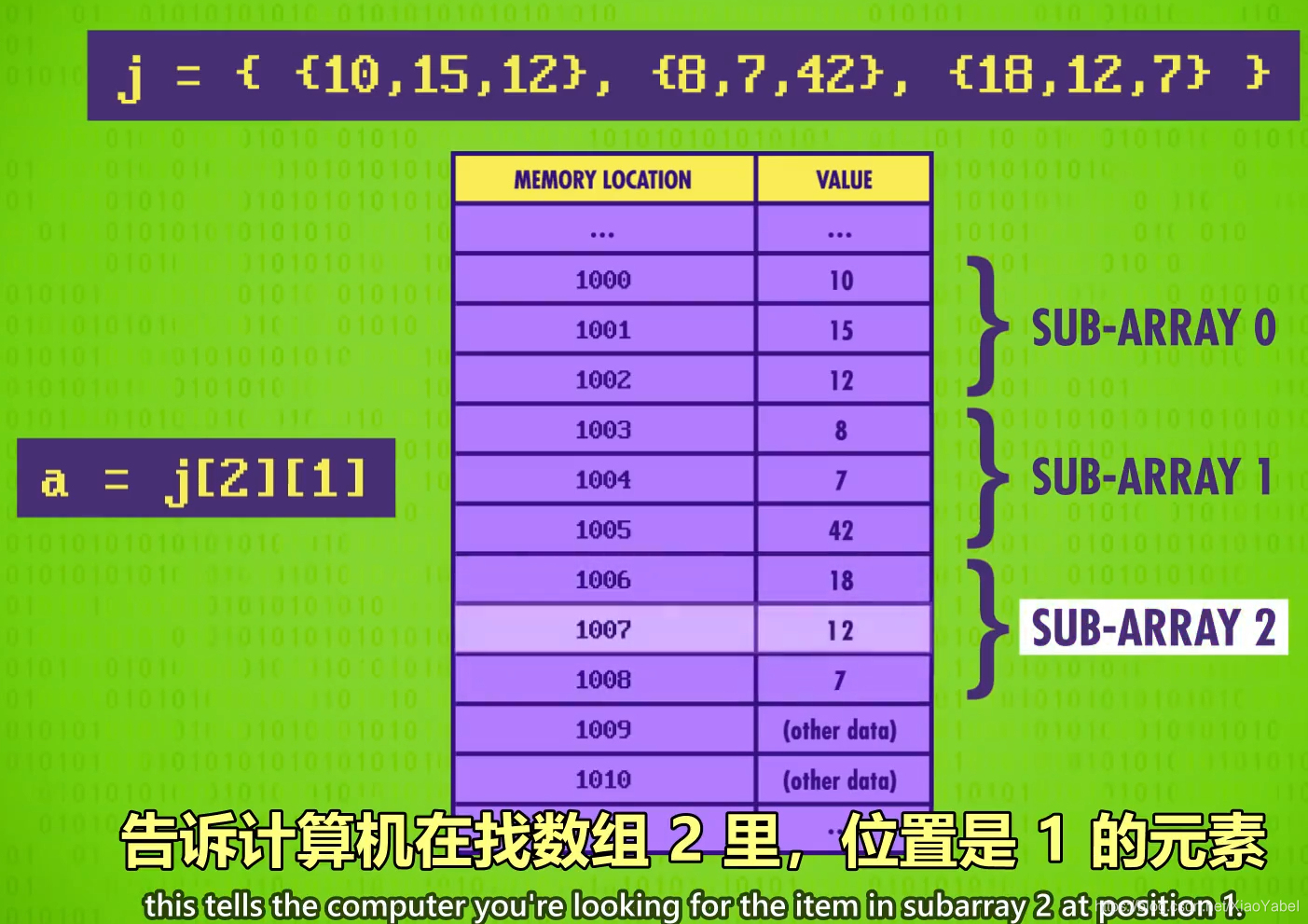
- 矩阵Matrix:
- 数组的数组
- 一个3*3矩阵就是一个长度为3的数组,数组里每个元素都是一个长度为3的数组
-
- 矩阵可以是任何维度,例如5维矩阵a=j[2][0][18][18][3]
4、结构体
- 目前存单个数字。字符,存进数组或矩阵,有关系的变量存在一起
- 比如银行账户和余额
- 结构体Struct:多个变量打包在一起,也就是多个不同数据类型放在一起
- 甚至可以一个数组,里面放很多结构体,这些数据在内存里,会自动打包在一起
- 如果写j[0],能拿到j[0]里的结构体,然后拿到银行账户和余额的变量

-
- 存结构体的数组,同其他数组一样
- 创建时有固定的大小,不能动态增加大小
- 数组在内存中按顺序存储,在中间插入值有难度
- 存结构体的数组,同其他数组一样
- 结构体可以消除数组的限制,创造更复杂的数据结构
- 结构体举例
- 节点

5、节点/指针/链表
- 节点node
- 存一个变量和一个指针(pointer)
- 用节点可以做链表(linked list)
- 指针(pointer):一种特殊变量,指向一个内存地址
- 链表(linked list):一种灵活数据结构,能存很多个节点
- 灵活性是通过每个节点指向下一个节点实现的
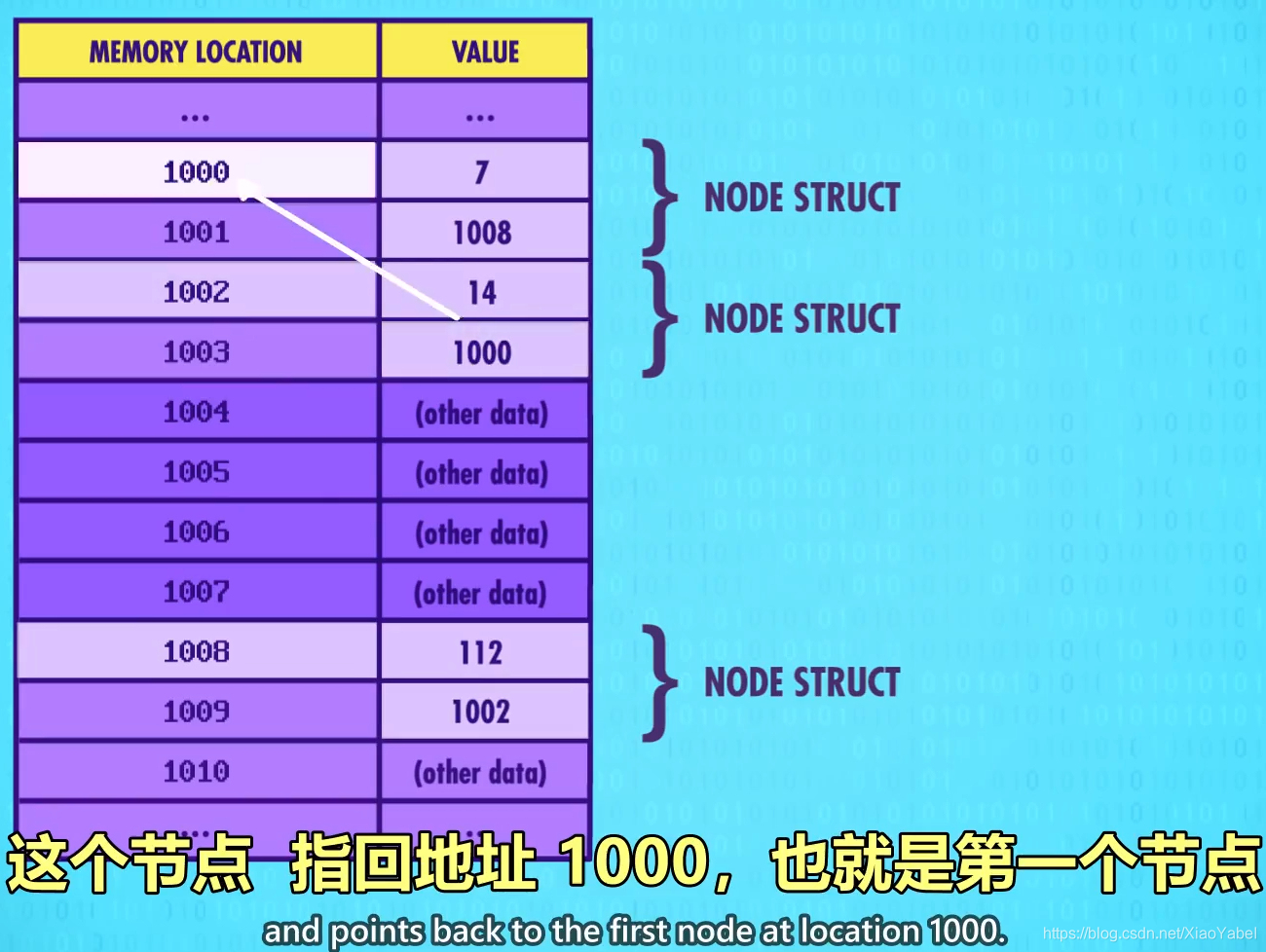
- 假设有三个节点,在内存地址1000,10002,1008
- 隔开原因,可能是创建时间不同,之间有其他数据
- 第一个节点,值是7,指向地址1008
- 代表下一个节点,位于内存地址1008
- 现在来到内存地址1008,值是112,指向地址1002
- 继续根据内存地址,会看到一个值为14的节点,这个节点指回地址1000,也就是第一个节点
- 以上为循环链表circular
- 链表也可以是非循环的,最后一个指针是0“null”,代表链表的尽头
-
- 实际用链表时很少看指针具体指向哪里
- 链表的抽象模型linked list abstraction
- 数组大小需要先预定好
- 链表大小可以动态增减
- 可以创建一个新节点,通过改变指针值,把新节点插入链表

- 链表容易重新排序,两端缩减,分割,倒序等,也适合排序算法,十分灵活
- 复杂的数据结构都用链表
- 队列queue
- 栈stack
8、队列/栈/树
- 队列queue:类比排队,先进先出(FIFO)
- 队列指针,指向链表第一个节点
- 第一个节点,变量读取完后读取第一个节点的指针,把队列指针指向下一个人
- Hank即“出队”dequeue了
- 若需加入新节点入队列(入队enqueue)要遍历整个链表到结尾
- 把结尾的指针,指向新节点
- 栈Stacks:类比桶装薯片,后进先出(LIFO),队列链表稍作修改
- “入栈pushed”
- “出栈popped”
- 树tree:将节点改成2个指针(节点node:存一个变量和一个指针)

- “树”的抽象
- 根节点root:最高的节点
- 子节点children:根节点下的所有子节点
- 母节点parent node:如何子节点的直属上层节点
- 叶节点leaf:没有任何“子节点”的节点,树结束的地方
- 二叉树binary tree:节点最多只可以有2个子节点

- 树的重要性质
- “根”到“叶”是单向的,不存在根连到叶叶连到根,根单向长出叶
9、图
- 图graph:数据随意连接,包括循环,可以用图表示
- 这种结构可以用多个指针的节点表示,可以随意指向
10、红黑树和堆,不同数据结构适用不同场景
- red-black trees
- heaps
- 正确的数据结构会方便工作
- 大多数编程语言自带预先做好的数据结构
- c++:“标准模板库”
- Java:“Java类库”
第十五课 阿兰·图灵---Alan Turing
第十六课 软件工程Software Engineering
0、概念梳理
- 对象Object
- 面向对象编程object oriented programming
- API application programming interface
- public , private
- 集成开发环境,IDE-Integrated development environments
- 调试 debugging
- 文档和注释-readme,comment
- 版本控制 version control
- 质量控制 quality assurance testing,QA
- Beta , Alpha
1、对象Object
- 对象Object:
- 大项目分解成小函数,多人同时工作,不用顾及整个项目,把代码打包成函数依然不够
- 把函数打包成层级hierarchies,把相关代码都放在一起,打包成对象(objects)
- 汽车软件举例:
- 几个和定速巡航有关的函数
- 设定速度FUNCTION setCruiseSpeed(value)
- 逐渐加速FUNCTION nudgeSpeedUp( )
- 逐渐减速FUNCTION nudgeSpeedDown( )
- 停止定速航巡FUNCTION stopCruiseControl( )
- 因为这些函数都相关,可以包装成一个“定速航巡对象”OBJECT CruiseControl
- 定速航巡只是引擎软件的一部分
- “定速航巡对象”OBJECT CruiseControl
- 可能还有“火花塞点火”OBJECT IgnitionControl
- “燃油泵”OBJECT FuelPump
- “散热器”OBJECT Radiator
- 可以用一个“引擎对象”来包括上面所有“子”对象 OBJECT Engine
- 引擎对象,可能有自己的函数和自己的变量
- 开关疫情:FUNCTION startEngine()
- FUNCTION stopEngine()
- FUNCTION checkDilLevel()
- 变量:汽车行驶英里等VARIABLE odometer
- ...
- 几个和定速巡航有关的函数

-
- 总的来说,对象可以包含其他对象,函数和变量
- “引擎对象OBJECT Engine”只是“汽车对象OBJECT Car”的一部分,还有传动装置,车轮,门,窗等
- 若想设“定速巡航‘要一层层向下,从最外的对象往里找最后找到到想执行的函数
- Car.Engine.CruiseControl.setCruiseSpeed(55)
2、面向对象编程object oriented programming
- 面向对象编程:把函数打包成对象的思想
- 同底层硬件思想(晶体管打包成逻辑门),通过封装组件,隐藏复杂度
- 把大型软件(如汽车软件)拆成一个个更小单元,适合团队合作
- 一个团队负责定速巡航系统
- 团队里的一位程序员负责其中一些函数
- 类似建摩天大楼---有电工装电线/管道工配管/焊接工焊接
- 在不同岗位同时工作,各尽其能
- 定速巡航 要用到引擎其他函数来保持车速
- 定速巡航 团队不负责引擎部分代码,另一个团队负责
- 定速巡航 团队需要文档documentation帮助理解代码功能及使用,以及定义好的”程序编程接口“application programming interface
- 一个团队负责定速巡航系统
3、”程序编程接口“ API
- API:帮助不同程序员合作,忽略细节懂得使用
- 点火控制 对象 OBJECT IgnitionControl ,可能有
- ”设置发动机转数“函数——非常有用,需要被”定速巡航“团队,但是对点火系统不了解,若可调用“点燃单个火花塞”函数引擎可能会炸
- ”点燃单个火花塞“函数
- ......
- ”设置发动机转数“函数非常有用,需要被”定速巡航“团队,但是对点火系统不了解,若可调用“点燃单个火花塞”函数引擎可能会炸
- 点火控制 对象 OBJECT IgnitionControl ,可能有
- API控制
- 外部访问的函数和数据public
- 内部访问的函数和数据private
- 面向对象编程语言,可以指定函数是public 或 private,来设置权限
- 若函数标记为pricate,意味着只有同一个对象内的其他函数能调用它
- 对于点火控制对象,只有内部函数比如setRPM(value)才能调用fireSparkplug函数
- 而setRPM函数是public,所以其他对象可以调用它,比如定速巡航OBJECT CruiseControl

- 面向对象和面向对象编程核心:隐藏复杂度,选择性的公布功能
- 面向对象编程语言:
- C++,C#,Objective-C,Python和JAVA
- 代码在编译前只是文字,可以用记事本或任何文字处理器
- 一般,现代软件开发者会用专门的工具来写代码
- 工具里集成了很多有用功能,帮助写代码,整理,编译测试代码
- 因为集成了所有东西
4、集成开发环境,IDE-Integrated development environments
- 代码在编译前只是文字,可以用记事本或任何文字处理器
- 一般,现代软件开发者会用专门的工具来写代码
- 工具里集成了很多有用功能,帮助写代码,整理,编译测试代码
- 因为集成了所有东西——因此叫,集成开发环境,IDE
- IDE功能
- 所有IDE都有写代码的界面
- 还有一些有用功能,比如代码高亮,来提高可读性
- 提供实时检查,比如拼写
- 帮助开发者整理和查看大型项目源代码
- 或者直接编译和运行代码
- IDE可以定位出错代码并且提供信息,帮助解决问题,即调试debugging
- 好工具能极大帮助程序员防止和解决错误
- 很多开发者只用一款IDE(VIM编译器)
5、文档和注释-readme,comment
- 文档一般放在readme文件里,看代码前先查看的文件
- 文档也可以直接写成“注释comment”,放在源代码里
- 注释:标记过的一段文字
- 编译代码时,注释会被忽略
- 作用:帮助开发者理解代码
- 注释很重要!!!!!!!!!!!!!!!!!!
- 文档可以提高复用性code reuse
- 减少一遍遍写重复的代码,直接用他人写好的代码
- 看文档会使用即可,不用读代码
6、版本控制 version control/源代码管理Source Control
- 源代码管理Source Control/版本控制 version control
- 除了IDE以外帮助团队协作的重要软件
- 可以跟踪所有变化,若发现bug,全部或部分代码可以“回滚rolled back”到之前的稳定版,并且记录了改代码的人改动了哪些代码
- 代码仓库code repository
- 大型软件公司会把代码放到一个中心服务器上
- 想改一段代码时,可以check out(类比图书馆借书)可以直接在IDE内完成,然后开发者自己在电脑上编辑代码加新功能,测试,若代码没问题,测试通过就可以把代码放回去commit(提交)
- 当代码被check out 而且可能被改过,其他开发者不在动该代码,防止代码冲突和重复劳动,这样多名程序员可以同时写代码,建立庞大的系统
- 代码的主版本master,应该总是编译正常,尽可能减少bug
7、质量控制 quality assurance testing,QA
- 测试——质量保证测试,QA
- 写代码和测试代码密不可分,测试一般由个人或小团队完成
- 严格测试软件方方面面,模拟各种可能情况,看软件是否出错——找bug
- “beta版”软件:软件接近完成但非100%完全测试过,提前公布该版本可以帮助发现问题,用户即免费的QA团队
- “alpha”版软件:beta版之前的版本,比较少,一般很粗糙且错误很多,经常只在公司内部测试
- 代码需要强大的处理能力才能高速速度运行
第十七课 集成电路&摩尔电路
0、概念梳理
- 分立元件discrete components:
- 只有一个电路元件的组件,可以是被动的(电阻,电容,电感)或主动的(晶体管或真空管)
- 数字暴政 tyranny of numbers:是1960年代工程师碰到的问题
- 1940~1960年代中期:计算机都由独立部件组成,叫“分立元件”,然后不同组件再用线连在一起,提升性能就要加更多部件,导致更多电线更复杂,这个问题叫“数字暴政”
- 意思是如果想强加电脑性能,就要更多部件,这导致更多线路,更复杂
- 光刻 photolithography
- 晶圆 wafer:光刻制作
- 光刻胶 photoresist
- 光掩膜 photomask
- 掺杂 doping
- 摩尔定律 Moore‘s Law
- 英特尔 Intel
- 晶体管数量大幅度增长
- 1980年,三万个;1990年一百万个,2000年三千万个,2010年十亿个
- 进一步小型化会遇到的2个问题
- 1、光的波长不足以制作更精细的设计
- 2、量子隧穿效应
1、电子计算机的诞生年代——硬件性能的爆炸性增长
- 硬件没有大幅度进步,软件不可能有用武之地
- 1940~1960年代中期:计算机都由独立部件组成,叫“分立元件”,然后不同组件再用线连在一起,提升性能就要加更多部件,导致更多电线更复杂,这个问题叫“数字暴政”
- 1950年代中期,晶体管开始商业化(市场买卖)开始用在计算机,晶体管比电子管更小更快更可靠,但晶体管依然是分立元件
- 1959年,IBM把709计算机从原本的电子管全部换成晶体管,新机器速度快6倍,价格低一半
- 晶体管标志着,计算2.0时代,更快更小但晶体管没有解决数字暴政的问题
- 有几十万个独立元件的计算机不但难设计而且难生产
- 1960年代,数字暴政问题严重性达到顶点,电脑内常常一大堆电线缠绕——封装复杂性
- 1958年,jack killby演示了电子部件:电路的所有组件都集成在一起
- 集成电路integrated circuits(ICs):与其把多个独立部件用电线连起来,拼装出计算机,不如把多个组件包在一起变成一个新的独立组件。
- killby用锗来做集成电路,锗很稀少且不稳定
- 1959年,Robert noyce的仙童半导体 让集成电路变为现实
- 用硅,稳定且多
- 开创了电子时代,创造了硅谷(仙童公司所在地)
- IC像电脑工程师的乐高,但最终还是需要连起来,创造更大更复杂的电路,比如计算机
- 印刷电路板printed circuit boards(PCB)
- 可以大规模生产吗,无需焊接或用一大堆线,它通过蚀刻金属线的方式,把零件连接到一起
- PCB和IC结合使用:
- 大幅减少独立组件和电线,但做到相同的功能,更小,更便宜,更可靠
- 1964年,早期IC都是把很小的分立元件封装成一个独立单元,组件很小但数量多的晶体管很难放下,为了实现更复杂的设计,需要全新的制作工艺——光刻
2、光刻 photolithography
- 1962年
- 光刻:用光把复杂图案印到材料上,比如半导体(由硅制成,可控制是否导电)
- 几个基础操作即可制作复杂电路
- 晶圆的制作:
- 一片硅(晶圆),做基础,把复杂金属电路放上面,集成所有东西,适合集成电路的制作
- 在硅片顶部,加一层薄薄的氧化层,作为保护层
- 然后加一层特殊化学品——“光刻胶”,光刻胶被光照射后,变得可溶,可用特殊化学药剂洗掉
- 光掩模:像胶片,转移到晶圆上的图案。光刻胶和“光掩模”配合使用很强大
- 光掩模盖到晶圆上,用强光照射,挡住光的地方,光刻胶不会变化,光照的地方,光刻胶会发生化学变化,洗掉它之后,暴露出氧化层

-
- 用一种化学物物质(通常是一种酸),可以洗掉“氧化层”露出的部分,蚀刻到硅层,其余部分氧化层被光刻胶保护住了
- 为了清理光刻胶,用另一种化学药品洗掉它。光刻法用很多化学品但每种都有特殊用途
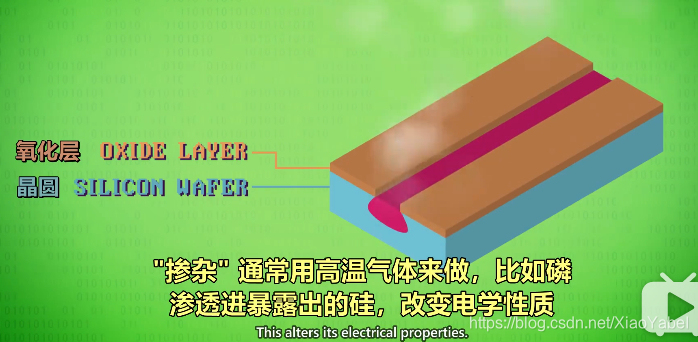
- 硅露出,想修改硅露出来的区域让它导电性更好,需要用一种化学过程来改变它,叫“掺杂Doping”(注入一些外来物质提高物体性能)
- 掺杂:
- 通常用高温气体来做,比如磷,渗透进暴露出的硅,改变电学性质
- 半导体的具体物理和化学性质不深究
-
- 还需要几轮光刻法来做晶体管,过程基本同上一样
- 先盖氧化层,再盖光刻胶,然后用新的光掩模,这次光掩模的图案不同,在掺杂区域上方开一个缺口
- 洗掉光刻胶,然后用另一种气体掺杂,把一部分硅转成另一种形式
- 为了控制深度,时机很重要,比如不超过之前的区域
- 还需要几轮光刻法来做晶体管,过程基本同上一样
-
- 最后一步,在氧化层上做通道,可以用细小金属导线连接不同晶体管
- 再次使用光刻胶和光掩模,蚀刻出小通道
- “金属化”
- 放一层薄薄的金属,比如铝或铜
- 但不用金属盖住所有东西,想蚀刻出具体的电路
- 继续类似的步骤:
- 光刻胶+光掩模,溶掉暴露的光刻胶,暴露的金属
- 最后一步,在氧化层上做通道,可以用细小金属导线连接不同晶体管

-
- 晶体管完成
- 有三根线,连接硅的三个不同区域
- 每个区域的掺杂方式不同
- 这叫双极性晶体管bipolar junction transistor
- 以上,用类似步骤,光刻可以制作其他电子元件,比如电阻和电容,都在一片硅上,而且互相连接的电路也做好了,不在是分立元件。
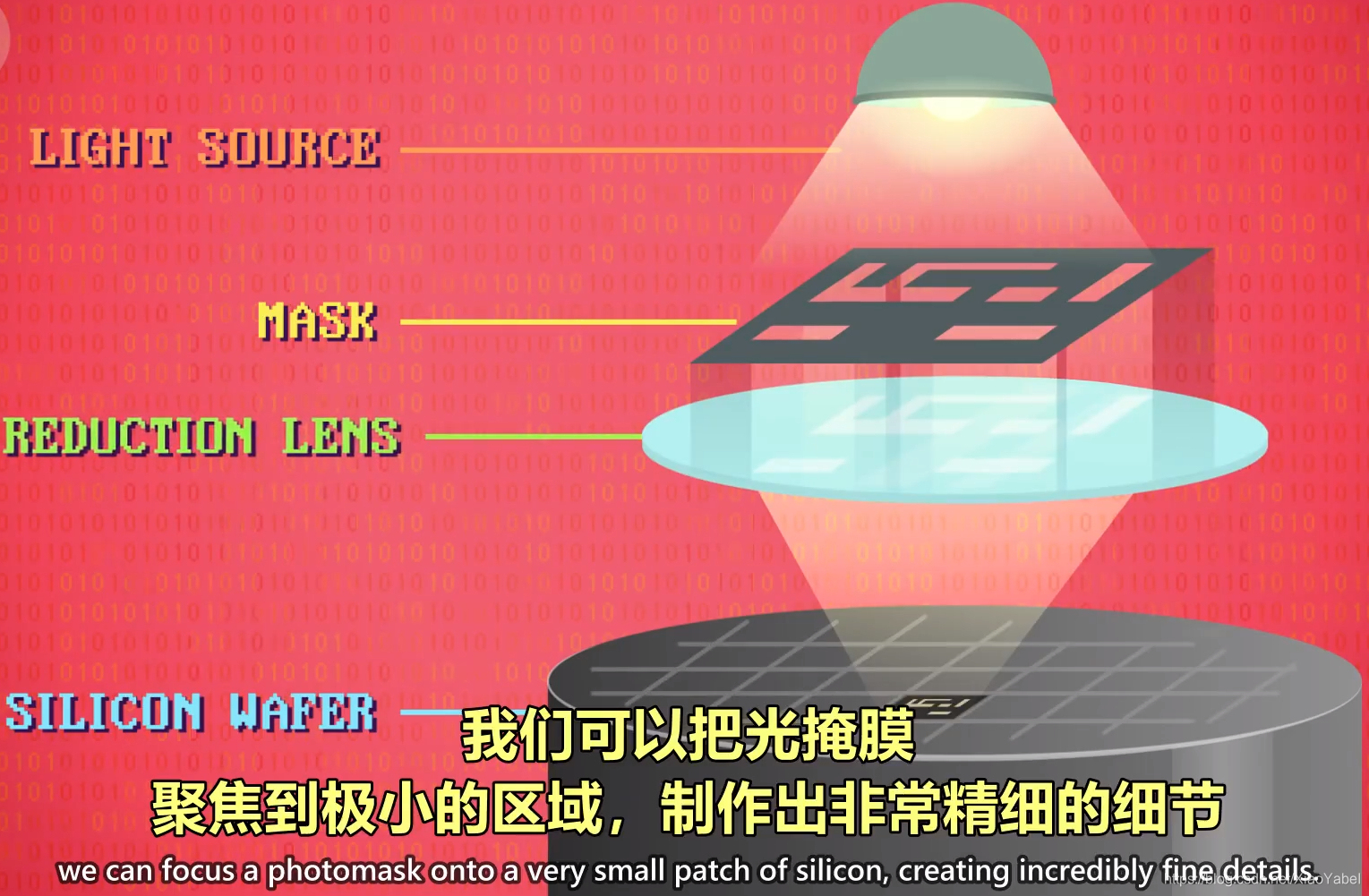
- 上面仅举例说明,光刻法做一个晶体管,但现实中光刻法一次会做上百万个细节
- 芯片放大,导线上下交错,连接各个元件
- 尽管可以把光掩模投影到一整片晶圆上,但光可以投射成任意大小
- 可以把光掩模聚焦到极小的区域,制作出非常精细的细节
- 晶体管完成
- 一片晶圆可以做很多IC,整块都做完后,可以切割然后包进微型芯片
- 微型芯片:在电子设备中那些小长方体
- 芯片的核心都是一小片IC
- 光刻技术的发展,晶体管变小,密度变高
- 1960年代初,IC很少超过5个晶体管,放不下
- 1960年代中期,IC实现有超过100个晶体管
- 1965年,摩尔定律每两年左右,得益于材料和制造技术的发展,同样大小的空间能放下两倍数量的晶体管
- 1962年,芯片价格下降
- 晶体管越小,要移动的电荷量越小,能更快切换状态,耗电更少
- 电路更紧凑,意味着信号延迟更低,导致时钟速度更快
3、摩尔定律 Moore‘s Law
- 摩尔定律:集成电路上可以容纳的晶体管数目在大约每经过24个月便会增加一倍。换言之,处理器的性能每隔两年翻一倍。
- 是一种趋势,并非自然科学定律,它一定程度揭示了信息技术进步的速度
4、英特尔 Intel
- 1968年,Robert Noyce和Gordon Moore联手成立了一家新公司
- 结合Intergrated(集成)和Electronics(电子)——Intel(线最大芯片制造商)
- 集成电路用来做微处理器,开启计算3.0
- 晶体管数量大幅度增长
- 1980年,三万个;1990年一百万个,2000年三千万个,2010年十亿个晶体管在一个芯片
- 达到这种密度,光刻的分辨率从大约一万纳米(头发直径1/10)到现在14nm
- 大多数电子器件都在指数式发展:cpu、内存、显卡、固态硬盘、摄像头感光元件...
- 1970年,超大规模集成(VLSI)软件,用来自动生成芯片设计
- 用比如“逻辑综合Logic synthesis”技术,可以放一整个高级组件,比如内存缓存
- 软件会自动生成电路,做到尽可能高效
- 进一步小型化会遇到的2个问题
- 1、用光掩模把图案弄到晶圆上,因为光的波长,精度已达极限
- 需研制波长更短的光源,投射更小的形状
- 2、量子隧穿效应quantum tunneling:当晶体管非常小,电极之间可能只距离几个原子,电子会跳过间隙(量子隧道贯穿)
- 1、用光掩模把图案弄到晶圆上,因为光的波长,精度已达极限
第十八课 操作系统
0、概念梳理
用一种方式让计算机自己运作
- 操作系统
- 批处理
- 计算机变便宜变多,有不同配置,写程序处理不同硬件细节很痛苦,因此操作系统负责抽象硬件
- 外部设备
- 设备驱动程序
- 多任务处理
- 虚拟内存
- 动态内存分配
- 内存保护
- 1970年代,计算机足够便宜,大学买了让学生用,多个学生用多个“终端”连接到主机
- 多用户分时操作系统,Multics
- Unix
- MS-DOS
1、操作系统
- 操作系统,简称OS
- 其实也是程序,但它有操作硬件的特殊权限,可以运行和管理其它程序
- 操作系统一般是开机第一个启动的程序
- 其他所有程序,都由操作系统启动
- 操作系统开始于1950年代,那时计算机开始变得更强大更流行
- 第一个操作系统,加强了程序加载方式
- 从之前只能一次给一个程序,现在可以一次多个
- 当计算机运行完一个程序,会自动运行下一个程序
2、批处理batch processing
- 批处理:
- 从之前只能一次给一个程序,现在可以一次多个
- 当计算机运行完一个程序,会自动运行下一个程序
- 计算机变便宜变多,有不同配置,写程序处理不同硬件细节很痛苦,因此操作系统负责抽象硬件
3、外部设备
- 外部设备periphrasis:不同型号打印机交互困难,以及计算机连着的其他设备
- 和早期的外部设备交互,是非常底层的
- 程序员很少能拿到所有型号的设备来测代码
- 设备驱动程序device drivers:操作系统提供API来抽象硬件
- 为了写软件更容易,操作系统充当软件和硬件之间的媒介
- 用标准机制,和输入输出硬件(I/O)交互
- 比如,只需要调用print(highscore)操作系统会处理输到纸上的具体细节
- 1950年代尾声,电脑处理很快
- 处理器等待慢的机械设备,程序阻塞在I/O上
- 50年代后期——第一台超级计算机Atlas
- 最大限度利用机器处理
- 1962年——Atlas Supervisor
- 这个操作系统不仅像更早期批处理系统能自动加载程序,还能再单个CPU上同时运行几个程序
- 通过调度实现
- 假设Atlas上有一个游戏运行,并且调用一个函数print(highscore)
- 它让Atlas打印一个highscore的变量值
- print函数运行需要一点时间,大概上千个时钟周期
- 因为打印比cpu慢,与其等着它完成操作,Atlas会把程序休眠,运行另一个程序
- 最终,打印机会告诉Atlas,打印完成,Atlas会把程序标记成可继续运行,之后某时刻安排给cpu运行并继续print语句之后的下一行代码
- 实现可以再cpu上运行一个程序,同时另一个程序再打印数据,同时另一个程序读数据
4、多任务处理
- multitasking:多个程序同时运行,在单个cpu上共享时间,操作系统的这种能力叫“多任务处理”
- 同时运行多个程序的问题
- 每个程序都会占一些内存,当切换到另一个程序时,不能丢失数据
- 解决办法;
- 给每个程序分配专属内存块
- 举例说明:
- 假设计算机一共有10000个内存位置,程序A分配到内存地址0到999,程序B分配到内存地址1000到1999,以此类推
- 如果一个程序请求更多内存,操作系统会决定是否同意。若同意,分配哪些内存块
- 程序A可能会分配到非连续的内存块,比如内存地址0到999,以及2000到2999(真正的程序可能会分配到内存中数十个地方,很难跟踪)
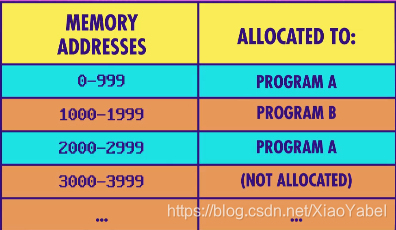
5、虚拟内存 / 动态内存分配 / 内存保护
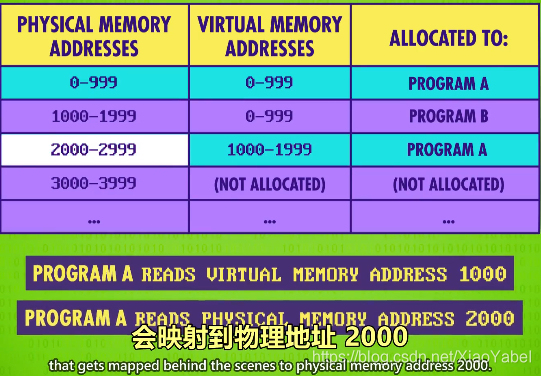
- 虚拟内存virtual memory:
- 列表会存在一堆不连续的内存中,为隐藏复杂性,操作系统会把内存地址进行“虚拟化”
- 程序可以假定内存总是从地址0开始,简单一致。实际物理位置,被操作系统隐藏和抽象了
- 举例
- 程序B举例,它被分配了内存地址1000到1999
- 对程序B而言,它看到的地址是0到999
- 操作系统会自动处理虚拟内存和物理内存之间的映射
- 若程序B要地址42,实际上是物理地址1042
- 这种内存地址的虚拟化,对程序A更有用
- 例子中,A被分配了两块隔开的内存,程序A不知道这点
- 以A的视角,它有2000个连续地址
- 当程序A读内存地址999时,会刚好映射到物理地址999
- 但若程序A读下一个地址1000,会映射到物理地址2000
- 程序B举例,它被分配了内存地址1000到1999
- 动态内存分配dynamic memory allocation:
- 这种机制使程序的内存大小可以灵活增减
- 简化了一切,为操作系统同时运行多个程序提供了极大的灵活性
- 给程序分配专用的内存范围的好处
- 若一个程序出错,开始读写乱七八糟的数据,它只能影响自己的内存,不会影响到其他程序——内存保护memory protection
- 防止恶意软件(病毒)也很有用
- 不希望其他程序有能力读或改邮件程序的内存
- 若有这种权限,恶意软件可能会以你个人名义发邮件,甚至窃取个人信息
- Atlas既有“虚拟内存”也有“内存保护”,是第一台支持这些功能的计算机和操作系统
6、多用户分时操作系统,Multics、Unix
- 1970年代,计算机足够便宜,大学买了让学生用
- 计算机不仅能同时运行多个程序,还能让多用户同时访问
- 多个用户用终端来访问计算机
- 终端:键盘+屏幕,连到主计算机,终端本身没有处理能力
- 多用户访问计算机时:
- 操作系统不但要处理多个程序,还要处理多个用户
- 为确保其中一个人,不会占满计算机资源开发了分时操作系统Time-sharing
- Time-sharing
- 意思是,每个用户只能用一小部分处理器,内存等
- 早期分时操作系统中,最有影响力的是Multics(多任务信息与计算系统)
- 1969年,第一个从设计就考虑到安全的操作系统
- 防止恶意用户访问不该访问的数据
- 复杂度过高,内存占用过大,功能过多
- 1971年发布,Unix
- 把操作系统分成两部分:
- 操作系统的核心功能:如内存管理,多任务和输入/输出处理——内核kernel
- 有用的工具:不是内核一部分(比如程序和运行库)
- Multics一般代码都是错误恢复代码,Unix不会,有错误发生就让内核“恐慌kernel panic”当调用它时,机器会崩溃
- 内核“恐慌:
- 内核若崩溃,没办法恢复,调用一个panic的函数(起初只是打印panic一次,然后无限循环)
- Unix因此可以在更便宜更多的硬件运行,发布后,出现很多不同编程语言的编译器,甚至文字处理器
- 缺少“多任务”和“保护内存”这样功能
- 意味着程序经常使系统崩溃,可以重启
- 程序行为不当就“蓝屏”,代表程序崩溃严重会把系统也带崩溃
- 把操作系统分成两部分:
第十九课 内存&存储介质
0、概念梳理
- 内存Memory:一般电脑内存是非永久性的(non-permanent),断电,内存里所有数据会丢失,所以内存叫“易失性”存储器
- 存储器Storage:
- 任何写入存储器的数据,比如硬盘,数据会一直存着,直到被覆盖或删除,断电也不会丢失
- 存储器是“非易失性”的
- 比如:U盘,低成本+可靠+长时间 断电状态存储上GB数据
- 打孔纸卡 paper punch cards:
- 最早的存储介质
- 用了十几年,不用电便宜耐用
- 读取慢,只能写入一次,打的孔不容易轻易补上
- 对于存临时值,不好用
- 延迟线存储器 delay line memory
- 磁芯magnetic core memory
- 磁带 magnetic tape
- 磁鼓 magnetic drum memory
- 硬盘 hard disk drives
- 内存层次结构 memory hierarchy
- 软盘 floppy disk
- 光盘 compact disk
- 固态硬盘 solid state drives
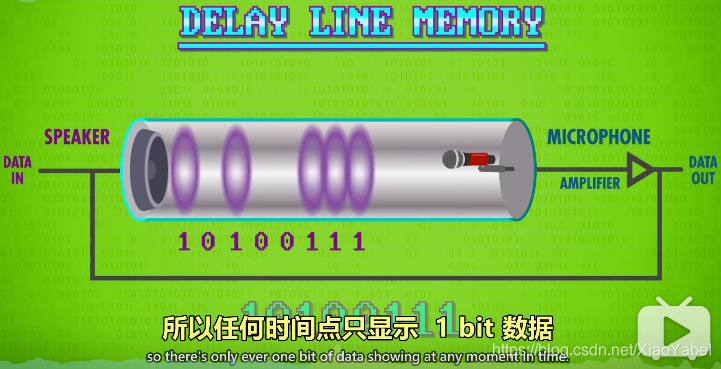
1、延迟线存储器 delay line memory
- 1944年,延迟线存储器 delay line memory
- 原理;
- 一个装满液体(如水银)的管子,管子一端放扬声器,另一端放麦克风
- 扬声器发出脉冲时,会产生压力波,压力波需要时间,传播到另一端的麦克风,麦克风将压力波转换回电信号
- 可以用压力波的传播延迟,来存储数据
- 假设有压力波代表1,没有代表0,扬声器可以输出二进制的数据,压力波沿管子传播,过一会撞上麦克风,将信号转换回1和0
- 若加一个电路,连接麦克风和扬声器,再加一个放大器(Amplifer)来弥补信号衰弱,就能做一个存储数据的循环。信号沿电信传播几乎是瞬时的,所以任何时间点只显示1bit数据,但管子中可以存储多个位(bit)
- 原理;
- EDVAC计算机,使用了延迟线存储器
- 最早的“存储程序计算机”之一
- 存储程序计算机stored-program computer:只要能在内存里存程序,就是存储程序计算机
- 缺点:
- 每个时刻只能读一位(bit)数据,若想访问一个特定的bit,得等待它从循环中出来,所以又叫“顺序存储器”或“循环存储器”
- 但是需要“随机存取存储器”可以随时访问任何位置
- 增加内存密度:
- 把压力波变得更紧密,意味着更容易混淆
- 1950年代中期基本过时
- 衍生的延迟线存储器:磁致伸缩延迟存储器
- 用金属线的振动来代表数据,通过把线卷成线圈(1英尺^2的面积能存储大概1000bit)
2、磁芯magnetic core memory
- 磁芯存储器:
- 用小型磁圈,给磁芯绕上电线,并施加电流,可以将磁化在一个方向;
- 若关掉电流,磁芯保持磁化;
- 若沿相反方向施加电流,磁化的方向(极性)会翻转
- 通过磁化的方向可以存储1和0
- 若需存多位,即将小型磁圈排列成网格,有电线负责选行和列,也有电线贯穿每个磁芯,用于读写一位(bit)
- 不同于”延迟线存储器“磁芯存储器能随时访问任何一位

3、磁带 magnetic tape
- 磁带:
- 纤薄柔软的一长条磁性带子,卷在轴上,磁带可以在”磁带驱动器“内前后移动
- 里面有一个“写头”绕了电线,电流通过产生磁场,导致磁带的一小部分被磁化。电流方向决定了极性,代表1和0
- 还有一个”读头“,可以非破坏性的检测极性
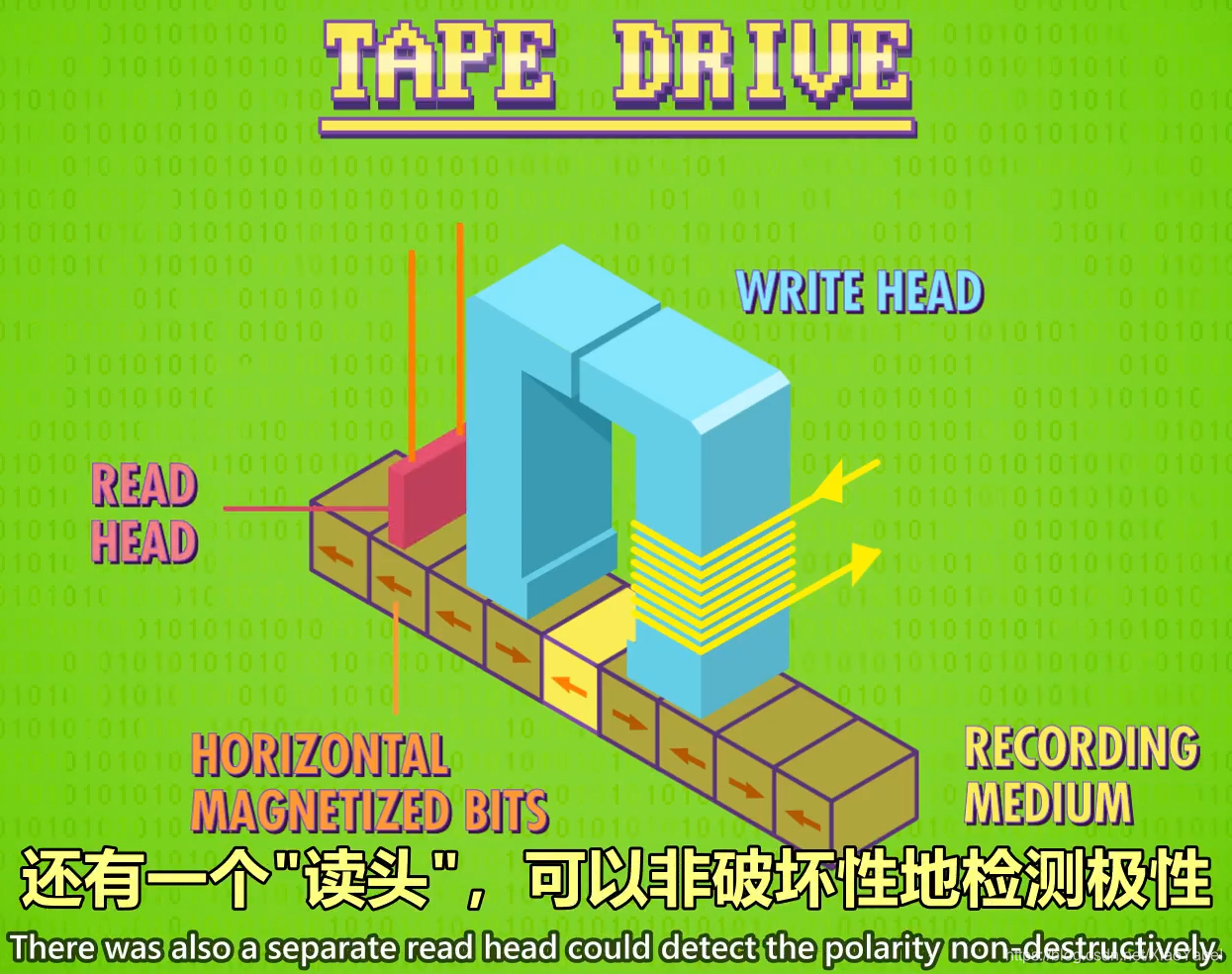
- 主要缺点
- 访问速度,磁带是连续的,必须倒带或快进到特定位置,很慢
4、1950,60年代,磁鼓存储器 magnetic drum memory
- 磁鼓存储器:
- 有金属圆筒,盖满了磁性材料以记录数据,滚筒会持续旋转,周围有数十个读写头,等滚筒转到正确的位置,读写头会读或写1位(bit)数据
- 为尽可能缩短延迟,鼓轮每分钟上千转
- 1970年代”磁鼓存储器“不再生产,但是导致了硬盘的发展
- 磁盘用的是盘,不像磁鼓用圆柱体,原理相同,磁盘表面有磁性,写入头和读取头,可以处理上面的1和0,硬盘比较薄可以叠在一起提供更多表面积来存数据
- 多张磁盘存储数据
- 要访问某个特定bit,一个读/写磁头会向上或向下移动,找到正确的磁盘,然后磁头会滑进去,就像磁鼓存储器一样,磁盘也会告诉旋转,所以读写头要等正确的部分转起来
- 寻道时间seek time:访问任意数据的时间
5、内存层次结构 memory hierarchy
- 一小部分高速+昂贵的内存
- 一部分稍慢+相对便宜的内存
- 还有更慢+更便宜的内存
- 混合使得成本和速度取得平衡

软盘 floppy disk
- 软盘:除了磁盘是软的,其他与硬盘基本一样
- 为了便携在1970-1990流行
6、光盘(CD) compact disk
- 1972年,光学存储器出现
- 功能:
- 和软盘硬盘一样,存数据,但用的不是磁性
- 光盘表盘有很多小坑,造成光的不同反射,光学传感器会捕获到,并解码为1和0
DVD
7、固态硬盘 solid state drives
- 如今,存储技术在朝固态前进,没有机械活动部件,比如硬盘以及U盘,里面是集成电路
- RAM集成电路使“磁芯存储器”迅速过时
- 机械硬盘被固态硬盘逐渐代替,简称SSD
- 没有移动部件,磁头不用等磁盘转
- 所以SSD访问时间快,但比RAM慢很多倍
- 所以现代计算机,仍然用存储层次结构
第二十课 文件系统
0、概念梳理——计算机如何管理文件
- 存储器非常适合存一整块有关系的数据,或者说“文件”
- 文件格式:可以随便存文件数据,但按格式存会更方便
- 已有的文件格式标准,比如:MP3、JPEG
- TXT 文本文件:ASCII
- WAV音频文件:每秒上千次的音频采样数字
- BMP图片文件:像素的红绿蓝RGB值
- 文件系统:很早期时空间小,整个存储器就像一个文件。后来随容量增长,多文件非常必要
- 目录文件:用来解决多文件问题,存其他文件的信息,比如开头、结尾,创建时间等
- 平面文件系统-Flat File System:文件都在同一个层次,早期空间小,只有十几个文件,平面系统够用
- 如果文件紧密的一个个前后排序会造成问题,所以文件系统会:
- 把空间划分成一块块
- 文件拆分存在多个块里
- 文件的增删改查会不可避免的造成文件散落在各个块里,如果是磁带这样的存储介质就会造成问题,所以做碎片整理
- 分层文件系统-Hierarchical file system:有不同文件夹,文件夹可以层层嵌套
1、简单的文件格式
- 文本文件TXT:
- 原始值只是一长串二进制数,解码数据的关键是ASCII编码
- 波形Wave文件,也叫WAV:
- 存音频数据
- 在正确读取数据前,需要知道一些信息
- 码率(bit rate)
- 单声道还是立体声
- 元数据meta data:数据的数据
- 元数据存在文件开头,在实际数据前面(也叫文件头Header)
- WAV文件的前44个字节
- 有部分总是一样,比如写着WAVE部分
- 其他部分内容,会根据数据变化
- 音频数据紧跟在元数据后面,是一长串数字。数字代表每秒捕获多次的声音幅度
- 某段音频波形举例:
- 捕获声音,声卡或麦克风每秒可以对声音进行上千次采样,每次采样可以用一个数字表示
- 声压越高数字越大,也叫“振幅”
- WAVE文件里存的就是这些数据,每秒上千次的振幅
- 播放声音文件时,扬声器会产生相同的波形
- 位图Bitmap,后缀.bmp
- 存图片
- 图片由多个“像素”方块组成
- 每个像素由三种颜色组成:红,绿,蓝(加色三原色),混在一起可以创造其他颜色
- 同WAV文件,BMP文件开头也是元数据
- 有图片宽度,图片高度,颜色深度
- 例如,元数据可以说明图是4像素宽*4像素高,颜色深度24位8bit红8绿8蓝(8位同1字节,一个字节能表示最小0最大255)
- 图像数据解析
第一个像素颜色:红255/绿255/蓝255(全强度红绿蓝)——>混合是白色——>第一个像素是白色
下一个像素的红绿蓝值,或RGB值255,255,0是黄色,以此类推
因为元数据说明图片是4*4,可以知道到4个像素到下一行
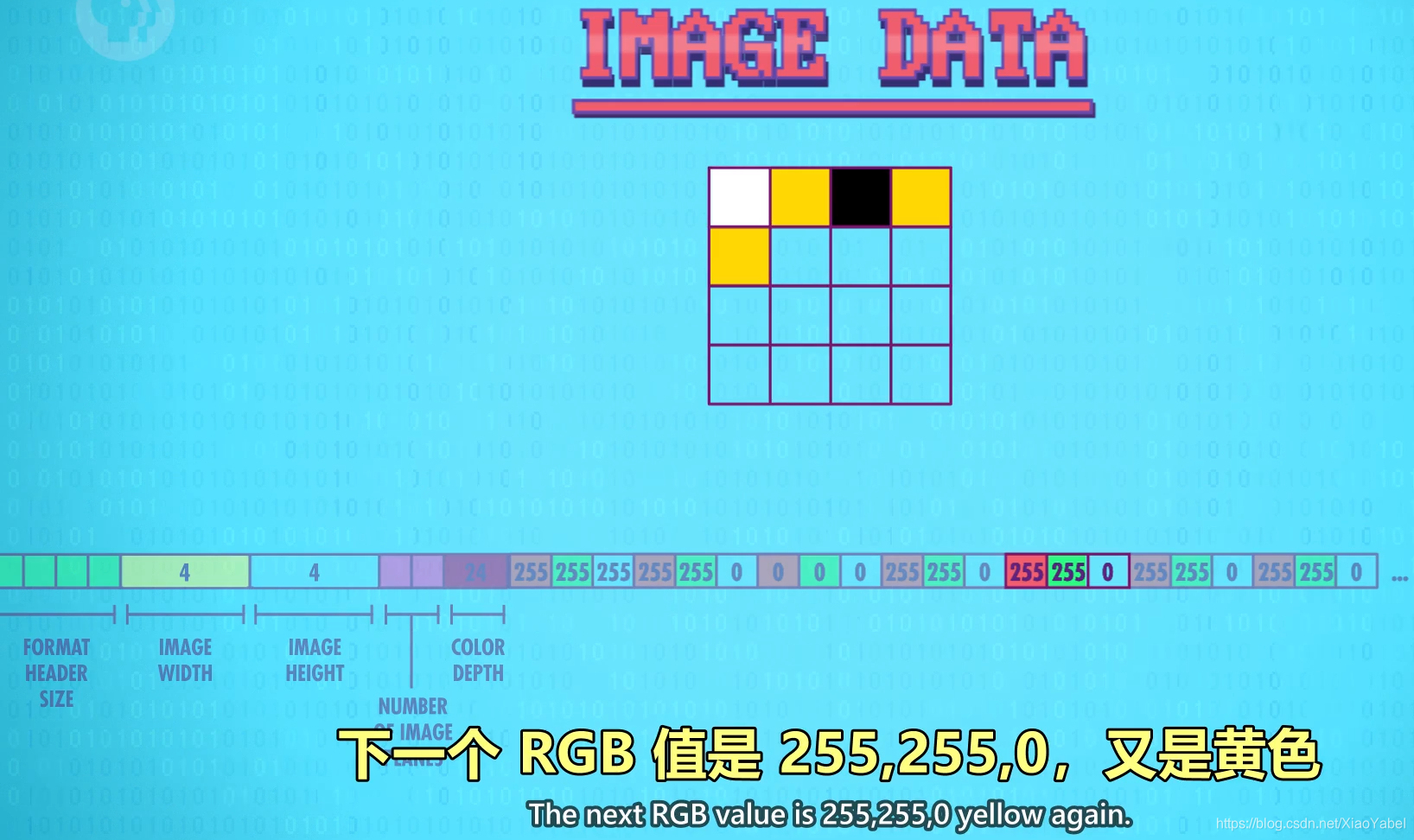
- 文件在底层全一样:一长串二进制
- 分辨不同的文件,文件格式至关重要
2、计算机存储文件
- 忽略存储数据硬件,通过软硬件抽象可以看作一排存数据的桶
- 文件系统:
- 很早期时空间小,整个存储器就像一个文件,数据从头存到尾,直到占满。
- 计算机能力和存储容量提高,存多文件非常必要
- 最简单的方法,把文件连续存储
- 文件开头和结尾未知
- 储存器无文件概念,只是存储大量位
- 为存多个文件,需要特殊文件(比如,目录文件)记录其他文件位置
- 专门负责管理文件
- 目录文件:
- 用来解决多文件问题,存其他文件的信息,比如开头、结尾,创建时间等
- 常存在最开头,方便查找,位置0
- 目录文件存储内容
- 存所有其他文件名字。格式:文件名+ . +扩展名(扩展名有助得知文件类型)
- 存文件的元数据,比如创建时间/最后修改时间/文件所有者/是否能读写
- 有文件起始位置和长度
- 增删改文件,必须更新目录文件
- 目录文件,以及对目录文件的管理,是一个简单的文件系统例子
- 平面文件系统-Flat File System:
- 文件都在同一个层次(同一个目录),早期空间小,只有十几个文件,平面系统够用
- 文件前后排在一起的问题:
- 前一文件加数据会覆盖掉后一文件一部分
- 现代文件系统会:(类似虚拟内存)
- 把空间划分成一块块,使有一些“预留空间”可以方便改动,同时也方便管理
- 目录文件需要记录文件在哪些块里
- 拆分文件,存在多个块里
- 某文件数据量增加,文件系统会分配块,容纳额外数据
- 目录文件会记录不止一个块而是多块
- 分配块,文件可以轻松增大缩小
- 因为一个文件在多个块里,隔开了顺序也是乱的,就产生了文件碎片fragmentation
- 碎片,是增删改文件导致的。对很多存储技术来说不方便。
- 删除文件时,只需要在目录文件删除记录,让空间可用
- 没有擦除数据,只是删除记录
- 之后某时刻,这些块会被新数据覆盖,在此之前,数据还在原处
- 所以可以“恢复数据”
- 把空间划分成一块块,使有一些“预留空间”可以方便改动,同时也方便管理
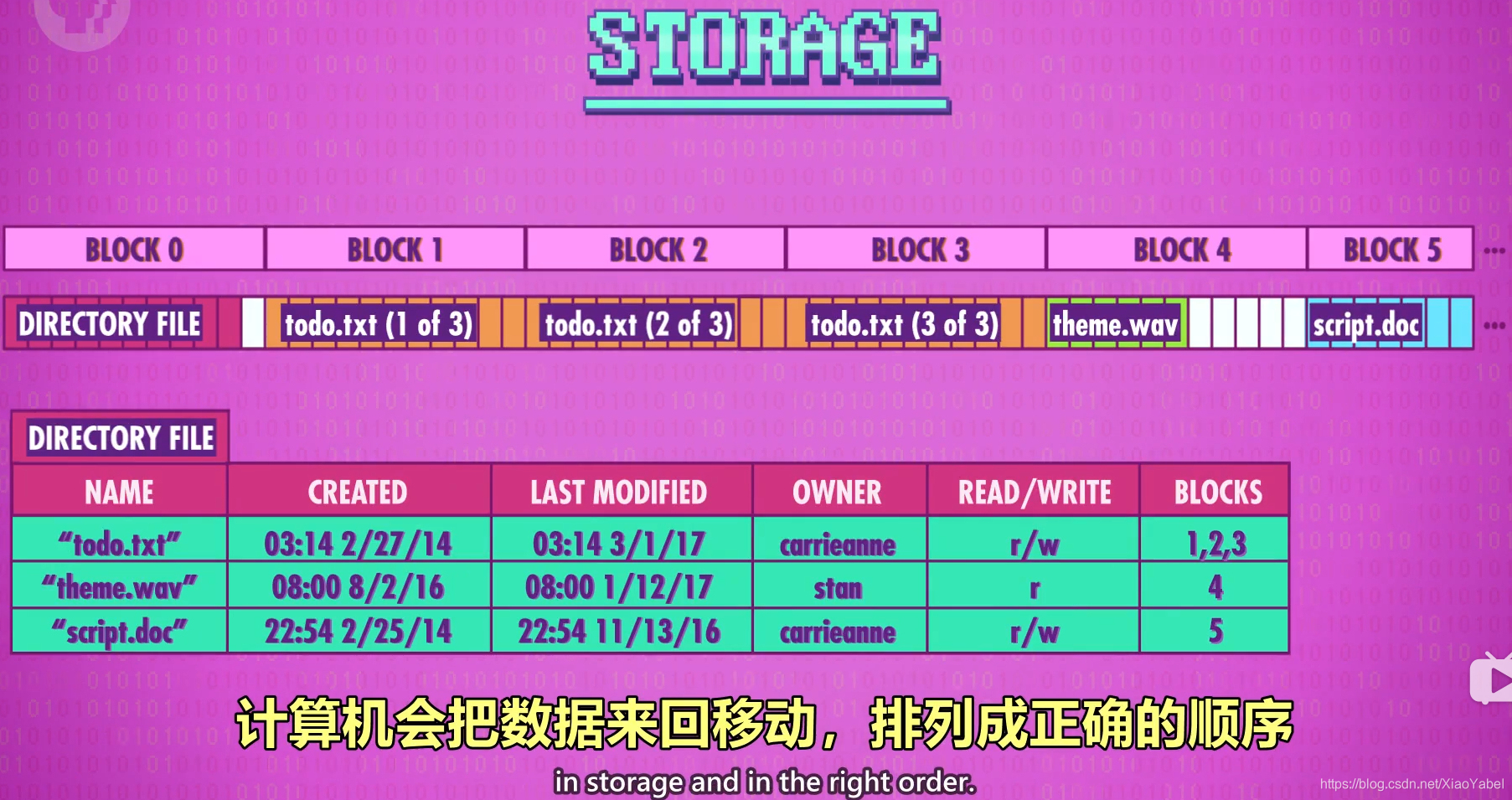
- 碎片整理defragmentation:
- 文件的增删改查会不可避免的造成文件散落在各个块里
- 如果是磁带这样的存储介质就会造成问题,所以做碎片整理
- 计算机会把数据来回移动,排列成正确的顺序,方便读取
- 文件的增删改查会不可避免的造成文件散落在各个块里
- 分层文件系统-Hierarchical file system:
- 有不同文件夹,文件夹可以层层嵌套
- 目录文件
- 不仅要指向文件,还要指向目录
- 需要额外元数据,来区分开文件和目录
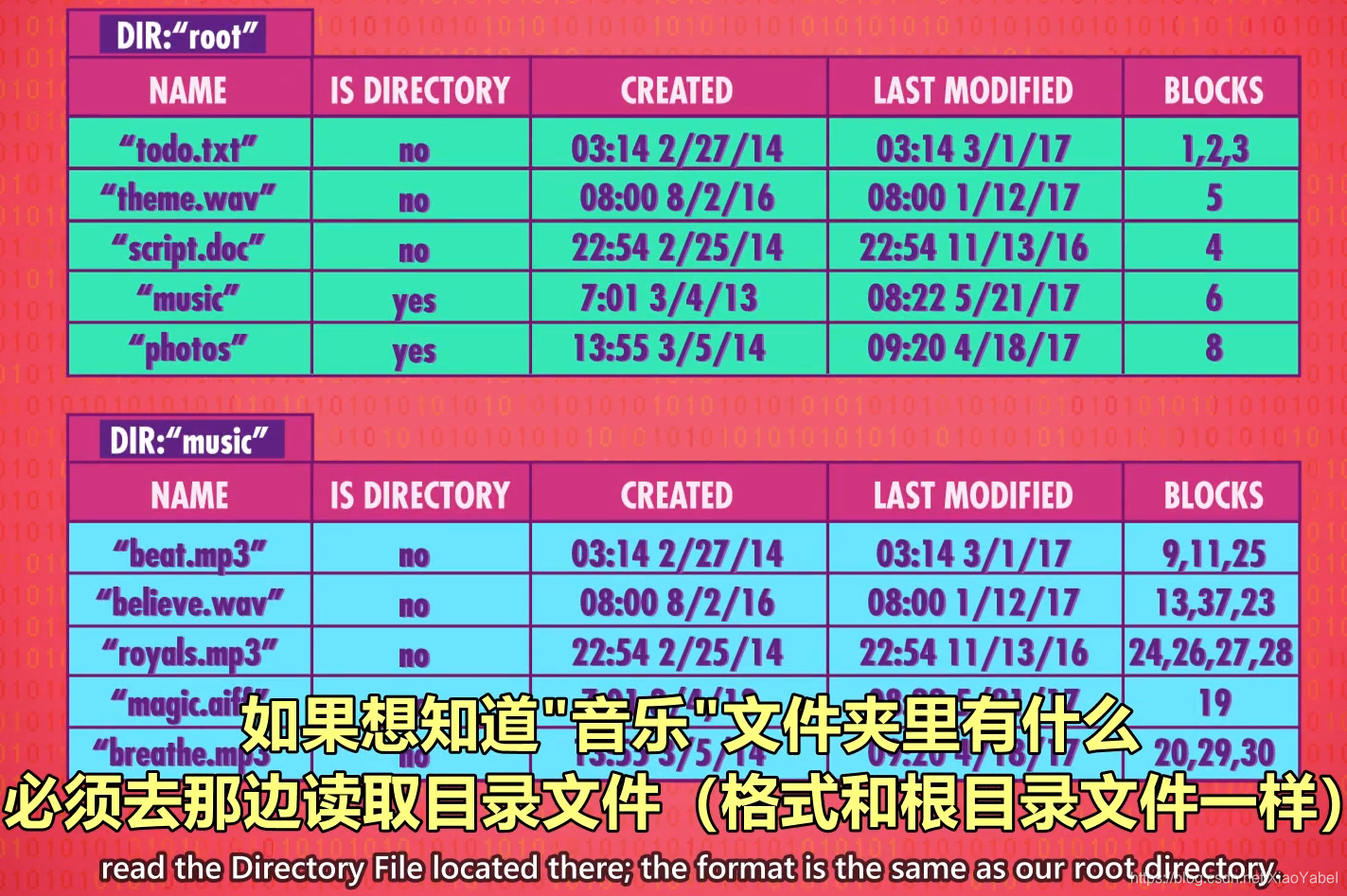
- 根目录:最顶层的目录文件。
- 所有其他文件和文件夹,都在根目录下
- 举例:
- 根目录文件有3个文件,两个子文件夹
- 子文件内容必须去里面读取目录文件(格式和根目录文件一样)
-
- 文件夹可以无限深度
- 轻松移动文件
- 不用启动任何数据块
- 只需要改两个目录文件,一个文件里删除一条记录,另一个文件里加一条记录
3、概念抽象
- 文件系统使不用关心文件在磁带或磁盘的具体位置,整理和访问文件更方便
- 普通用户可直观操作数据。如,打开和整理文件
第二十一课 压缩
0、概念梳理
- 压缩的好处是能存更多文件,传输也更快
- 游程编码Run-length encoding
- 无损压缩lossless compression
- 霍夫曼树 Huffman tree
- “消除冗余”和“用更紧凑的表示方法”,这两种方法通常会组合使用
- 字典编码 dictionary coders,游程编码和字典编码 都是无损压缩
- 感知编码 perceptual coding
- 有损压缩 jpeg格式
- 时间冗余 temporal redundancy
- MPEG-4 视频编码
1、编码方式
- 游程编码Run-length encoding
- 减少重复信息,适合经常出现相同值的文件
- 比如图片数据,有多个连续相同颜色像素,可以插入一个额外字节代表!然后删掉后面的重复数据
- 为了让计算机能分辨哪些字节是‘长度",哪些字节是“颜色”,格式要一致
- 所以要给所有像素前面标上长度
- 无损压缩lossless compression
- 没有损失任何数据,可以轻易恢复到原来的数据(解压缩后,数据和压缩前完全一样)
- 字典编码 dictionary coders
- 用更紧凑的方式表示数据块
- 类似缩写,需要字典,存储“代码”和“数据”间的对应关系
- 把图像看成一块块,而不是一个个像素。比如,把两个像素当成1块(占6个字节)也可以更多
- 为相同的块,生成紧凑代码。块的出现频率不同。频率最高的用最紧凑的形式来表示,出现频率低的可以用更长的东西表示
- 哈夫曼树 Huffman tree
- 算法
- 首先,列出所有块和出现频率,每轮选两个最低的频率,可以把它们组成一个树,总频率为其频率和
- 将组合的一个树放入块中,重复上述过程,选频率最低的两个,放在一起,并记录总频率
- 直到组合成一棵树(并且有按频率排序的属性,频率最低的在下面)
- 字典也要保存,存在树数据的前面,否则数据毫无意义。
- 算法
- “消除冗余”和“用更紧凑的表示方法”,这两种方法通常会组合使用
- 几乎所有无损压缩格式都使用了,比如gif、png、pdf、zip、
- 字典编码 dictionary coders,游程编码和字典编码 都是无损压缩
- 有损压缩技术lossy compression techniques
- 某些文件,可以丢掉一些数据,人无法识别的
- 声音为例,某些频率听不见比如超声波,对重要频率的声音无损化
- 有损音频压缩利用这点,用不同精度编码不同频段
- 压缩音频为使更多人同时通话,网速慢压缩算法会删除更多数据
- 压缩音频文件,如MP3,能小10倍多
- 感知编码 perceptual coding
- 删掉人类无法感知的数据的方法
- 它依赖于人类的感知模型,模型来自“心理物理学psycho physics”领域
- “有损压缩图像格式”的基础,最著名的是JPEG
- 人的视觉,善于看到尖锐对比,比如物体边缘,看不出颜色的细微变化
- JPEG把图像分解成8*8像素块,然后删掉大量高频率空间数据
- 图片用无损技术很难压缩,因为太多不同点(几乎每个像素都和相邻像素不同)
- 因此可以删掉很多,用一个简单的块代替
- 视频只是一长串连续图片,所以图片的很多方面也适用于视频
- 视频可以做些小技巧,因为帧和帧之间很多像素一样——这叫,时间冗余 temporal redundancy
- 视频不用每一帧都存这些像素,可以只存变了的部分
- 当帧和帧之间有小小的差异时,很多视频编码格式,只存变化的部分,这比存所有像素更有效率,利用了帧和帧之间的相似性
- 更高级的视频压缩格式,会更进一步。找出帧和帧之间相似的补丁,然后用简单效果实现,比如移动和旋转,变亮变暗。
- 常见标准
- MPEG-4,比原文件小20倍到200倍
- 但用补丁的移动和旋转来更新画面,当压缩太严重时会出错,没有足够空间更新补丁内的像素
- MPEG-4,比原文件小20倍到200倍
- 压缩
- 高效存储图片,音乐,视频
第二十二集 命令行界面
0、概念梳理
- 重点:
- 计算机早期同时输入程序和数据(用纸卡/纸带)运行开始直到结束,中间没有人类进行操作,原因是计算机很贵,不能等人类慢慢输入,执行完结果打印到纸上
- 到1950年代,计算机足够便宜+快,人类和计算机交互式操作变得可行。为了让人输入到计算机,改造之前就有的打字机,变成电传打字机
- 到1970年代末,屏幕成本足够低,屏幕代替电传打字机(屏幕成为标配)
- 人机交互human-computer interaction
- 早期输出数据是打印到纸上,而输入是用纸卡/纸带一次性把程序和数据输入
- QWERTY打字机的发展
- 电传打字机Teletype machine
- 命令行界面command line interface
- ls命令
- 早期文字游戏 zork(1977年)
- cd命令
1、交互界面
- 输入输出设备Input&output devices
- 和计算机交互,在人类和机器间提供了界面——人机交互
- 交互式:人和计算机之间来回沟通
- 早期机械计算设备
- 用齿轮,旋钮和开关等机械结构来输入输出
- 计算机能同时支持多个程序和多用户
- 多任务
- 分时系统
- 交互操作
- 计算机需要某种方法获得用户输入——键盘
2、打字机
- QWERTY(名字来自键盘左上角按键)
- 布局不同寻常,为了把常见字母放的远一些,避免按键卡住,把很多常见字母放在一起比如TH和ER
- 打字机起初主要是为了易读性和标准化,而不是速度
- 十指打字
- 比一个手指打字要移动的距离短的多,所以速度更快
- 电传打字机Teletype machine
- 早期,专门用来发电报的,可以用电报线发送和接收文本
- 按一个字母,信号会通过电报线发到另一端,使得两端可以长距离沟通
- 因为电传打字机有电子接口,稍作修改就能用于计算机
- 命令行界面command line interface
- 输入一个命令,按回车,然后计算机会输回来,用户和计算机来回“对话”
- 用电传打字机的命令行交互
- 用户可以输入各种命令,举例
- 先看当前目录有什么文件:输入命令ls(list缩写)然后计算机会列出当前目录里所有文件
- 显示文件内容:cat(concatenate) 然后指定文件名(写在cat命令后面)传给命令的值叫参数
- 同一网络找朋友:finger
3、屏幕
- 屏幕类比无限长度的纸,输入和输出字
- 协议相同,计算机无需分辨是纸还是屏幕
- 终端terminal
- 虚拟电传打字机
- 玻璃电传打字机
- Zork
- 早期的著名交互文字游戏
- MUD多人地牢游戏
- 游戏从纯文字进化成多人游戏
- 大型多人在线角色扮演游戏(MMORPG)前身
- 命令行界面简单,功能强大
- 编程大部分依然是打字,命令行比较自然
- 命令行访问远程计算机是最常见的方式,比如服务器在另一个国家
- 命令行界面cmd/terminal
第二十三集 屏幕&2D 图形显示
0、概念梳理
- PDP-1计算机。键盘和显示器分开,屏幕显示临时值
- 阴极射线管CRT
- CRT的两种绘图方式:
- 矢量扫描Vector Scanning
- 光栅扫描Raster Scanning
- 液晶显示器LCD,像素(pixel)
- 字符生成器
- 屏幕缓冲区
- 矢量命令画图
- Sketchpad,光笔(Light pen)
- 函数画线,矩形
1、显示技术
- 早期屏幕的典型用途:
- 跟踪程序的运行情况,比如寄存器的值
- 屏幕更新很快,对临时值简直完美
- 阴极射线管(CRT)
- 把电子发射到有磷光体涂层的屏幕上,当电子撞击涂层时,会发光几分之一秒,由于电子是带电粒子,路径可以用磁场控制
- 屏幕内用板子或线圈,把电子引导到想要的位置
- 2种绘制图形方法
- 引导电子束描绘出形状——矢量扫描
- 按固定路径,一行行来,不断重复,只在特定的点打开电子束,以此绘制图形——光栅扫描。
- 这种方法,可以用很多小线段绘制形状,甚至文字
- 像素:在屏幕上显示清晰的点
- 液晶显示器LCD:
- 也用光栅扫描,每秒更新多次,像素里红绿蓝的颜色
- 早期计算机不用像素
- 像素占用太多内存
- 不存大量像素值,而是存符号,大小更合理
- 额外硬件——字符生成器(基本算是第一代显卡)
- 从内存读取字符,转换成光栅图形,才能显示到屏幕上
- 内部有一小块只读存储器ROM
- 存着每个字符,叫“点阵图案”
- 若图形卡看到一个8位二进制,发现是字母K,会把字母K的点阵图案,光栅扫描显示到屏幕的适当位置
- 屏幕缓冲区
- 为了显示,“字符生成器”会访问内存中一块特殊区域,这块区域专为图形保留
- 程序想显示文字时,修改这块区域里的值就行
- 内存用的少
- 只能画字符到屏幕上,用字符模仿图形界面(用下划线和加号来画盒子,线,和其他简单形状)
- 没办法绘制任意形状
- 扩展ASCII,加新字符
- 某些系统上,可以用额外的bit定义字体颜色和背景颜色
2、CRT上的"矢量模式"
- 矢量模式:
- 所有东西都由线组成,没有文字
- 显示文字,用线条画出来,只有线条
- 举例:
- 假设视频是一个笛卡尔平面200单位宽,100单位高,原点(0,0)在左上角
- 画形状,用矢量命令(早期矢量显示系统——Vectrex)
reset,清空屏幕,把电子枪绘图点移动到坐标(0,0),并把线的亮度设为0
move_to 50 50,把绘图点移动到坐标(50,50)
intensity 100,强度提高到100
move_to 100 50,移动
move_to 60 75
move_to 50 50
intensity 0
即,矢量三角形
- 矢量指令也在内存中,通过矢量图形卡画到屏幕上
- 数百个命令可以按序存在屏幕缓冲区
- 复杂图形,全是现端组成的
- 程序可以更新矢量指令,让图形随时间变化——动画
3、交互式图形界面
- 计算机辅助设计CAD
- 第一个完整的图形程序
- 与图形界面交互的输入设备——光笔
- 有线的连着电脑的触控笔
- 笔尖用光线传感器,可以检测到显示器刷新
- 通过判断刷新时间,电脑可以直到笔的位置
- 光笔和各种按钮
- 用户可以画线和其他简单形状
- 1960年代末,用真正像素的计算机和显示器
- 位图显示:
- 内存中的位(bit)对应屏幕上特殊区域的像素,可以绘制任意图形
- 图形想成一个巨大像素值矩阵
- 帧缓冲区
- 像素数据存在内存中的特殊区域
- 早期时,这些数据存在内存里,后来存在高速视频内存里,简称VRAM
- VRAM在显卡上,访问更快
- 位图显示:
- 画图线——使用循环,把整列像素变成某一颜色
- 矩形,需要1 起始点x坐标 2 起始点y坐标 3 宽度 4 高度;内嵌循环
- 画矩形函数
- 程序员不会浪费时间从零写绘图函数,而是用预先写好的函数来做,画直线,曲线,图形,文字等
第二十四集 冷战和消费主义
- 范内瓦·布什 预见了计算机的潜力,提出了假想机器Memex,帮助建立国家科学基金会,给科学研究提供资金
- 1950年代消费者开始买晶体管设备,收音机大卖
- 日本取得晶体管授权后,索尼做了晶体管收音机,为日本半导体行业崛起埋下种子
- 苏联1961年把宇航员加加林送上太空,导致美国提出登月
- NASA预算大大增加,用集成电路来制作登月计算机
- 集成电路的发展实际上是由军事应用大大推进的,阿波罗登月毕竟只有7次
- 美国造超级计算机进一步推进集成电路
- 美国半导体行业一开始靠政府高利润合同活着,忽略消费者市场,1970年代冷战渐消,行业开始衰败,很多公司倒闭,英特尔转型处理器
- 政府和消费推动了计算机的发展,早期靠政府资金,让技术发展到足够商用,然后消费者购买商用产品继续推动产品发展
第二十五集 个人计算机革命
- 1970年代初成本下降,个人计算机变得可行
- Altair 8800
- 比尔盖茨 和保罗艾伦 写BASIC解释器
- 乔布斯提议卖组装好的计算机,Apple-I诞生
- 1977年出现3款开箱即用计算机:
- Apple-II
- TRS-80 Model I
- Commodore PET 2001
- IBM意识到个人计算机市场
- IBM PC 发布,采用开放架构,兼容的机器都叫IBM Compatible(IBM兼容)
- 生态系统产生雪球效应:
- 因为用户多,软硬件开发人员更愿意花精力在这个平台
- 因为软硬件多,用户也更乐意买IBM兼容 的计算机
- 苹果选封闭架构,一切都自己来,只有苹果在 IBM兼容 下保持足够的shi'chang'f'w
第二十六集 图形用户界面(GUI)
- 图形界面先驱:道格拉斯·恩格尔巴特
- 1970年成立 帕洛阿尔托研究中心
- 1973年完成 Xerox Alto(施乐奥托)计算机
- 桌面隐喻
- 用窗口,图标,菜单和指针来设计界面——WIMP界面
- GUI程序——事件驱动编程
- 提供了一套基本部件
- 可复用的基本元素:按钮、打勾框、滑动条和标签页...
- 代码可以在任意时间执行,以响应事件
- 举例
- 首先,让操作系统为程序创建一个窗口,通过GUI API实现,需要指定窗口的名字和大小
- 再加一些小组件,一个文本框和一个按钮(创建它们需要一些参数)
- 首先要指定出现在哪个窗口,因为程序可以有多个窗口。指定默认文字,窗口位置,以及高宽
- 用户触发事件
- 写一个功能函数,把代码与事件相连,每次触发事件就是触发代码
- 设置事件触发时,由哪个函数处理
- 在初始化函数中,加一行代码实现
- 桌面隐喻
- 1981年的 施乐之星系统
- 文件放入文件夹或桌面来隐喻底层的文件系统
- 史蒂夫·乔布斯去施乐参观
- 所见即所得WYSIWYG
- 1983年推出Apple Lisa
- 1984年推出Macintosh
- 1985年推出Windows1.0,之后出到3.1
- 1995年推出Windows95提供图形界面
- 1995年微软做失败的Microsoft Bob
第二十七集 3D图形
0、概念梳理
- 线框渲染
- 正交投影
- 透视投影
- 网格
- 三角形更常用因为能定义唯一的平面
- 扫描线渲染
- 遮挡画家算法
- 深度缓冲
- Z Fighting错误
- 背面剔除
- 表面法线
- 平面着色
- 高洛德着色
- 纹理映射
- 图形处理单元GPU
3D图形的基础知识
2D的电脑屏幕上,不可能有XYZ立体坐标轴
- 3D投影
- 图形算法,负责把3D坐标“拍平”显示到2D屏幕上
- 投影看起来像3D物体,尽管投影面是平的
- 线框渲染
- 所有点都从3D转成2D后,就可以用画2D线段的函数来连接这些点
- 正交投影
- 立方体的各个边,在投影中互相平行

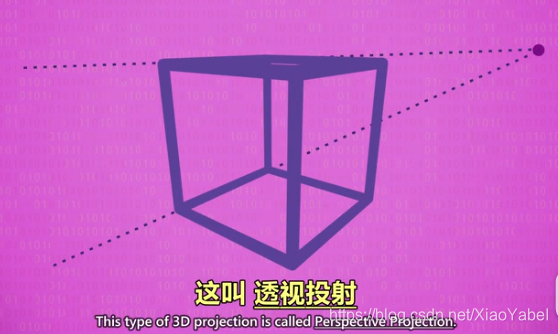
- 透视投影
- 真实3D世界,平行线段会在远处收敛于一点,类比远处的马路汇聚到一点
- 立方体,用直线画;复杂的图形,三角形更好
- 三角形的简单性
- 空间中,三点定义一个平面。
- 三角形的简单性
- 3D图形学中,三角形叫“多边形”
- 网格
- 一堆多边形的集合
- 网格越密,表面越光滑,细节越多,更多的计算量
- 游戏设计者要平衡角色的真实度和多边形数量
- 数量太多,帧率会下降到肉眼可感知,用户会觉得卡。因此有算法简化网格
- 扫描线渲染——填充图形的经典算法
- 多边形如何转成一块填满像素的区域
- 先铺一层像素网格
- 扫描线算法:先读多边形的3个点,找最大和最小的Y值,只在这两点间工作,然后算法从上往下,一次处理一行,计算每一行和多边形相交的2个点
- 因为是三角形,如果相交一条边,必然相交另一条
- 扫描线算法,会填满2个相交点之间的像素
- 多边形如何转成一块填满像素的区域

-
-
- fillrate(填充速率):填充的速度
- 抗锯齿Antialiasing
- 减轻锯齿的方法
- 与其每个像素都涂成一样的颜色,可以判断多边形切过像素的程度,来调整颜色
- 若像素在多边形内部,就直接涂颜色
- 若多边形划过像素,颜色就浅一点。边缘羽化效果
-

- 遮挡
- 3D场景中,多边形到处是,但只有一部分能看见,因为其他被挡住了
- 排序算法,处理
- 从远到近排列,然后从远到近渲染
- 有序后,用扫描线算法填充多边形
- 画家算法
- 画家也先画背景,然后在画更近的东西
- 深度缓冲(用矩阵来存储一个相对标准值,然后记录三个图形,在矩阵中相对于标准的位置)
- 不用排序
- Z-buffering算法会记录场景中每个像素和摄像机的距离,在内存里存一个数字矩阵
- 首先,每个像素的距离被初始化为“”无限大‘
- 然后Z-buffering从列表里第一个多边形开始处理,也就是A
- 和扫描线算法逻辑相同,但不是给像素填充颜色,而是把多边形的距离和Z-buffer里的距离进行对比,它总是记录更低的值
- 因为未对多边形排序,所以后处理的多边形并不总会覆盖前面的,缓冲区里只有一部分值会被多边形C的距离值覆盖(不会覆盖比其距离更低的部分)
- Z缓冲区完成后,会和“扫描线”算法的改进高级版配合使用。不仅可以勘测到线的交叉点,还可以知道某像素是否在最终场中可见
- 若不可见,扫描线算法会跳过那个部分(当两个多边形距离相同时,多边形会在内存中移来移去,访问顺序会不断变化,哪一个在上面不可测)
- 背面剔除BACK-FACE CULLING——3D游戏优化
- 例如,游戏角色的头部或地面,只能看到朝外的一面
- 节省处理时间,会忽略多边形背面,减了一半多边形面数
- bug:若进入模型内部往外看,头部和地面会消失
- 灯光shading——明暗处理
- 3D场景中,物体表面有明暗变化
- 考虑多边形面对的方向,不平行于屏幕,而是面对不同方向
- 法线表面:
- 多边形面对的方向
- 垂直于表面的箭头来显示该方向
- 有光源时,每个多边形被照亮的程度不同
- 因为面对的角度,导致更多光线反射到观察者
- 平面着色——最基本的照明算法
- 背对光源、远离光源所以更暗,只有部分被照亮
- 面对光源显得更亮,对每个多边形执行同样的步骤,物体看上去更真实
- 多边形边界明显,看起来不光滑,算法改善;
- 高洛德着色gouraud shading
- 冯氏着色Phong shading
- 不知用一种颜色给整个多边形上色,而是以巧妙的方式改变颜色,得到更好的效果
- 纹理textures:在图形学中指外观,而不是手感
- 纹理映射texture mapping
- 用“扫描线算法”填充时,可以看内存内的纹理图像,决定像素用什么颜色
- 需要把多边形坐标和纹理坐标对应起来
- 扫描线算法要填充第一个像素时,纹理算法会查询纹理从相应区域取平均颜色,并填充多边形,重复过程,就可以获得纹理
- 纹理映射texture mapping
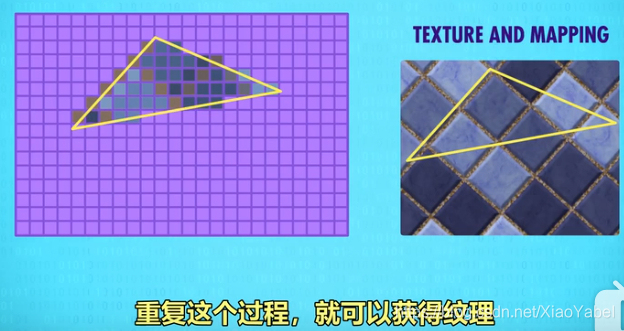
-
- 所有的场景过程都是重复处理所有的多边形
- 加速渲染
- 为特定运算,做专门的硬件来加快速度,让运算快如闪电
- 可以把3D场景分解成多个小部分,然后并行渲染,而不是按顺序渲染
- 图形专门处理器——GPU图形处理单元
- 在显卡上,周围有专用RAM
- 所有网格和纹理都在里面,让GPU的多个核心可以高速访问
第二十八集 计算机网络
0、概念梳理
- 时延:传播一条信息所需的时间
- 1950—1960年代,第一个计算机网络
- 局域网
- 媒体访问控制地址MAC:每台计算机唯一的物理地址
- 指数退避
- 冲突域
- 电路交换
- 报文交换
- 分组交换
1、局域网
- 局域网LAN:计算机近距离构成的小型网络
- LAN技术——以太网Ethernet
- 开发于1970年代,在施乐的“帕洛阿尔托研究者中心诞生”
- 最简单形式:一条以太网电线连接数台计算机
- 当一台计算机要传数据给另一台计算机时,它以电信号形式,将数据传入电缆
- 因为电缆是共享的,连在同一个网络里的其他计算机也是看得到数据,但不知道数据是给它们的,还是给其他计算机的。
- 为此,以太网需要每台计算机都有唯一的,媒体访问控制地址(MAC地址)
- 这个唯一的地址放在头部,作为数据的前缀发送到网络中
- 计算机只需要监听以太网电缆,只有看到自己的MAC地址,才处理数据
- 现在制造的每台计算机(网卡)都自带唯一的MAC地址,用于以太网和无线网
2、载波侦听多路访问CSMA
- 载波侦听多路访问CSMA:多台电脑共享一个传输媒介
- 载体carrier:运输数据的共享媒介
- 以太网的“载体”是铜线
- wifi的“载体”是传播无线电波的空气
- 很多计算机同时侦听载体,所以叫“侦听”和“多路访问”
- 带宽bandwidth:载体传输数据的速度
- 载体carrier:运输数据的共享媒介
- 共享载体弊端:
- 当网络流量较小时,计算机可以等待载体清空,然后传送数据
- 冲突:网络流量上升,两台计算机想同时写入数据的概率也会上升
- 计算机能够通过监听电线中的信号检测这些冲突:
- 当计算机检测到冲突,就会在重传之前等待一小段时间(不同计算机等待时间不同)
- 等1s+随机时间:若再次发生冲突,表明有网络拥塞,这次不等1s而是2s,若再次冲突则4s,增加等待时间直到传输成功
- 因为计算机的退避,冲突次数降低,数据再次开始流动,网络变得顺畅
- 指数退避:指数级增长等待时间的方法
- 减少冲突+提升效率:需要减少同一台载体中设备的数量
3、冲突域
- 冲突域:载体和其中的设备总称
- 一根电缆连接的所有计算机,也叫一个冲突域
- 为了减少冲突,可以用交换机把它拆成两个冲突域
- 交换机:位于两个更小的网络之间,两个网络内可以同时传输数据互不影响,必要时才在两个网络间传数据。它会记录一个列表写着哪个MAC地址在哪边网络
- 多个连在一起的稍小一点的网络,使不同网络间可以传递信息
- 大型网络,从一个地点到另一个地点通常有多条路线
4、路由routing,传输数据的方法
- 电路交换:因为把电路连接到正确目的地
- 连接两台相隔遥远的计算机或网路,最简单的办法是,分配一条专用的通信线路
- 早期电话系统:假设两国家之间有5条电话线,一方要告诉操作员电话打到的地方,工作人员手动将其电话连到通往另一方的未使用线路。通话期间线路被占用,若全部占用要等待某条线空出来
- 缺点:不灵活且价格昂贵
- 优点:若有专线,可以最大限度随意使用,无需共享
- 报文交换:类比邮政系统
- A和B消息会经过好几个站点
- 每个站点都知道下一站发哪里,因为站点有表格,记录到各个目的地,信件该如何传
- 好处:可以用不同的路由,使通信更可靠更能容错
- 跳数hop count:消息沿着路由跳转的次数
- 记录跳数,可以分辨出路由问题,检测错误
- 跳数限制hop limit
- 缺点:报文比较大,会堵塞网络,因为要把整个报文从一战传到下一站后,才能继续传递其他报文
- 当被被大文件堵塞网路时,即使再小的文件也只能等大文件传完,或选另一条效率稍低的路线
- 数据包:将大报文分成很多小块
- 每个数据包都有目标地址,因此路由器知道发送到哪里
- 报文具体格式由“互联网协议”定义,简称IP,该标准创建于1970年代
- 每台联网的计算机都需要一个IP地址
- 同一个报文的多个数据包,会经过不同线路,到达顺序可能会不一样
- IP之上还有其他协议,TCP/IP可以解决乱序的问题
- 阻塞控制:路由器会平衡与其他路由器之间的负载,以确保传输可以快速可靠
- 分组交换
- 将数据拆分成多个小数据包,然后通过灵活的路由传递非常高效且可容错
- 好处:去中心化的,无中心权威机构,无单点失败问题
- 全球路由器协同工作,找出最高效的线路,用各种标准协议运输数据
- 因特网控制消息协议ICMP
- 边界网关协议BGP
- 世界上第一个分组交换网络以及现代互联网的祖先:arpanet
第二十九集 互联网
0、概念梳理
- 局域网:例如,wifi路由器连接所有设备,组成了局域网
- 广域网WAN:局域网再连到广域网
- WAN的路由器一般属于你的“互联网服务提供商”(ISP)
- 广域网里,先连到一个区域性路由器,这路由器可能覆盖一个街区,然后连到一个更大的WAN,可能覆盖整个城市,可能在跳几次,但最终会到达互联网主干
- 互联网主干:由一群超大型、带宽超高路由器组成
- 一个巨型分布式网络,会把数据拆成一个个数据包来传输
- IP-互联网协议:负责把数据包送到正确的计算机
- UDP-用户数据报协议:负责把数据包送到正确的程序
- 校验和
- TCP-传输控制协议
- DNS-域名系统
- OSI-开放式系统互联通信参考模型
IP-互联网协议
- IP:
- 数据很大时,会被拆成多个小数据包
- 数据包packet在互联网上传输要符合“互联网协议”的标准
- IP是一个非常底层的协议
- 数据包的头部只有目标地址。头部存“关于数据的数据”也叫元数据metadata
- IP之上。需要开发更高级的协议
UDP-用户数据报协议
- UDP头部位于数据前面,头部包含有用信息之一是端口号
- 每个想访问网络的程序都要向操作系统申请一个端口号
- 当一个数据到达时,接收方的操作系统会读UDP头部,读里面的端口号
- UDP头部有“校验和”
- 用于检查数据是否正确
- 检查方式是把数据求和来对比
- 发送数据包前,电脑会把所有数据加在一起,算出“校验和”
- UDP中,“校验和”以16位形式存储(16个0/1)
- 如果算出来的和,超过16位能表示的最大值,高位数会被扔掉,保留低位
- 当接收方电脑收到这个数据包,会重复步骤把所有数据加在一起
- 如果结果和头部中的校验和一致代表一切正常;如果不一致,数据肯定坏掉了
- UDP不提供数据修复或数据重发的机制,接收方发现数据损坏,一般只是扔掉
- UDP无法得知数据包是否到达,发送方发了之后,无法知道数据包是否到达目的地
TCP-传输控制协议
- 保证所有数据必须到达
- TCP和UDP一样,头部也存在数据前面
- 端口号
- 校验和
- 高级功能
- TCP数据包有序号
- TCP要求接收方的电脑收到数据包并且“校验和”检查无误后(数据没有损坏)给发送方发一个确认码,代表收到了
- “确认码”简称ACK,得知上一个数据包成功抵达后,发送方会发下一个数据包
- 假设发出未收到确认码,可能出错,若过了一定时间还未收到确认码,发送方会再发一次
- 若收到重复的数据包就删掉
- TCP可以同时发多个数据包,收多个确认码,不用浪费时间等确认码
- 确认码的成功率和来回时间可以推测网络的拥堵程度
- TCP用此信息,调整同时发包数量,解决拥堵问题
- TCP可以处理乱序和丢失数据包,丢失重发,可以根据拥挤情况主动调整传输率
- 计算机访问网站: 1、IP地址;2、端口号
DNS-域名系统
- 域名和IP地址一一对应
- DNS会查表,若域名存在,就返回对应IP地址
- 一般DNS服务器是互联网供应商提供的
- DNS存储存成树状结构
- 顶级域名
- 二级域名
- 子域名
- 不同服务器负责树的不同部分
OSI-开放式系统互联通信参考模型
- 物理层:线路电信号,以及无线网络的无线信号等
- 数据链路层:负责操控“物理层”;媒体访问控制地址MAC,碰撞检测,指数退避,以及其他一些底层协议
- 网络层:负责各种报文交换和路由
- 传输层:UDP和TCP等协议,负责在计算机之间进行点到点的传输,还会检错和修复错误
- 会话层:会使用TCP和UDP来创建连接,传递信息,然后关掉连接
- 表示层
- 应用程序层

- 网络通信划分多层
- 每一层处理各自的问题
第三十集 万维网
0、概念梳理
- 万维网:万维网在互联网之上运行
- 互联网是传递数据的管道,各种程序都会用,其中传输最多数据的程序是万维网分布在全球数百万个服务器上
- 可以用”浏览器“来访问万维网
- 超链接:页面内,去往其他页面的链接
- URL-统一资源定位器:为了使网页能相互连接,每个网页需要一个唯一的地址
- HTTP-超文本传输协议
- HTML-超文本标记语言
- 简单网页
- 第一个浏览器和服务器是Tim Berners-Lee花了2个月在CERN写的
- 1991正式发布,万维网诞生
- 搜索引擎
- JumpStation
- Jerry和david的万维网指南-Yahoo
- 网络中立性
1、万维网
- 万维网的最基本单位:是单个页面
- 超链接:页面内,去往其他页面的链接(点击文字或图片跳转另一个页面)
- 多个超链接形成巨大的互联网络
- 可以在相关主题间轻松切换
- 超联链出现之前,计算机每次想看另外一个信息时,需要在文件系统中找到它,或者把地址输入搜索框
- 1945,vannevar bush意识到超链接的价值
- 关联式索引,选一个物品会引起另一个物品被立即选中
- 将两样东西联系在一起的过程很重要,在任何时候,当其中一件东西进入视线只需要点一下按钮,立马就能回忆起另一件
- 强大的文字链接——超文本
- 常指另一个网页,然后网页由浏览器渲染
- 1945,vannevar bush意识到超链接的价值
2、URL—HTTP
- 统一资源定位器URL:为了使网页能相互连接,每个网页需要一个唯一的地址
- 当你访问网站
- 计算机首先会DNS查找,DNS查找的输入是一个域名
- 返回了一个IP地址,浏览器会打开一个TCP连接到这个IP地址,这个地址运行着”网络服务器“
- 网络服务器的标准端口是80端口,这是计算机连到了访问网站的服务器
- 下一步是向服务器请求某个页面,此时用到超文本传输协议(HTTP)
- HTTP超文本传输协议
- 1991年,HTTP的第一个标准,HTTP9.0,只有一个指令——”GET“指令
- 向服务器发送指令”“GET/页面名”
- 该指令以“ASCII编码”发送到服务器
- 服务器会返回该地址对应的网页,然后浏览器会渲染到屏幕上
- 若用户点了另一个链接,计算机会重新发一个GET请求
- 浏览网站时,上述步骤不断重复
- HTTP添加了状态码
- 状态码放在请求前面
- 200 找到网页并发送给你
- 400~499 客户端出错
- 404 网页不存在
- “超文本”的存储和发送都是以普通文本形式
- 编码可能是ASCII或UTF-16
- 若只有纯文本无法表明什么是链接,什么不是链接需要标记方法,因此开发了超文本标记语言HTML
- 1990年,HTML第一版本0.8
- 18种HTML指令:标签、属性
- 最新版HTML,HTML5,有100多种标签
- CSS、JavaScript可以加进网页做一些做一些更厉害的事情
- 1991年,HTTP的第一个标准,HTTP9.0,只有一个指令——”GET“指令
3、网页浏览器web browsers
- 网页浏览器可以和网页服务器沟通
- 浏览器不仅获取网页和媒体,获取后还负责显示
- 浏览器和服务器——建立了几个基本网络标准URL,HTML,HTTP
- Apache和微软互联网信息服务(IIS)
- 万维网诞生
3、搜索引擎
- 随着万维网日益繁荣,在不知道网站地址的情况下需要搜索
- 最符合现代最早的搜索引擎JumpStation——有3个部分
-
- 爬虫Web crawler
- 一个跟着链接到处跑的软件
- 每当看到新链接,就加进自己的列表里
- 不断扩张的索引index
- 记录访问过的网页上,出现过哪些词
- 查询索引的搜索算法
- 爬虫Web crawler
- 早期搜索引擎的排名方式
- 取决于搜索词在页面上的出现次数(网页过度出现高频词汇吸引人点击)
- 谷歌发明算法规避这个问题
- 与其信任网页上的内容,搜索引擎会看其他网站有没有链接到这个网站,若是有有用内容有网站会指向它,所以这些“反向链接”的数量,特别是有信誉的网站代表了网站质量
4、网络中立性net neutrality
- 数据包——路由——万维网
- 网络中立性
- 应该平等对待所有数据包,不论这个数据包是谁的邮件,或者是谁看的视频,速度和优先级应该是一样的
- 但很多公司会乐意让它们的数据优先到达
- 节流throttled:故意给更少带宽和更低优先级
- 网络中立性让公司无法使自己的内容优先到达,节流其他线上视频
第三十一集 计算机安全
0、概念梳理
- secrecy,integerity,available保密性,完整性,可用性
- threat model 威胁模型
- 身份验证authentication的三种方式
- What you know
- What you have
- What you are
- 访问控制Access Control
- Bell LaPadula model不能向上读取,不能向下写入
- 隔离Isolation,沙盒Sandbox
1、计算机安全
- 网络安全减少虚拟世界中的犯罪、
- 计算机安全,看成是保护系统和数据的:保密性,完整性和可用性
- 保密性
- 只有有权限的人才能读取计算机系统和数据
- 攻击保密性
- 黑客泄露别人的信用卡信息
- 完整性
- 只有有权限的人才能使用和修改系统和数据
- 攻击完整性
- 黑客知道你的邮箱密码,假冒你发邮件
- 可用性
- 有权限的人,应该随时可以访问系统和数据
- 攻击可用性
- 拒绝服务攻击(DDOS)就是黑客发大量的假请求到服务器,让网站很慢或者挂掉
- 威胁模型分析
- 为实现这三个目标,安全专家会从抽象层面想象“敌人”可能是谁
- 模型会对攻击者有个大致描述:能力如何,目标可能是什么,可能用什么手段(攻击手段又叫“攻击矢量attack vector”)
- 能为特定情境做准备,不被可能的攻击手段数量所淹没,因为手段实在有太多种
- 如何保护计算机安全,具体取决于对方,会以能力水平区分
- 在给定的威胁模型下,安全架构师要提供解决方案,保持系统安全,只要某些假设不被推翻
2、身份认证
- 安全问题
- 安全问题可以总结成:你是谁?你能访问什么?
- 权限应该给合适的人,拒绝错误的人,区分身份——“身份认证”
- 身份认证authentication
- What you know
- 基于某个秘密,只有用户和计算机知道(比如用户名和密码)
- 暴力攻击——试遍所有可能,某种情况下对于计算机来说很简单
- 字符增加组合与可能性
- What you have
- 基于用户有特定物体,比如钥匙和锁
- What you are
- 基于你,把特征展示给计算机进行验证
- “生物识别”有概率性,系统可能认不出或者错认
- 所有认证方法都有优缺点,都可以被攻破
- 对于重要账户,安全专家建议用两种或两种以上的认证方式
- What you know
3、访问控制Access Control
- 访问控制
- 一旦系统知道你是谁,它需要知道你能访问什么,因此有个规范说明谁能访问什么,修改什么,使用什么
- 通过“权限”或“访问控制列表”(ACL)来实现
- 其中描述了用户对每个文件,文件夹和程序的访问权限
- “读”权限:允许用户查看文件内容
- “写”权限:允许用户修改内容
- “执行”权限:允许用户运行文件,比如程序
- Bell LaPadula model模型
- 不能向上读取,不能向下写入
- 假设有三个访问级别:公开,机密,绝密
- 有最高等级也不能改等级更低的文件,这样也确保了“绝密”不会意外泄露到“机密”文件会“公共”文件里
- 其他的访问控制模型
- 防火墙
- 比伯模型
4、独立安全检查和质量验证
- 减少漏洞出现的可能性,及时修复;当程序被攻破时尽可能减少损害;为减少执行错误,减少执行
- “安全内核”——系统级安全的圣杯之一
- “可信计算基础”——一组尽可能少的操作系统软件,安全性都是接近可验证的、
- 构建安全内核的挑战在于决定内核应该有什么,且代码越少越好
- 在最小化代码数量之后,要是能“保证”代码是安全的,会很好
- 正式验证代码的安全性
- independence verification and validation独立安全检查和质量验证
- 让一群安全行业内的软件开发者来审计代码,开源
- 优秀的开发人员
- 计划当程序被攻破后,如何限制损害,控制损害的最大程度且不让它危害到计算机上其他东西——隔离
- 实现“隔离”
- “沙盒”程序:操作系统会把程序放到沙盒里,方法是给每个程序独有的内存块,其他程序不能动
第三十二集 黑客与攻击
0、概念梳理
- 社会工程学social engineering
- 钓鱼phishing
- 假托pretexting
- 木马Trojan horses
- NAND镜像
- 漏洞利用exploit
- 缓冲区溢出buffer overflow
- 边界检查bounds checking
- 代码注入code injection
- 零日漏洞zero day vulnerability
- 计算机蠕虫worms
- 僵尸网络 botnet
- 拒绝服务攻击DDoS
入侵最常见的方式
- “社会工程学”
- 欺骗别人让人泄密信息
- 或让别人配置电脑系统,变得易于攻击
- 网络钓鱼
- 比如:银行发邮件叫你点邮件里的链接,登陆账号进入类似官网的假网站,当你输入用户名和密码时信息会发给黑客,然后利用你的账号登陆
- 假托
- 攻击者给某个公司打电话假装IT部门,第一通电话一般叫人转接
- 让别人把电脑配置变得容易入侵,或泄露机密信息比如密码或网络配置
- 木马
- 伪装成无害的东西比如照片等隐藏在邮件,实际是恶意软件
- 会偷数据,加密文件勒索
- NAND镜像
- 若能物理接触到电脑,往内存上接几根线复制整个内存
- 复制后暴力尝试密码,直到设备让你等待,把复制的内容覆盖掉内存,本质上重置了内存即不用等待,可以继续尝试密码
- 漏洞利用
- 无法物理接触到电脑,远程攻击一般需要攻击者利用系统漏洞来获得某些能力或访问权限——漏洞利用
- “缓冲区溢出”
- “缓冲区”:一种概称,指预留的一块内存空间
- 溢出缓冲区,让程序或系统崩溃,重要值被垃圾数据覆盖
- 边界检查
- 阻止缓冲区溢出方法是,复制之前先检查长度
- 程序随机存放变量在内存中的位置,即让黑客不知道应该覆盖内存的位置
- 程序可在缓冲区后留一些不用的空间,跟踪里面的值,看是否发生变化,若变化说明有攻击者
- 金丝雀canaries:不用的内存空间
- 代码注入
- 常用于攻击数据库的网站
- 一种流行的数据库API,结构化查询语言SQL,在验证用户密码的sql语句利用分号进行删表等操作
- 零日漏洞
- 软件制造者不知道软件有新漏洞被发现
- 保持系统更新及安全性补丁
- 蠕虫
- 若有足够多的电脑有漏洞让恶意程序可以在电脑间互相传播
- 僵尸网络
- 黑客拿下大量电脑,这些电脑可以组成“僵尸网络"
- 可以用于很多目的,比如发大量垃圾邮件,用他人电脑计算能力和电费挖Bitcion或发起DDoS攻击服务器
- DDoS拒绝服务攻击
- 僵尸网络里的所有电脑发一堆垃圾信息堵塞服务器
第三十三集 加密
0、概念梳理
- 多层防御defence in depth
- 加密
- 凯撒加密
- 替换加密
- 移位加密
- 列移位加密
- 德国加密机
- 1977年”数据加密标准“DES
- 2001年”高级加密标准“AES
- 密钥交换
- 用颜色来举例”单向函数“和”密钥加密“的原理
- 迪菲-赫尔曼密钥交换
- 非对称加密
- 非对称加密算法RSA
对于漏洞,系统架构师会部署”多层防御“,用多层不同的安全机制来阻碍攻击者
1、计算机安全中最常见的防御形式——密码学cryptography
- 密码学:
- 为了加密信息,要用加密算法cipher把明文转为密文
- 加密encryption:把明文转为密文
- 解密decryption:把密文恢复回明文
- 凯撒加密
- 信件中的字母向前移动几个位置
- 解密
- 用了什么算法
- 要偏移的字母位数
- 替换加密
- 算法把每个字母替换成其他字母
- 根据字母出现频率等,熟练的密码破译师可以从统计数据中发现规律,进而破译密码
- 移位加密
- 列移位加密
- 明文放入网格
- 为了加密信息换个顺序来读,从左往右,从下往上,一次一列
- 加密后字母的排列不同
- 解密关键:读取方向和网格大小
- 列移位加密
2、加密机器
- 1900,德国的英格玛enigma:纳粹在战时用英格玛加密通讯信息
- 加密的关键:一系列”转子“rotros,用于替换字母

-
- 反射器:每个引脚会连到另一个引脚,并把信号发回给转子
- 插板:可以把输入键盘的字母预先进行替换,又加了一层复杂度
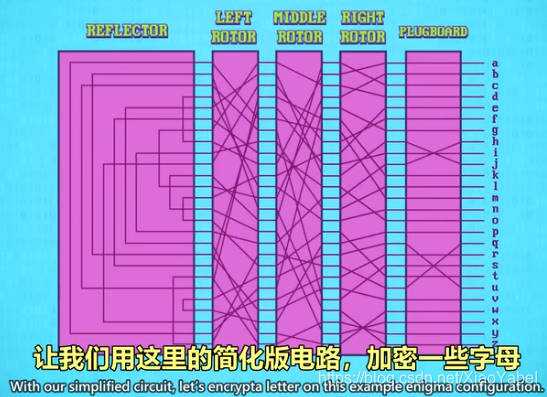
-
- 按下"H"键,电流会先通过插板,然后通过转子到达反射器,然后回来转子、插板,并照亮键盘灯板的字母“L”,H就加密成了L,电路是相通的,L同样会加密成H,加密和解密步骤一致
- 为使加密字母不固定,每输入一个字母转子会转一格
- 计算机出现使加密从硬件转往软件
3、加密标准
- 1977,“数据加密标准DES”
- DES最初用的是56bit长度的二进制密钥,意味着有2^56,或大约72千万亿个不同密钥
- 1999年的计算机可以把DES所有可能密钥都尝试,DES不再安全
- 2001,“高级加密标准AES”
- 用更长的密钥128/192/256位
- AES将数据切成一块一块,每块16个字节,然后用密钥进行一系列替换加密和移位加密,再加上一些其他操作,进一步加密信息,每一块数据,会重复这个过程10次或以上(基于性能的权衡)
- AES在性能和安全性间取得平衡
- 上述加密技术依赖于发送者和接收者都知晓密钥,发件人用密钥加密,收件人用相同的密钥解密
- 过去密钥可以口头约定,或依靠物品
- 在公开的互联网上传递密钥给对方
4、密钥交换
- 密钥交换:是一种不发送密钥,但依然让两台计算机在密钥上达成共识的算法
- “单向函数”:一种数学操作,很容易算出结果,但想从结果逆向推算出输入非常困难
- 就比如颜色混合很容易,但想知道混了什么颜色很难,要试很多可能才知道
- 将密钥比喻成一种独特的颜色
- 首先有一个公开的颜色,所有人都可以看到
- 为了交换密钥,把自己的秘密颜色和公开颜色混合,用任何方式都可以然后发送给对方
- 对方同样将其秘密颜色和公开颜色混合然后发给自己
- 自己收到对方的颜色后,把自己的秘密颜色再加入(对方颜色+公开颜色),现在有3种颜色混合
- 对方同样把其秘密颜色再加入(自己颜色+公开颜色),也是3种颜色,并且颜色结果相同
- 可以把颜色当密钥,尽管双方未给对方发过颜色,外部窥探者可以知道部分信息但无法知道最终颜色
- 单向函数—迪菲·赫尔曼密钥交换:建立共享密钥的一种方法
- 单向函数是模幂运算:先做幂运算,拿一个数字当底数,拿一个数字当指数,然后除以第三个数字,最后拿到我们想要的余数(B^x mod M)
- 假设需要算3^5 mod 31=243mod31=26(243/31取余数);重点是若只给余数和基数很难得知指数是多少(3的某次方模31,余数是7,次方是多少要试很多次)数字很大很长想要找到秘密指数是多少几乎不可能
- 迪菲·赫尔曼密钥交换用模幂运算,算出双方共享的密钥
- 首先,有公开的值-基数B和模数M类比公开的油漆颜色,所有人已知
- 我为了向对方发信息,选了一个秘密指数x,然后算B^x mod M的结果这个大数字发送给对方;对方也选了一个秘密指数y,然后把B^y mod M的结果发我
- 为算出双方共用的密钥
- 我把对方给我的数用我的秘密指数x,进行模幂运算
- (B^y mod M)^x=B^xy mod M
- 对方拿我给他的数也进行模幂运算,最终得到一样的数
- (B^x mod M)^y=B^xy mod M
- 我把对方给我的数用我的秘密指数x,进行模幂运算
- 双方有一样的密钥,即使从来未给对方发过各自的秘密指数
- 即可以用B^x mod M的结果这个大数字当密钥,用AES之类的机密技术来加密通信
- 对称加密
- 双方用一样的密钥加密和解密信息
- 凯撒加密、英格玛、AES
5、非对称加密
- 非对称加密:有两个不同的密钥
- 一个公开,一个私有的。
- 用公钥加密信息,只有有私钥的人能解密
- 知道公钥只能加密不能解密,即不对称的
- 私钥加密,公钥解密。
- 该做法用于签名,服务器可以用私钥加密,任何人都可以用服务器的公钥解密。
- 类似一个不可伪造的签名,只有私钥的持有人能加密。这能证明数据来自正确的服务器或个人,而不是某个假冒者
- 非对称加密——RSA
- 访问一个安全网站
- 绿色锁图标代表,用了公钥密码学,验证服务器的密钥,然后建立临时密钥,用对称加密保证通信安全
- 密码学在保护隐私和安全
第三十四集 机器学习&人工智能
0、概念梳理
- 分类
- 分类器
- 特征
- 标记数据
- 决策边界
- 混淆矩阵
- 未标签数据
- 决策树
- 支持向量机
- 人工神经网络
- 深度学习
- 弱AI,窄AI
- 强AI
- 强化学习
1、分类
- 机器学习:机器学习算法让计算机可以从数据中学习,然后自行做出预测和决定
- 分类classification
- 分类器:做分类的算法
- 特征:用数据训练算法,但会减少复杂性于是把数据简化成“特征”
- 用来帮助“分类”的值
- 训练数据
- 收集的数据,由专家做出准确分类,不只记录特征值还会把类别注明——标记数据
- 数据视觉化
- 根据结果作出区分标准,具体的特征范围取值——决策边界
- 混淆矩阵:记录正确数和错误数的表格
- 机器学习算法的目的:最大化正确分类+最小化错误分类
- 把决策空间切成几个盒子,可以用决策树表示
- 生成决策树的机器学习算法需要选择用什么特征来分类,以及每个特征取值
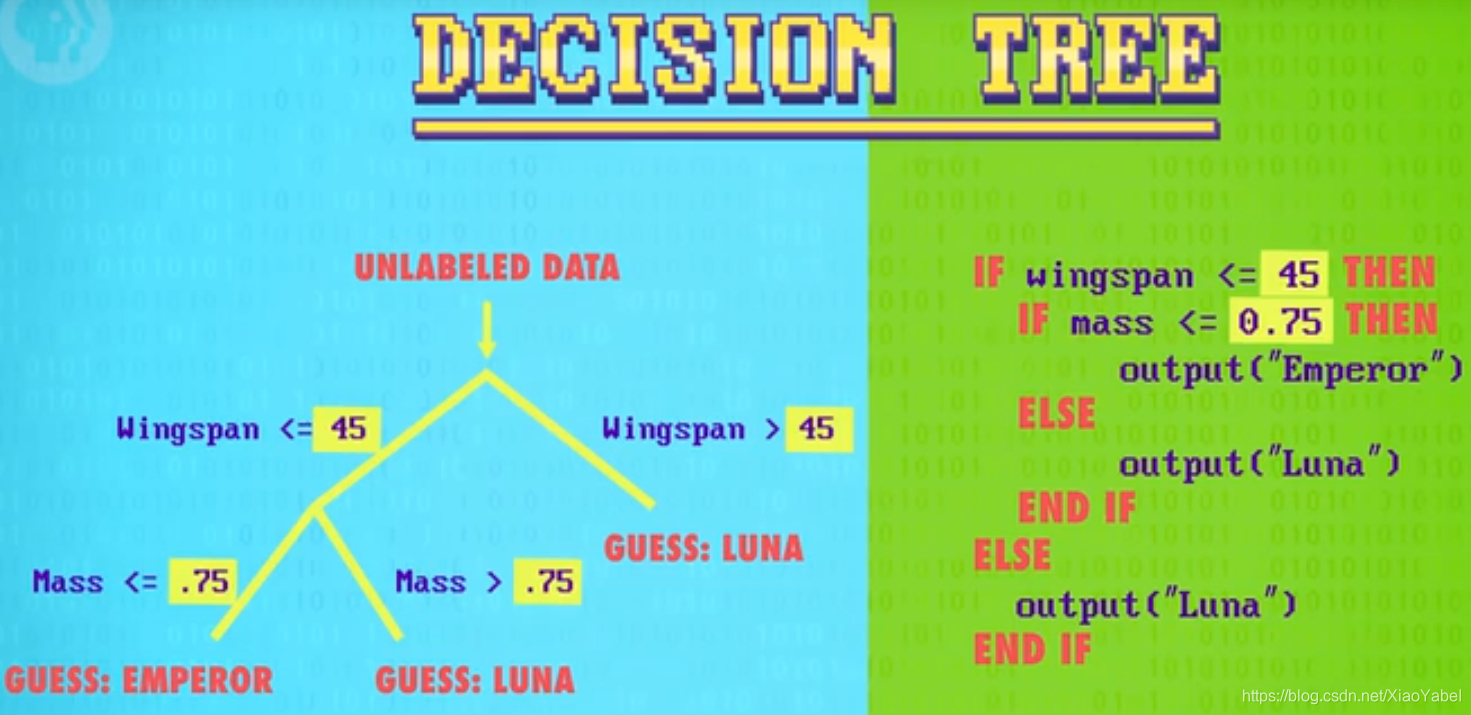
2、支持向量机
- 支持向量机:本质上是用任意线段来切分“决策空间”,不一定是直线,可以是多项式或其他数学函数
- 机器学习算法负责找出最好的线,最准的决策边界

-
- 三维决策边界

-
- 特征多样,导致需要在一个上千维度的决策空间里,给超平面找出一个方程
- “决策树”和“支持向量机”技术源自统计学
3、人工神经网络
- 灵感来源,大脑里的神经元。
- 神经元
- 是细胞,用电信号和化学信号来处理和传输消息
- 从其他细胞得到一个或多个输入,然后处理信号并发出信号,形成巨大的互联网络能处理复杂的信息
- 神经元
- 人造神经元
- 可以接收多个输入,然后整合并发出一个信号
- 它不用电信号或化学信号,而是吃数字进去,吐数字出来
- 它们被放成一层层形成神经元网络,因此得名神经网络
- 输入层:提供需要被分类的单个个体数据
- 输出层:在另一边的神经元,即输出的类别
- 隐藏层:中间,负责把输入变成输出,负责分类
- 神经元
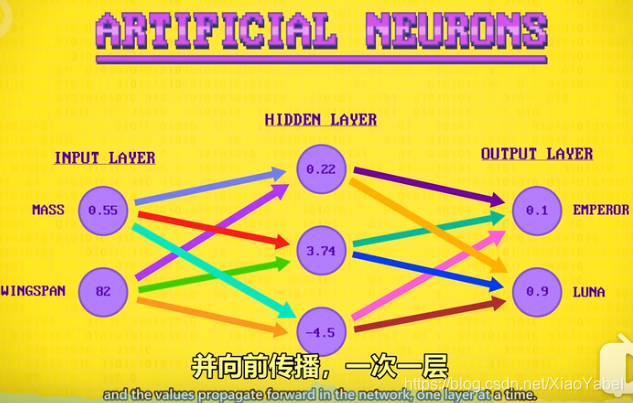
- 首先把每个输入乘以一个权重,然后会相加输入
- 对这个结果用一个偏差值处理:加或减一个固定值
- 做神经网络时,这些偏差和权重,一开始会设置成随机值
- 然后算法会调整这些值来训练神经网络,使用“标记数据”来训练和测试,逐渐提高准确性
- 最后,神经元有激活函数(传递函数),会应用于输出,对结果执行最后一次数学修改(例如,把值限制在某个区间,或把负数改成0)
- 加权——求和——偏置——激活函数:会应用于一层里的每个神经元,并向前传播,一次一层,数字最高的就是结果
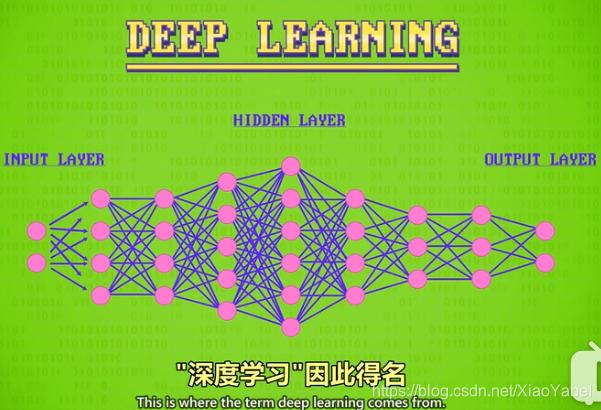
- 深度学习
- 隐藏层有很多层
-
- 训练更复杂的网络需要更多的计算量和数据
4、AI
- 弱AI,窄AI:只能做特定任务
- 强AI:接近人类智能的AI
- AI不仅可以吸收大量信息,也可以不断学习进步,而且一般比人类快
- 强化学习:学习什么管用,什么不管用,自己发现成功的策略(试错)
第三十五集 计算机视觉
0、概念梳理
- 检测垂直边缘的算法
- 核/过滤器
- 卷积
- Prewitt算子
- 维奥拉·琼斯 人脸检测
- 卷积神经网络
- 识别出脸之后,可以进一步用其他算法定位面部标志,如眼睛、眉毛具体位置,从而判断心情等信息
- 跟踪全身的标记点,如肩部,手臂等
- 计算机视觉:目标是让计算机理解图像和视频
- patches:一块块像素,每一块称之patches
- 检测垂直边算法:垂直的颜色变化,某像素是垂直边缘的可能性取决于左右两边像素的颜色差异程度
- 左右像素的区别越大,这个像素越可能是边缘;若色差很小就不是边缘
- 上述操作的数学符号——“核”或“过滤器”,里面的数字用来做像素乘法,总和存到中心像素里
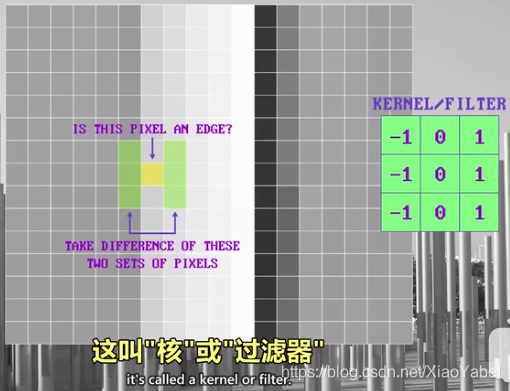
-
- 卷积:把“核”应用于像素块的操作
- 垂直边缘的像素值很高
- 若突出水平边缘要用不同的“核”,用对水平边缘敏感的“核”
- prewitt算子:上述两个边缘增强的核
- “核”能做很多图像转换
- 锐化、模糊
- “核”也可以匹配特定形状
- 边缘检测的“核”会检查左右或上下的差异
- “核”能做很多图像转换
- 卷积神经网络。
- 神经网络的最基本单元,是神经元,有多个输入,然后把每个输入乘以一个权重值,求总和。
- 若给神经元输入二维像素,完全像“卷积”,输入权重等于“核”的但和预定义“核”不同。
- 神经网络可以学习对自己有用的“核”来识别图像中的特征
- “卷积神经网络”用一堆神经元处理图像数据,每个都会输出一个新图像,本质上是被不同的“核”处理了
- 输出后被后面一层神经元处理,卷积卷积再卷积。
- 第一层发现“边缘”这样的特征,单次卷积可以识别出这样的东西
- 下一层可以在上一层基础上识别,比如由“边缘”组成的角落
- 下一层可以在“角落”上继续卷积,可能有识别简单物体的神经元,比如嘴和眉毛
- 不断重复,逐渐增加复杂度,直到某一层把所有特征放到一起
- 计算机,在不同环境会有不同行为
- 生物识别:面部标记点,也可以捕捉脸的形状
- 全身标记点:让计算机理解用户的身体语言
- 硬件层面,有工程师在造更好的摄像头,让计算机有越来越好的视力
- 用来自摄像头的数据,可以用视觉算法找出脸和手
- 用其他算法接着处理,解释图片中的东西,比如用户的表情和手势
第三十六集 自然语言处理NLP
- 词性
- 短语结构规则
- 分析树
- 语音识别
- 谱图
- 快速傅里叶变换
- 音素
- 语音合成
自然语言:人类语言,有大量词汇
第三十七集 机器人
- 法国吃饭鸭
- 土耳其行棋傀儡
- 第一台计算机控制的机器出现在1940年代晚期,叫数控机器CNC
- 1960年,Unimate,第一个商业贩卖的可编程工业机器人
- 简单控制回路
- 负反馈回路
- 比例-积分-微分控制器 PID控制器
- 机器人三定律
第三十八集 机器人计算机心理学
- 了解人类心理学,做出更好的计算机
- 易用度:指的是人造物体,比如软件达到目的的效率有多高
- 颜色强度排序 和 颜色排序
- 分组更好记
- 分块:把信息分成更小,更有意义的块
- 分块浪费内存,浪费屏幕,但这样设计更容易扫视,记住和访问
- 直观功能
- 为如何操作物体提供线索,平板用来推,旋钮用来旋转等
- 广泛用于图形界面
- 认出 vs 回想
- 一般用感觉来触发记忆会容易得多,所以用图标icons代表功能
- 不用回想图标的功能,只要能认出来就可以
- 专业知识
- 当熟悉界面使用会更快
- 需要建立如何高效完成事情的“心理模型”
- 好的界面应该提供多种方法来实现目标。(快捷键/鼠标点击)
- 让机器有一定情商以及Facebook的研究CMC
- 能根据用户的状态做出合适的反应,让使用电脑更加愉快
- 用软件修正注视位置。让视频通话时看起来像盯着对方,而不是盯着下方
- 心理学研究表明,眼神注视很重要
- 相互凝视,可以促进参与感帮助实现谈话目标
- 增强凝视,用于视频会议
- 把机器人做的像人,恐怖谷理论
- 恐怖谷:几乎像人类和真的人类之间的小曲线
- 有很多开放式问题,心理学帮助我们明白不同选择可能带来的影响
- 了解设计背后的心理学能增加易用性
第三十九集 教育科技
- 通过调速,暂停等技巧,加强学习效率
- 大型开放式在线课程MOOC
- 智能辅导系统
- 负责创建和维护学生模型
- 判断规则
- 域模型
- 贝叶斯知识追踪
- 学生已经学会的概率
- 瞎猜的概率
- 失误的概率
- 做题过程中学会的概率
- 自适应式程序
- 软件选择合适的问题呈现给学生,让学生学
- 教育数据挖掘
- ursera/Khan Academy
- 教师和研究人员收集上百万学习者的数据
- 从数据中可以发现常见错误,一般在哪里难道学生
- 除学生的回答,还可以看回答前暂停多久,哪个部分加速
- ursera/Khan Academy
第四十集 奇点,天网,计算机的未来
- 普适计算
- 奇点
- 把工作分为4个象限,讨论自动化带来的影响
- 机器人的存在时间可能长过人类,可以长时间探索宇宙
本文来自互联网用户投稿,文章观点仅代表作者本人,不代表本站立场,不承担相关法律责任。如若转载,请注明出处。 如若内容造成侵权/违法违规/事实不符,请点击【内容举报】进行投诉反馈!