深入了解性能分析与调优
写在前面
这篇文章适合还没有接触过性能调优的同学,主要提供了性能调优的思路,以及如何对CPU,IO,内存,网络,数据库等进行调优以及调优的具体手段,同时介绍了性能调优的流程,容量测试等,可以对性能调优有个大体的框架。
性能监控分析的思路
性能分析在于掌握好分析思路,而不是在于某个具体问题是如何分析,性能监控设计包含以下步骤:
- 首先,你要分析系统的架构。
- 其次,监控要有层次,要有步骤。
- 最后,通过分析全局、再定向的监控数据做分析
通常包括以下几个步骤:
- 确认要监控的应用程序或系统,以及监控的目的和范围。例如,监控某个Web应用程序的性能,或者监控整个服务器或数据库的性能。
- 选择合适的监控工具或系统进行监控。常用的监控工具包括:Nagios、Zabbix、NewRelic、Grafana等。
- 设定监控指标和阈值。根据监控目的和要求,设定需要监控的性能指标,例如CPU使用率、内存占用率、磁盘使用率等,并设定相应的阈值。
- 进行数据采集和分析。监控工具会收集各种性能指标的数据,可以通过数据可视化技术进行分析和展示,帮助管理员快速发现系统的异常和瓶颈。
- 调整系统配置和优化性能。根据分析结果,适时调整系统配置,例如增加服务器内存、优化数据库索引等,提高系统的性能和稳定性。
- 撰写性能分析报告。将分析结果总结成报告,向其他团队成员或上级管理层汇报系统的性能状况和优化措施。
由此可见性能优化是个系统性工程,对工程师的技术广度和深度都有要求。它不仅需要你精通编程语言,还需要深刻理解操作系统、JVM 以及框架原理的相互作用关系,需要你多维度、全方面地去分析排查。
性能优化活动需要注意以下几点:
- 依据数字而不是猜想
- 个体数据不足信
- 不要过早优化和过度优化
- 保持良好的编码习惯
性能优化是基于数据的,性能优化的数据可以从统计指标,链路追踪,日志等途径获取数据,来源包含
- 客户端
- 应用程序
- 业务监控
- 基础设施
总之性能调优涉及到前端、DNS/网关接入层、安全防护、负载均衡、大数据、容器化/编排/网络、web服务器、缓存、队列、压力工具、监控分析工具,代码调优、操作系统、应用服务器和中间件、数据库、网络、存储等方方面面的知识。
如何利用命令行监控服务器指标
监控最原始,最本质的方法:利用命令行监控,以下为查看常用系统指标使用的命令
查看分析CPU指标
Linux top命令是Linux系统中一个实时的性能监控工具,能够展示系统的进程运行情况,包括进程的CPU占用率、内存占用率、进程数等信息。通过top命令,用户可以了解系统的实时性能状态,并及时判断和优化系统性能。
top命令默认以实时更新的方式展示系统进程列表和各个进程的占用率信息,用户可以通过一些快捷操作进行筛选、排序、终止进程等操作。常用的top命令选项包括:
- -d:设置top命令更新进程信息的时间间隔,默认为5秒。
- -u:设置top命令显示某个指定用户的进程信息,例如top -u username。
- -p:设置top命令显示某个指定进程号的进程信息,例如top -p pid。
在使用top命令时,用户可以查看进程列表、各个进程的PID、CPU占用率、内存占用率、进程运行时间等信息,还可以使用快捷键进行操作,如:
-
P:以进程CPU占用率进行排序。
-
M:以进程内存占用率进行排序。
-
k:给某个进程发送信号,以终止该进程。
-
q:退出top命令。
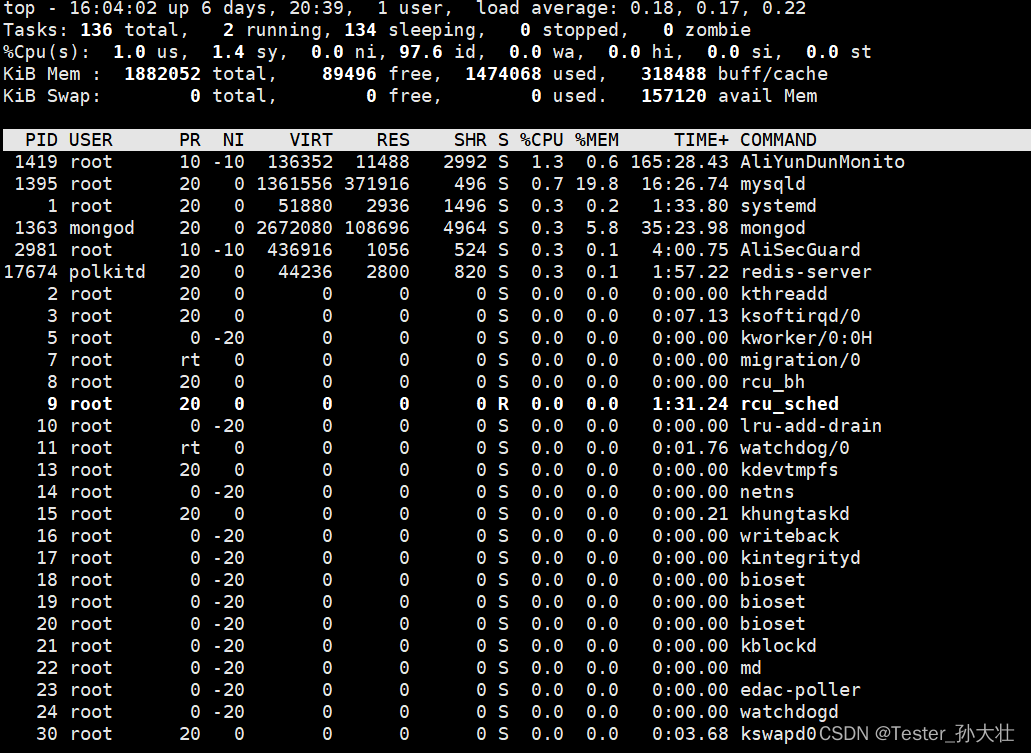
对top命令的说明
第一行:
10:38:10 — 当前系统时间
up 4 days, 17:37 — 系统已经运行了4天17小时37分钟(在这期间没有重启过)
1 user — 当前有1个用户登录系统
load average: 0.23, 0.14, 0.10— load average后面的三个数分别是1分钟、5分钟、15分钟的负载情况。
第二行:
Tasks — 任务(进程),系统共有429个进程,其中处于运行中的有1个,428个在休眠(sleep),stoped状态的有0个,zombie状态(僵尸)的有0个。
第三行:cpu状态
0.0% us — 用户空间占用CPU的百分比。
0.1% sy — 内核空间占用CPU的百分比。
0.0% ni — 改变过优先级的进程占用CPU的百分比
99.8% id — 空闲CPU百分比
0.0% wa — IO等待占用CPU的百分比
0.0% hi — 硬中断(Hardware IRQ)占用CPU的百分比
0.0% si — 软中断(Software Interrupts)占用CPU的百分比
第四行:内存状态
20605080k total — 物理内存总量(20GB)
2020484k used — 使用中的内存总量(2GB)
18584596k free — 空闲内存总量(18G)
324324k buffers — 缓存的内存量 (320M)
第五行:swap交换分区
22708216k 20total — 交换区总量(22GB)
0 used — 使用的交换区总量(0M)
22708216k free — 空闲交换区总量(22GB)
546292k cached — 缓冲的交换区总量(500MB)
第七行以下:各进程(任务)的状态监控
PID — 进程id
USER — 进程所有者
PR — 进程优先级
NI — nice值。负值表示高优先级,正值表示低优先级
VIRT — 进程使用的虚拟内存总量,单位kb。VIRT=SWAP+RES
RES — 进程使用的、未被换出的物理内存大小,单位kb。RES=CODE+DATA
SHR — 共享内存大小,单位kb
S — 进程状态。D=不可中断的睡眠状态 R=运行 S=睡眠 T=跟踪/停止 Z=僵尸进程
%CPU — 上次更新到CPU时间占用百分比
%MEM — 进程使用的物理内存百分比
TIME+ — 进程使用的CPU时间总计,单位1/100秒
COMMAND — 进程名称(命令名/命令行)
分析CPU指标主要关注cpu和Load average
查看分析内存指标
最常见的是通过 free 来查看 Linux 内存使用情况。也可以通过 top 命令,来观测内存的占用
Free命令介绍
- 命令格式
free [-b|-k|-m|-g] [-o] [-s delay] [-c count] [-V]
- 命令功能
free 命令用于显示 Linux 系统中内存的使用情况,包括物理内存、交换空间等
- 命令参数
- -b:以字节为单位显示内存使用情况
- -k:以千字节为单位显示内存使用情况
- -m:以兆字节为单位显示内存使用情况
- -g:以吉字节为单位显示内存使用情况
- -o:不显示缓存区和内核占用的内存
- -s delay:间隔 delay 秒执行命令
- -c count:命令执行次数
- -V:显示命令版本信息
查看分析磁盘IO指标详解
- iostat主要用于输出磁盘IO 和 CPU的统计信息,iostat属于sysstat软件包,可以用yum install sysstat直接安装。

- iotop 是一个类似 top 的工具,用来监视磁盘I/O使用状况。可以用yum install iotop安装。
Linux vmstat命令性能监控
vmstat是一种监控Linux系统性能的工具,它提供了实时的系统信息,可以帮助我们了解系统运行状态和性能瓶颈。vmstat能够输出许多有关操作系统内存、CPU和IO等性能指标的统计信息。
使用vmstat可以轻松地查看系统的内存状况,包括可用内存、swap交换分区使用情况等,还可以监控CPU利用率、上下文切换等。此外,vmstat还可以通过观察等待IO操作的数量,来判断系统的IO性能良好还是出现瓶颈。
使用vmstat的基本命令格式为:
vmstat [options] [delay [count]]
其中,delay表示输出信息的时间间隔,count表示输出信息的次数。
vmstat提供的信息包括以下几方面:
- r – 代表等待运行的进程数;
- b – 代表处于阻塞状态的进程数;
- swpd – 代表已使用的虚拟内存;
- free – 代表可用的物理内存;
- buff – 代表用作缓冲区的内存大小;
- cache – 代表用作缓存的内存大小;
- si – 代表从磁盘交换区载入到内存的数据大小,单位为KB;
- so – 代表从内存交换区写入到磁盘的数据大小,单位为KB;
- bi – 代表从块设备(如硬盘)读取的数据量,单位为KB;
- bo – 代表向块设备(如硬盘)写入的数据量,单位为KB;
- in – 代表每秒钟的中断数;
- cs – 代表每秒钟的上下文切换数;
- us – 代表用户进程使用CPU的时间百分比;
- sy – 代表系统进程使用CPU的时间百分比;
- id – 代表CPU空闲时间百分比;
- wa – 代表等待IO操作完成的时间百分比。
通过使用这些信息,我们可以深入了解系统的性能状况,发现和排除性能瓶颈,提高系统的性能和稳定性。
安装:vmstat是在sysstat包里的,安装时执行命令yum install -y sysstat即可。

查看分析网络指标
netstat 能提供 TCP 和 UDP 的连接状态等统计信息,可以简单判断网络是否存在堵塞。
Linux nmon命令性能数据
Nmon工具用来监视 Linux 系统的所有资源包括:CPU、内存、磁盘使用率、网络上的进程、NFS、内核等等。这个工具有两个模式:即在线模式和捕捉模式,在线模式适用于实时监控,捕捉模式用于存储输出为 CSV 格式后的处理。官网: http://nmon.sourceforge.net/pmwiki.php。下载安装步骤:
- wget http://sourceforge.net/projects/nmon/files/nmon16d_x86.tar.gz #下载
- mkdir nmon
- tar -zxvf nmon16d_x86.tar.gz -C ./nmon # -C 是指定解压目录
- chmod +x nmon_x86_64_centos7 # 找到nmon_x86_64_centos6这个文件,并对它添加执行权限
- mv nmon_x86_64_centos7 /usr/local/bin/nmon #把该程序文件加入环境变量运行目录,如果不是管理员,需要加上sudo命令
常用命令
- q : 停止并退出 Nmon
- c : 查看 CPU 统计数据
- m : 查看内存统计数据
- d : 查看硬盘统计数据
- k : 查看内核统计数据
- n : 查看网络统计数据
- t : 查看高耗进程
- V : 查看虚拟内存统计数据
- v : 详细模式
Linux nmon数据收集
性能测试时,需要根据测试场景的执行情况,分析一段时间内系统资源的变化,这时需要nmon采集数据并保存下来,以下是常用的参数:
- -f 参数:生成文件,文件名=主机名+当前时间.nmon
- -T 参数:显示资源占有率较高的进程
- -s 参数:-s 10表示每隔10秒采集一次数据
- -c 参数:-s 10表示总共采集十次数据
- -m 参数:指定文件保存目录
示例:如每隔5秒采集一次,一共采集12次,命令:nmon -f -s 5 -c 12 -m ./nmon
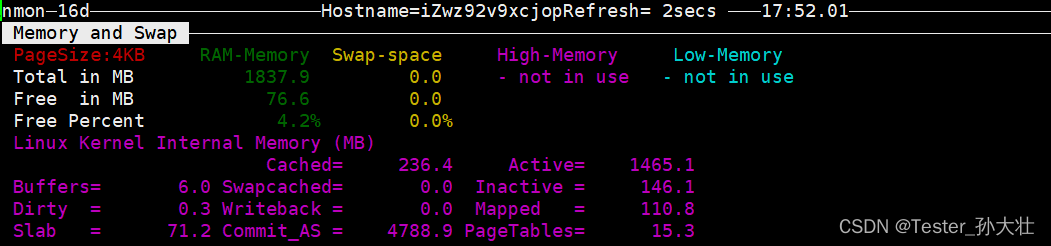
Linux nmon数据分析
- 借助nmon analyser可以把nmon采集的数据生成直观的Excel表,nmon analyser下载地址:http://nmon.sourceforge.net/pmwiki.php?n=Site.NmonAnalyser
- 在Windows上下载后解压,其中的Excel就是nmon analyser工具。
- 打开nmon analyser,双击打开nmon analyser.xlsm,点击Analyze nmon data按钮,选择nmon数据文件,会再
次提示另存为,选择地址保存即可。
压力测试工具: stress
Linux系统下,使用stress 命令用来模拟系统负载较高时的场景,可以对cpu、memory、IO以及磁盘进行压力测试。
语法格式:stress [options] ,安装:
- yum install -y epel-release
- yum install stress -y
常用参数说明:
- -c, --cpu N 产生 N 个进程,每个进程都反复不停的计算随机数的平方根
- -i, --io N 产生 N 个进程,每个进程反复调用 sync() 将内存上的内容写到硬盘上
- -m, --vm N 产生 N 个进程,每个进程不断分配和释放内存
- -d, --hadd N 产生 N 个不断执行 write 和 unlink 函数的进程(创建文件,写入内容,删除文件)
- -t, --timeout N 在 N 秒后结束程序
- -v, --verbose 显示详细的信息
示例: - stress -c 4 # 增加4个cpu进程,处理sqrt()函数函数,以提高系统CPU负荷
- stress -i 4 #产生 4 个进程,调用 sync 函数,以消耗消耗 IO 资源
- stress -m 2 --vm-bytes 300M --vm-keep –timeout 100s # 产生两个子进程,每个进程分配 300M 内存
- stress -d 1 --hdd-bytes 10M # 创建一个进程不断的在磁盘上创建 10M 大小的文件并写入内容

性能问题瓶颈分析思路和应对策略
应用服务器监控:Tomcat
probe也叫psi-probe,用于Tomcat应用状态的监控、数据库连接监控、应用监控、日志信息监控(可以查看所有Tomcat自身的日志信息和Tomcat所管理的应用打印的日志信息,并可根据日志级别过滤所需的日志信息)、监控集群运行状态(部分Tomcat版本可用)、监控所以线程的状态、统计Tomcat连接等。地址:https://github.com/psi-probe/psi-probe/release
java性能分析核心要点
Java程序是如何被运行的
Java程序的运行过程主要分为以下几个步骤:
- 编写源代码:Java程序员使用文本编辑器或集成开发环境(IDE)编写源代码,保存为.java文件。
- 编译源代码:Java程序需要被编译成Java字节码,该字节码可在JVM(Java虚拟机)上运行。Java程序员使用Java编译器将源代码编译成字节码,生成.class文件。
- 加载类:类加载器(ClassLoader)将编译后的字节码加载到JVM中,准备运行。
- 链接类:类加载器会进行链接处理,包括验证字节码、解析符号引用、进行访问控制等。
- 初始化类:在类首次被使用时,JVM会为该类进行初始化,包括静态变量的初始化、静态代码块的执行等。
- 执行程序:经过以上步骤后,Java程序可以被执行,程序开始运行。
Java运行的线程状态
Java 运行的线程状态包括以下几种:
- NEW:线程对象创建但还没有开始执行。
- RUNNABLE:线程正在 JVM 中执行。
- BLOCKED:线程被阻塞,因为它试图获取一个监视器锁,但是该锁正在被其他线程持有。
- WAITING:线程正在等待另一个线程通知它一个特定的条件,例如通过调用 Object.wait()。
- TIMED_WAITING:线程正在按照指定的时间等待另一个线程通知它一个特定的条件,例如通过调用 Thread.sleep() 或者 Object.wait(long)。
- TERMINATED:线程已经完成了执行。
java性能分析工具
在JDK的bin目录下有很多分析调试命令行工具:
- jps:查看本机java进程信息
- jstack:打印线程的栈信息,制作 线程dump文件
- jmap:打印内存映射信息,制作 堆dump文件
- jstat:性能监控工具
- jhat:内存分析工具,用于解析堆dump文件并以适合
人阅读的方式展示出来 - jconsole:简易的JVM可视化工具
- jvisualvm:功能更强大的JVM可视化工具
Linux CPU占用过高排查思路
- 找到最耗CPU的进程PID, 工具:top , 方法:
- 执行top -c ,显示进程运行信息列表
- 键入P (大写p),进程按照CPU使用率排序,找出排名最靠前(最耗CPU)的进程PID。
- 找到最耗CPU的线程NID,工具:top , 方法:
- top -Hp 10765 ,显示一个进程的线程运行信息列表
- 键入P (大写p),线程按照CPU使用率排序,找出最耗CPU的线程nid
- 将线程NID转化为16进制,工具:printf, 方法:
- printf “%x” nid
- 查看堆栈,找到线程在干嘛,工具:pstack/jstack/grep, 方法:jstack 10765 | grep ‘0x2a34’ -C5 --color
- 打印进程堆栈
- 通过线程id,过滤得到线程堆栈
Linux 内存占用过高排查
- 先查看服务器剩余内存容量
free -h - 查看占用内存最大的10个进程:
ps -aux | sort -k4nr | head -n 10 - 查看内存占用最高的pid的线程:
top -Hp <进程pid> - 将线程pid转化成16进制后的数字
printf %x <线程pid> - 导出进程的堆栈信息
jstack -l <进程pid> > <进程pid>.log - 查看堆栈信息,并找到在第四步中生成的16进制的线程ID
磁盘IO分析过程
- iostat –x 5 查看IO情况
- 利用iotop查看哪个线程耗IO比较高
- 利用pt-ioprofile定位负载来源文件 ,如:pt-ioprofile --profile-pid=18934 --cell=sizes, pt-ioprofile官网:http://www.percona.com/downloads/percona-toolkit/2.2.1/
pt-ioprofilelinux下安装:
yum -y install https://downloads.percona.com/downloads/percona-toolkit/3.3.1/binary/redhat/7/x86_64/percona-toolkit-3.3.1-1.el7.x86_64.rpm
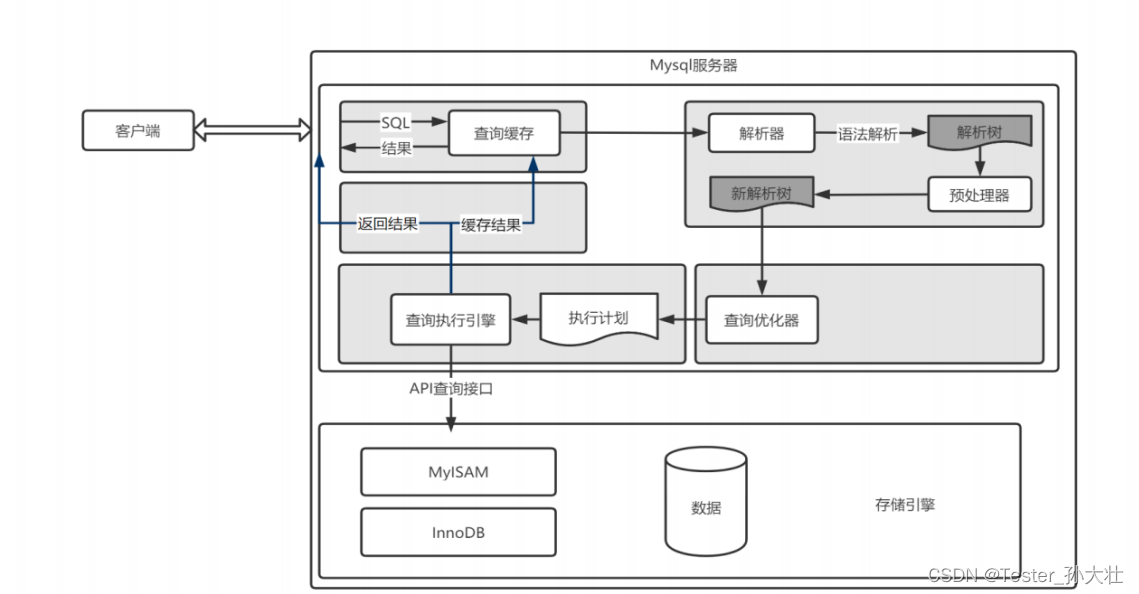
如何优化MySQL
以下为SQL的查询过程,SQL容易出现的问题包含: SQL语句、索引 >系统配置,库表结构>硬件配置
常见问题慢查询的优化
首先,可以打开MySQL的慢查询日志,收集一段时间的慢查询日志内容,然后找出耗时最长的SQL语句,对这些SQL语句进行分析。
set global slow_query_log=on;
set global long_query_time=3;
set global slow_query_log_file=‘XX/slow.log’
比如可以利用执行计划explain去查看SQL是否有命中索引。如果发现慢查询的SQL没有命中索引,可以尝试去优化这些SQL语句,保证SQL走索引执行。如果SQL结构没有办法优化的话,可以考虑在表上再添加对应的索引。我们在优化SQL或者是添加索引的时候,都需要符合最左匹配原则。

如上图:key为null,没有索引,如查询慢可以尝试添加索引。
系统性进行性能测试
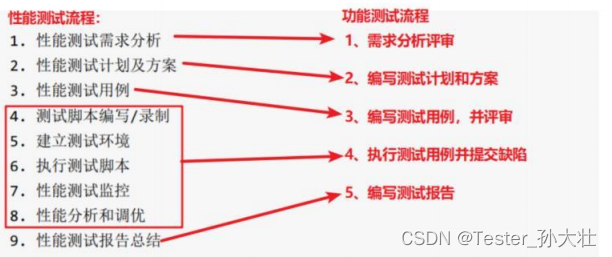
性能测试流程
性能测试包含以下几个流程:
- 性能测试需求分析
- 性能测试计划及方案
- 性能测试用例
- 测试脚本编写与录制
- 建立测试环境
- 执行测试脚本
- 性能测试监控
- 性能分析和调优
- 性能测试报告总结
性能测试环境搭建JForum
JForum 是采用 Java 开发的功能强大且稳定的论坛系统。它提供了抽象的接口、高效的论坛引擎以及易于使用的
管理界面,同时具有完全的权限控制、多语言支持(包括中文)、高性能、可自定义的用户接口、安全、支持
多数据库等等特性。
JForum 最大的优点是采用 BSD 开源协议,你可以最大限度的进行任何修改和扩展,包括商业用途。
jforum安装的前提条件
- 安装JDK
- 安装Tomcat
- 安装数据库(如:MySQL)
下载地址:https://sourceforge.net/projects/jforum/files/latest/download
"新项目"开展性能测试必要前提
- 需求分析采集
- 业务流程及架构梳理
- 圈定测试范围
- 明确性能指标
- 分析系统协议
- 选择压测工具
做好如上工作后,可以开始进行脚本开发,脚本开发时,需要根据具体的需求和业务,根据数据的业务流程,串联每个独立的接口。真正执行性能测试时还需要准备性能测试数据,测试数据可以根据工具,代码脚本,SQL插数据,存储过程等产生。性能测试的场景设计根据性能目标而定,目标是基准测试、负载测试、配置测试还是稳定性测试。
开始测试执行前还需要检查网络、数据、脚本、监控等,确保性能测试可以顺利进行,否则中途因为某些原因,没有办法进行,浪费时间,金钱,人力等
性能分析和性能调优
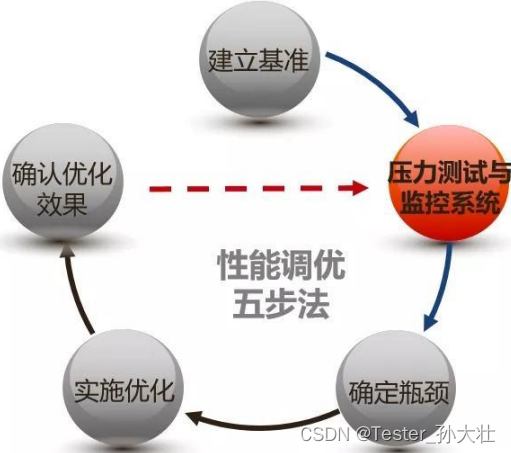
性能调优可以选择五步法,首先建立测试基准,可以使用基准性能测试,在基准测试的基础上进行压力测试,并监控系统资源指标,通过监控的数据,逐步分析确定性能瓶颈,并实施优化方案,实施优化方案后,观察优化效果,并再次进行压测与数据监控,并重复这个过程,直到达到性能目标。
在性能分析的时候,可以选择自底向上和自顶向下的方法,自底向上即从代码开始逐步分析找到性能出现瓶颈的原因,自顶向下即从业务场景出发,逐步分析网络,带宽,基础架构等,直到发现性能瓶颈。
性能分析的架构往往比较复杂,这时候从整体出发的话往往会混乱找不到性能瓶颈的节点,这时可以从单体性能分析角度出发,此时可能在单体分析过程中就发现问题,如果仍然不能确定原因,可以逐步扩展到整体架构,可以排查一些因素,并逐步分析,找到性能瓶颈的节点。在性能分析的对象包含系统资源,操作系统,DB,中间件,应用程序等
发现性能瓶颈后,可以开始进行性能调优,性能调优包含程序优化,配置优化,线程优化,DB优化等,当然系统架构的演进也是性能调优的一种手段。
容量保障&容量测试
特别像双11,双12这样的活动在这时候,系统在某一时间节点的访问量往往是平时的几倍,这时考验的是系统的性能,系统性能测试是系统稳定性建设的基石。能够在极端情况仍然可以访问,要求系统有极高的稳定性。高性能、高可用和高扩展性并加上容量规划,流量控制,灾备,监控,预案演练等五大法宝共同构成系统稳定性建设的基石。
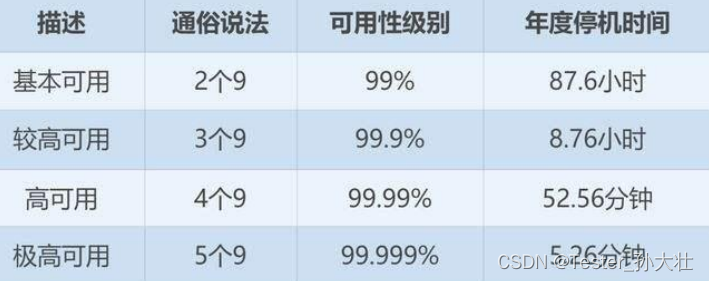
什么是系统容量
单位时间内软件系统能够承载最大的业务量是互联网的系统容量
为什么需要做容量规划
根据商业的需求。因为商业总是会增长的,并且在业务演变的过程中需要加入一些新的需求,这就需要系统可以承载重大的业务量。另外在一些特别的节日系统需要承载更多的业务量,所以系统需要进行容量规划,以便更好的扩展业务。
容量保障难点
容量保障的难点是不确定性,复杂性和不准确性,因为在进行容量规划的时候无法预期以后会发生哪些新的需求,以及客户的访问量会是怎样的变化。
容量保障目标是什么
在客户的眼中,容量保障是可以访问到,并且耗时在可接受的范围内,并且想用功能正常使用。从技术视角出发,系统可用,关键路径正常,性能在可以接受的范围内。
如何量化容量保障目标
- 用户体验
一切都是从用户出发,失去了用户,容量保障也就失去了意义。 - SLA
SLA 指的是服务级别协议,是服务提供商(如云服务提供商、IT服务提供商)和客户之间所签订的一份合同文件,规定了服务提供商为客户提供服务所承诺的服务水平和质量标准,包括服务可靠性、服务响应时间、服务可用性、服务保障等内容。通过签署 SLA,可以确保服务提供商不仅能够提供高质量的服务,而且能够对其服务质量进行监控和报告,以满足客户的业务需求和期望。
- QPS/TPS
业务上的吞吐量和接口访问量是容量保障的直接体现。
容量测试与验证
通过压力测试或容量测试验证最大容量。
容量测试该如何做
容量测试时可以从几个关键点出发:
- 主流程上的核心业务,比如支付业务、下单业务
- 对响应时间敏感的业务,比如下单业务
- 占用资源大的服务。比如 商品的服务
- 曾经发生过容量事故的服务,比如说下单业务,支付业务
- 新上线对容量情况未知的服务,比如新上线的一些新功能
实施容量测试,包含事前方案:容量测试、方案设计,容量测试方案评审、测试准备,事中盯盘:测试执行,事后分析:测试反馈。
容量测试时需要进行容量规划,容量规划包含以下几个阶段 1. 流量预估 ,2. 容量评估,3. 容量调整,4. 流量控制
容量测试也可以采用基线容量测试,基线容量测试在线下测试环境就能完成,具体的做法是,我们需要按照与线上相同的部署方式搭建这套测试环境(下称“基线环境”),包括所有的中间件和网络设施,不过资源规模可以等比例减少。
本文来自互联网用户投稿,文章观点仅代表作者本人,不代表本站立场,不承担相关法律责任。如若转载,请注明出处。 如若内容造成侵权/违法违规/事实不符,请点击【内容举报】进行投诉反馈!